3 第5章 基礎統計学復習
経営学部の1回生がおおよそ学んでいるであろう統計学の内容を、Rコードとともに復習します。 テキストの内容に加えて、コードの効率化や関数化についても解説します。
まずサイコロを作ります。 1から6の数値からなるベクトルdiceを作ります。 つぎにsample()関数を用いて、diceの中から1つの数をランダムに取り出します。
sample()関数の引数は以下の通りです。
-
x: 抽出元のベクトル -
size: 抽出する数 -
replace: 置換を許可するかどうか
同じコードを3回以上書いているなと思ったら、ループ処理や関数化を検討しましょう。 for()関数を使ったり、サイコロを投げる回数を引数にした関数を作成したりする方法があります。
をまとめて書くと、次のようになります。
[[1]]
[1] 4 4 3 2 6 3 5 2 6 5
[[2]]
[1] 3 2 6 6 5 4 6 4 3 1
[[3]]
[1] 6 1 1 5 2 1 4 5 2 2これをさらに発展させて、後で変更する可能性のある変数である試行回数やサイコロを振る回数を別に設定しておいて、コードを読みやすく、また変更しやすくします。
[1] 3.2 3.3 4.0試行回数trialsとサイコロを振る回数sample_sizesを引数にした関数を作成すると、さらに便利になります。 ここでは、自作関数dice_mean()を定義してみましょう。 デフォルト値として、試行回数を3回、サイコロを振る回数を10回に設定しています。
[1] 3.4 2.5 4.4[1] 3.15 3.55 3.65 3.50 3.25[1] 3.80 4.30 2.75 3.70 3.05この関数を使って、サイコロを10回、100回、1,000回振ったときの平均をそれぞれ3回ずつ試行してみましょう。
set.seed(352)
size = c(10, 100, 1000)
d_mean <- list()
for (i in seq_along(size)) {
d_mean[[i]] <- dice_mean(trial_count = 3, sample_sizes = size[i])
}
d_mean_mat <- do.call(rbind, d_mean)
# 列名を付与
colnames(d_mean_mat) <- paste0("試行", 1:ncol(d_mean_mat))
# 行名を付与
rownames(d_mean_mat) <- paste0("サイコロを", size, "回振る")
