df <- read.csv("data/chap2.csv", header = TRUE)2日目: 記述統計と基本グラフ
データの山をただ眺めていても,なかなかその中から変数の特徴をつかむことは難しいです。 そこで本章では,データを代表する値(代表値)として,平均や分散,標準偏差,中央値などを計算し,データの特徴をつかむことから始めます。
読み込みと記述統計
まずはcsvファイルを読み込みます。 csvファイルの読み込みは,基本関数read.csv()を用います。
ある条件を満たす行を抽出したい場合は,subset()を用いいます。 subset()関数はsubset(データ, 条件式)のように書くことで,条件を満たす行をデータから抽出できます。 ここでは、基本関数subset()を用いてB国(nationが2)のデータを取り出してみましょう。
df_B <- subset(df, nation==2)つぎに,as.factor()を使い,カテゴリー変数genderを因子型に変換します。
df_B$gender <- as.factor(df_B$gender)B国のデータだけを取り出せたので,B国の所得と性別の記述統計量を求めてみましょう。
グラフ
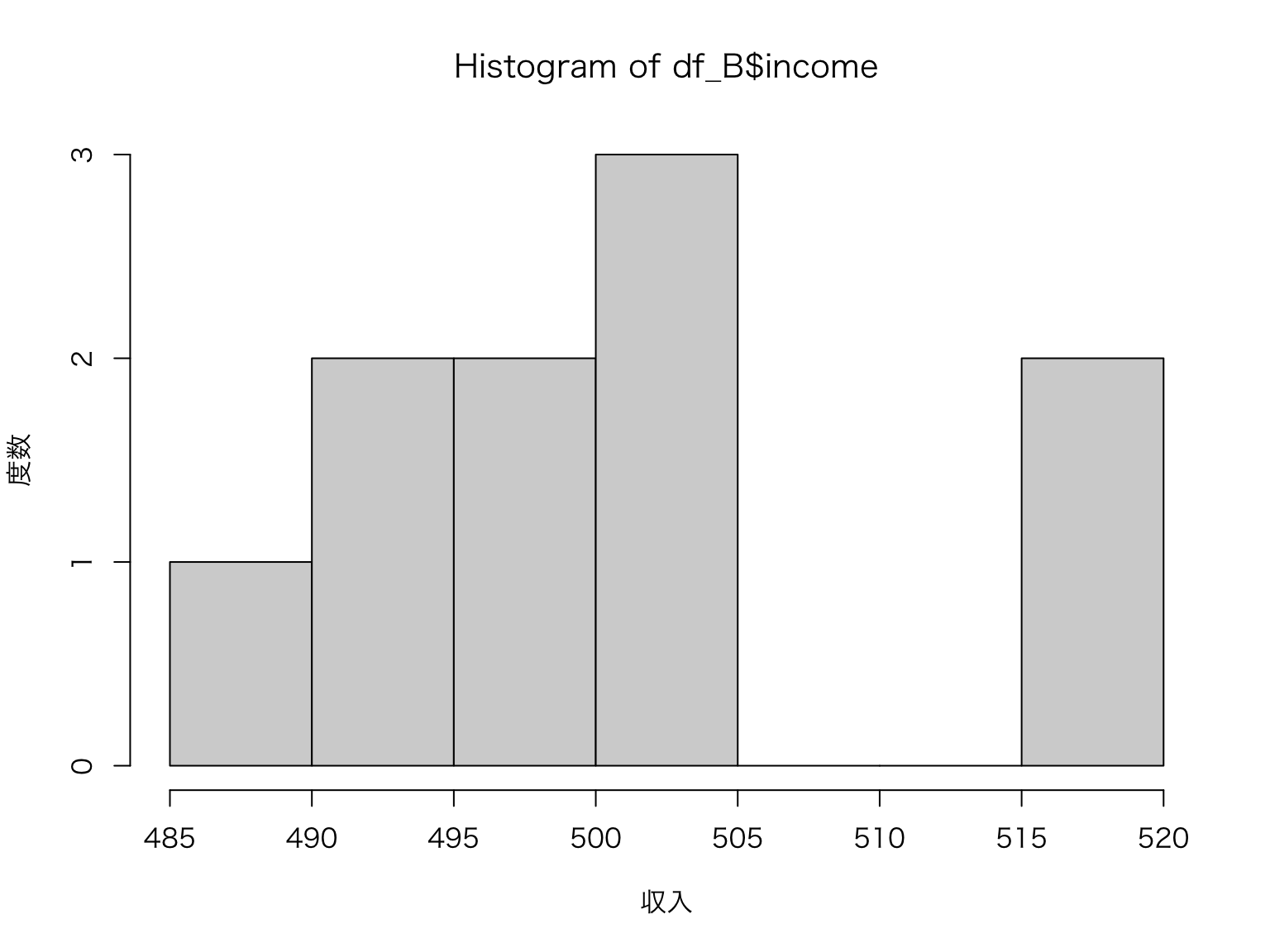
次に、B国の収入の分布を知るために,ヒストグラム(histogram)を作成してみます。 基本関数hist()は引数に1次元の数値ベクトルをとり,ヒストグラムを作成します。