# 表として出力
knitr::kable(
d_mean_mat,
caption = "サイコロの標本平均(各サイズ3回ずつ)",
align = "ccc"
)| 試行1 | 試行2 | 試行3 | |
|---|---|---|---|
| サイコロを10回振る | 3.200 | 3.000 | 2.400 |
| サイコロを100回振る | 3.440 | 3.340 | 3.560 |
| サイコロを1000回振る | 3.433 | 3.446 | 3.554 |
tidyverseのpurrrパッケージを使うと、さらに簡潔に書けます。
set.seed(352)
trial_count <- 3 # 試行回数
sizes <- c(10, 100, 1000) # サイコロを振る回数
# map_dfr()でデータフレームを直接作成
d_mean_df <- map_dfr(sizes, function(n) {
# replicate()で3回繰り返し試行
results <- replicate(
trial_count,
mean(sample(dice, size = n, replace = TRUE))
)
set_names(results, paste0("試行", 1:trial_count))
})
result <- d_mean_df |>
mutate(条件 = paste0("サイコロを", sizes, "回振る")) |>
relocate(条件) # 「条件」列を一番左へ移動
# 出力
kable(
result,
caption = "サイコロの標本平均(各サイズ3回ずつ)",
align = "cccc"
)| 条件 | 試行1 | 試行2 | 試行3 |
|---|---|---|---|
| サイコロを10回振る | 3.200 | 3.000 | 2.400 |
| サイコロを100回振る | 3.440 | 3.340 | 3.560 |
| サイコロを1000回振る | 3.433 | 3.446 | 3.554 |
3.1 区間推定
いま、標準正規分布に従う母集団から抽出した無作為標本Z_1, Z_2, ..., Z_nを考えます。 標準正規分布の確率分布関数\phi(z)を用いると、次のように表せます。 P \left( -z_{\frac{\alpha}{2}} \leq \frac{\bar{Z} - \mu}{\frac{\sigma}{\sqrt{n}}} \leq z_{\frac{\alpha}{2}} \right) = 1 - \alpha
3.1.1 電球の寿命データで区間推定
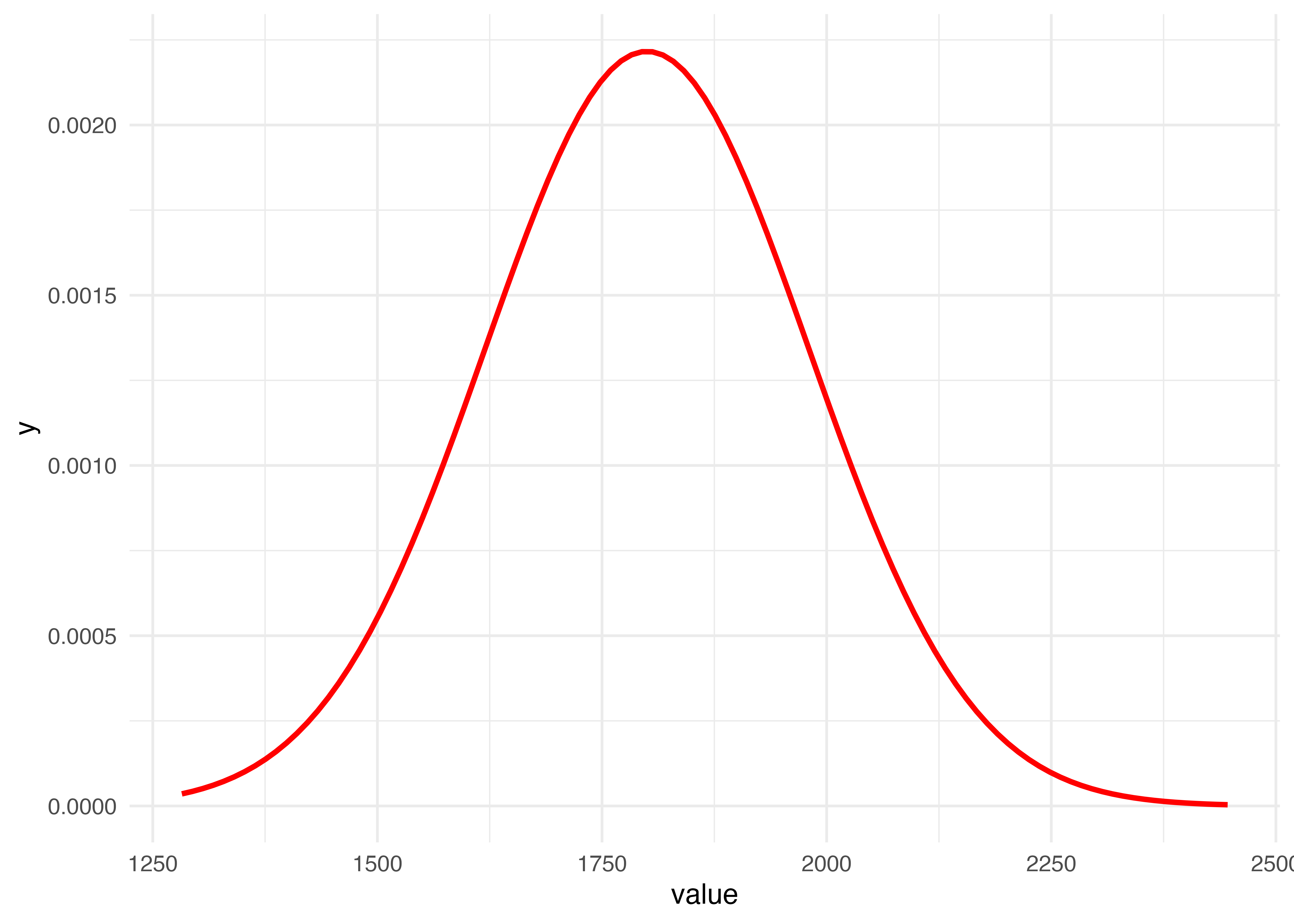
例として、次のような白熱電球の寿命データが手元にあるものとしましょう。 ここで、以下のことが分かっているものとします。
- 平均寿命が1800時間である。
- 寿命の標準偏差$$は180時間である。
- 平均寿命は正規分布に従う。
図にすると次のようになります。
この分布から抽出したと想定される16個の電球の寿命データが以下の通りです。
[1] 1951.194[1] 154.4567先ほどの分布にこのデータのヒストグラムを重ねると、次のようになります。
# ヒストグラムの作成
bulb_df <- tibble(lifetime = bulb)
bulb_df |>
ggplot(aes(x = lifetime)) +
geom_histogram(
aes(y = ..density..),
bins = 8,
fill = "lightblue",
color = "black",
alpha = 0.7
) +
stat_function(
fun = dnorm,
args = list(mean = averate, sd = standard_dev),
color = "red",
size = 1
) +
theme_minimal()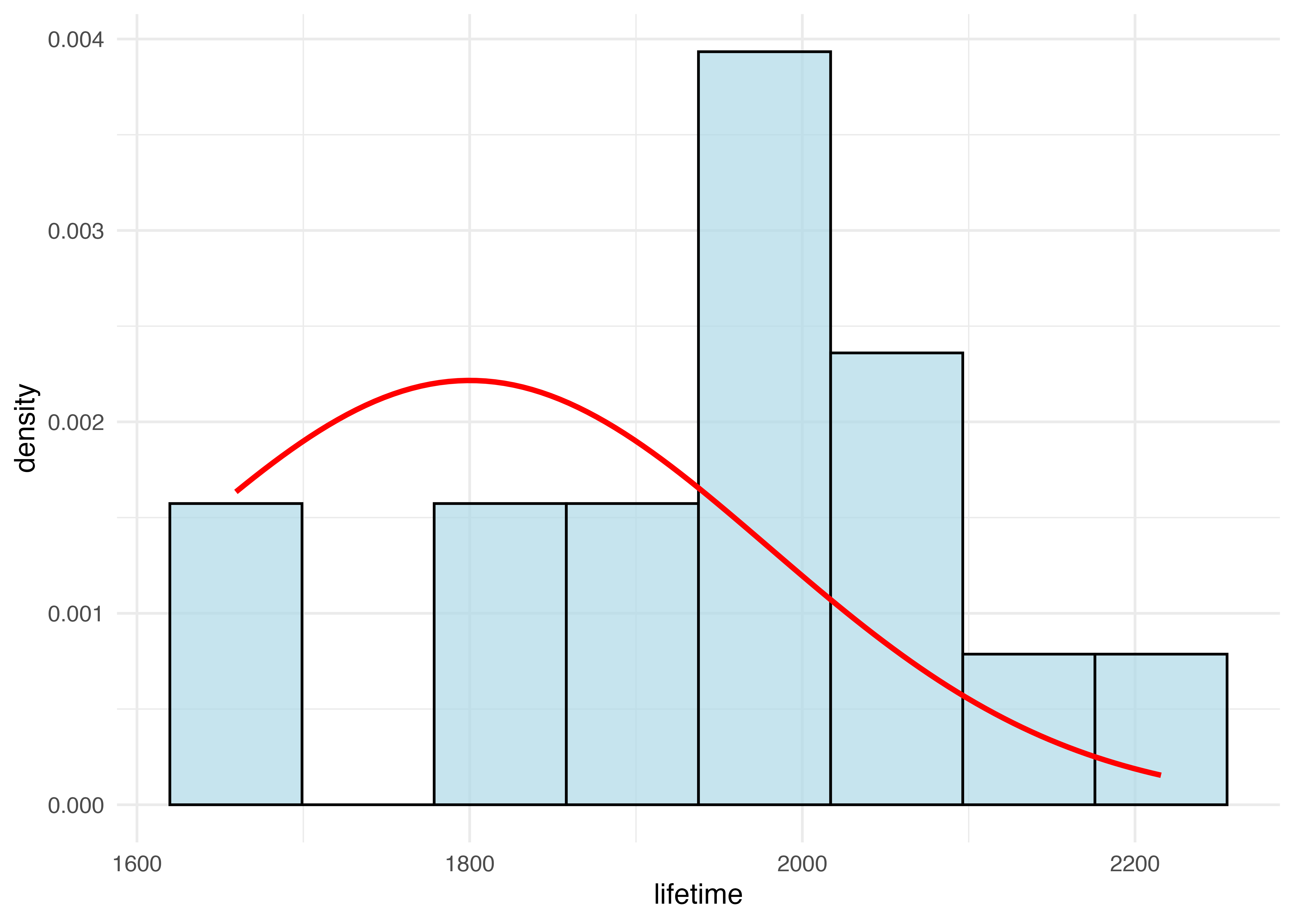
そのとき、この手元にある16個の電球の寿命データの平均値が、母平均1800の周りでどの範囲に入るかを95%の信頼水準で推定してみましょう。
[1] 1868.890 2033.498
attr(,"conf.level")
[1] 0.95# コード5-7
n <- length(bulb) # 標本サイズの計算
z <- qnorm(0.025, lower.tail = FALSE) # 上側2.5%点の分位点
xbar <- mean(bulb) # 標本平均の計算
sigma <- 180 # 母標準偏差の設定
# 信頼区間の計算
upper <- xbar + z * (sigma / sqrt(n))
lower <- xbar - z * (sigma / sqrt(n))
# 結果のまとめと出力
ci.bulb <- matrix(c(lower, upper), nrow = 1)
colnames(ci.bulb) <- c("ci.lower", "ci.upper")
knitr::kable(
ci.bulb,
caption = "Bulb data CI (95%)",
align = "cc"
)| ci.lower | ci.upper |
|---|---|
| 1862.995 | 2039.392 |
[1] 1951.194
One Sample t-test
data: bulb
t = 3.9155, df = 15, p-value = 0.001377
alternative hypothesis: true mean is not equal to 1800
95 percent confidence interval:
1868.890 2033.498
sample estimates:
mean of x
1951.194 [1] 3.359861
Welch Two Sample t-test
data: sales by ad_dummy
t = -3.3989, df = 85.686, p-value = 0.001029
alternative hypothesis: true difference in means between group 0 and group 1 is not equal to 0
95 percent confidence interval:
-1674283.1 -438496.1
sample estimates:
mean in group 0 mean in group 1
725009.7 1781399.3
F test to compare two variances
data: sales by ad_dummy
F = 0.10863, num df = 74, denom df = 71, p-value < 2.2e-16
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.06821636 0.17258882
sample estimates:
ratio of variances
0.1086276
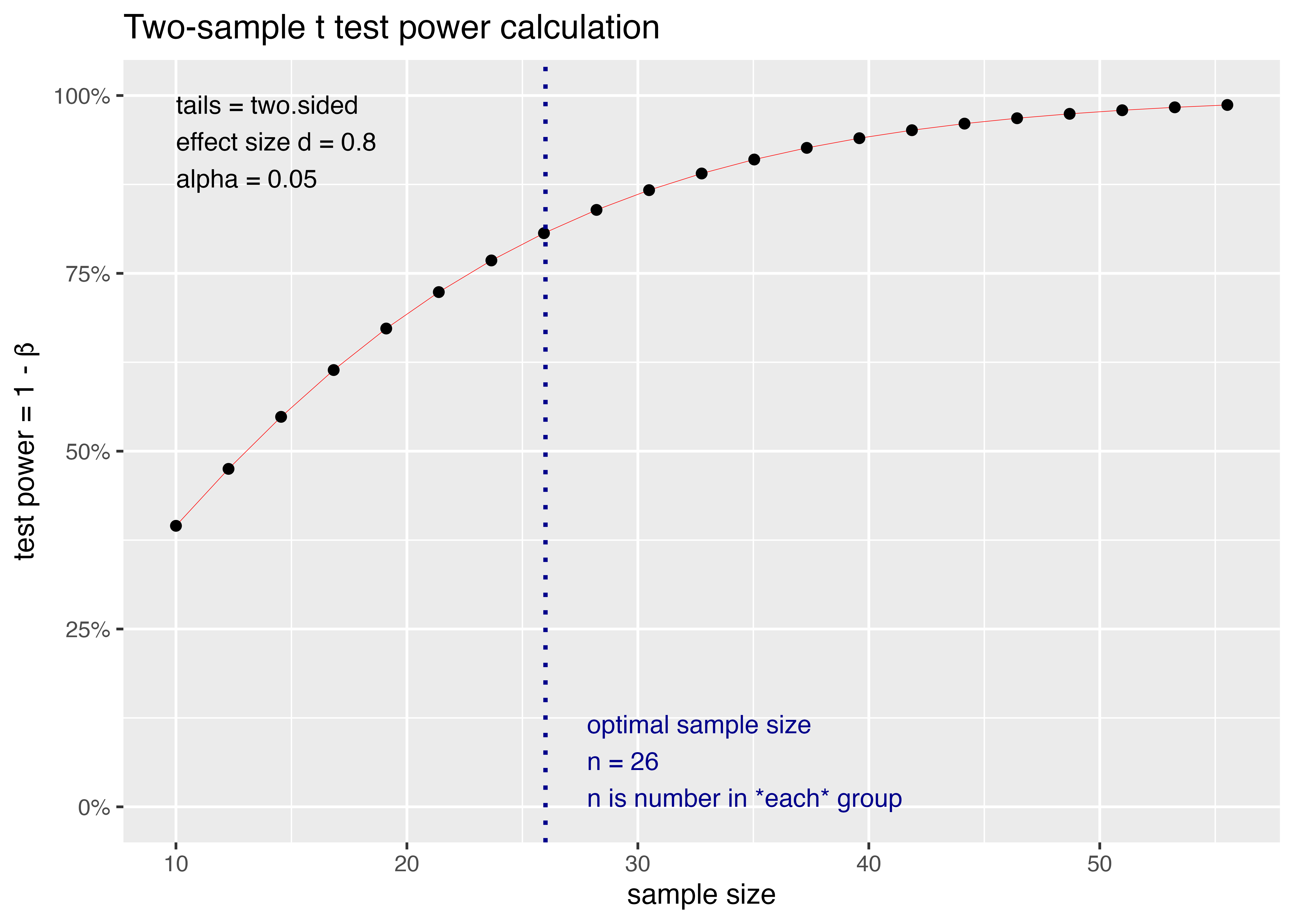
Two-sample t test power calculation
n = 25.52458
d = 0.8
sig.level = 0.05
power = 0.8
alternative = two.sided
NOTE: n is number in *each* group