ヒストグラムはhist()
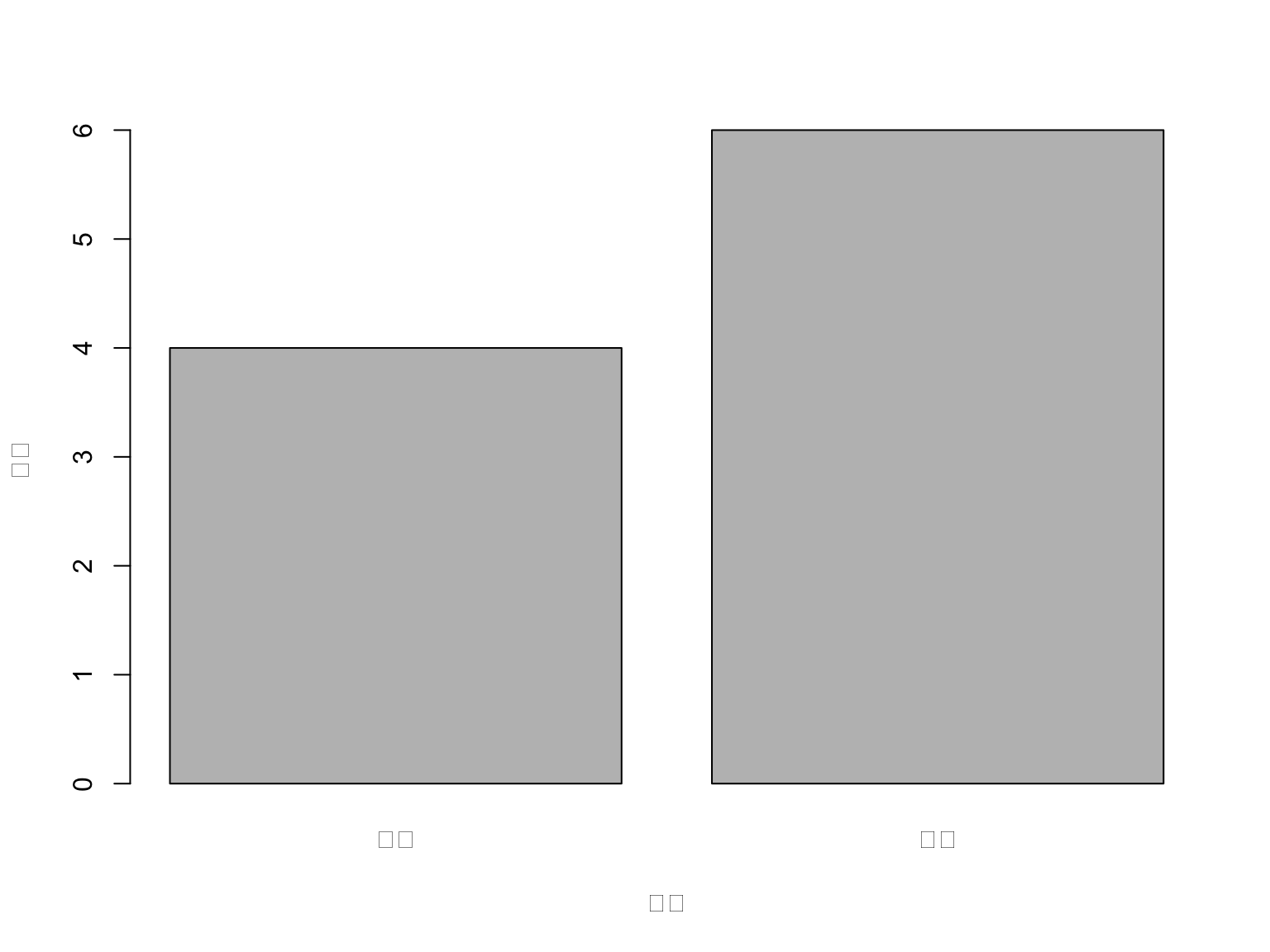
性別の度数分布を表す棒グラフを、基本関数barplot()を用いて作成します。
ヒストグラムはbarplot()
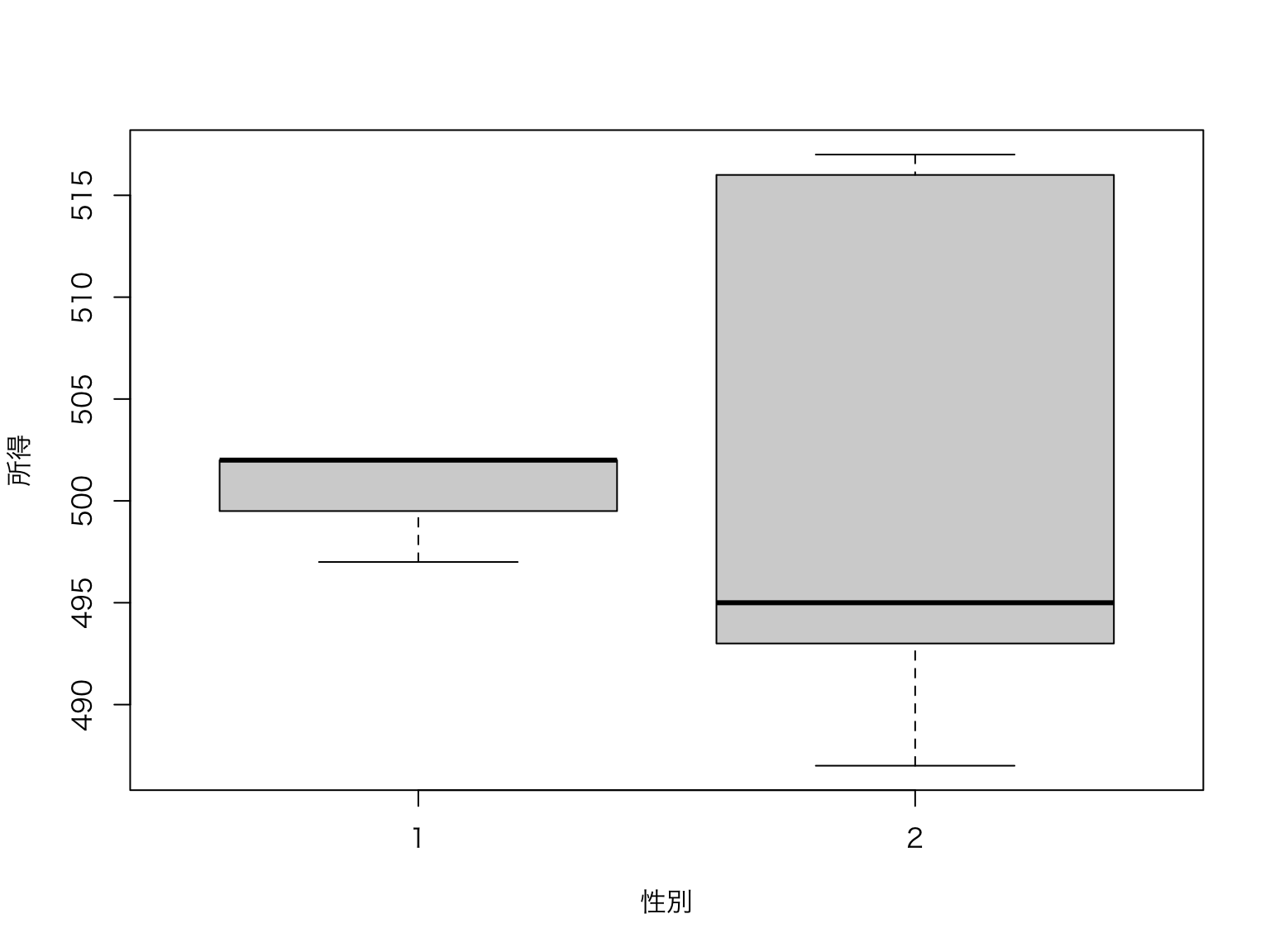
次に、男女別の所得分布を表す箱ひげ図(box plot)を作成します。 箱ひげ図は、データの分布を視覚的に表現するためのグラフで、中央値や四分位数、外れ値などを示します。 箱ひげ図は基本関数boxplot()を用いて作成します。
箱ひげ図はboxplot()
tidyverseで再実行
ここまで基本関数を用いて、データの読み込みや、データの抽出・加工、グラフの作成をしてきましたが、以下では、よりモダンな記述方法であるtidyverseを用いて同じことを行います。 tidyverseはデータの整形や可視化を行うためのパッケージ群で、データ分析を行う上で非常に便利です。
まずはtidyverseパッケージをインストールし、読み込みます。 ここでは、パッケージのインストールと読み込みを一度に実行してくれるpacmanパッケージのp_load()関数を用いています。
pacman::p_load(tidyverse)tidyverseパッケージ群の1つであるreadrパッケージのread_csv()関数でcsvファイルを読み込みます。 read_csv()のオプションcol_typesを使うことで、各列の型を指定できます。 1行目は整数i,2と3行目はファクターfを指定して読み込みます。
df <- read_csv(
"data/chap2.csv",
col_types = "iff"
)次にdplyrパッケージのfilter()関数を用いてB国のデータを取り出しつつ,select()関数で必要な変数だけを選び,summary()で記述統計量を計算します。 このように複数の処理を順番に行う場合には、|>演算子を用いて、パイプラインを作成します。 |>演算子は、左側の結果を右側の関数の第1引数に渡すことができます。
income gender
Min. :487.0 1:4
1st Qu.:494.5 2:6
Median :499.5
Mean :500.6
3rd Qu.:502.0
Max. :517.0 tidyverseパッケージ群のなかの強力な作図パッケージggplot2を用いてB国の収入のヒストグラムを書いてみましょう。
df_BB <- df |>
filter(nation == 2) |> # B国のデータだけを抽出
select(income,gender) # incomeとgenderの変数
ggplot(df_BB) +
aes(x = income) + # 所得をx軸に
geom_histogram(
binwidth = 5,
breaks = seq(485, 520, by=5),
colour="darkgreen",
fill="skyblue"
) + theme_bw()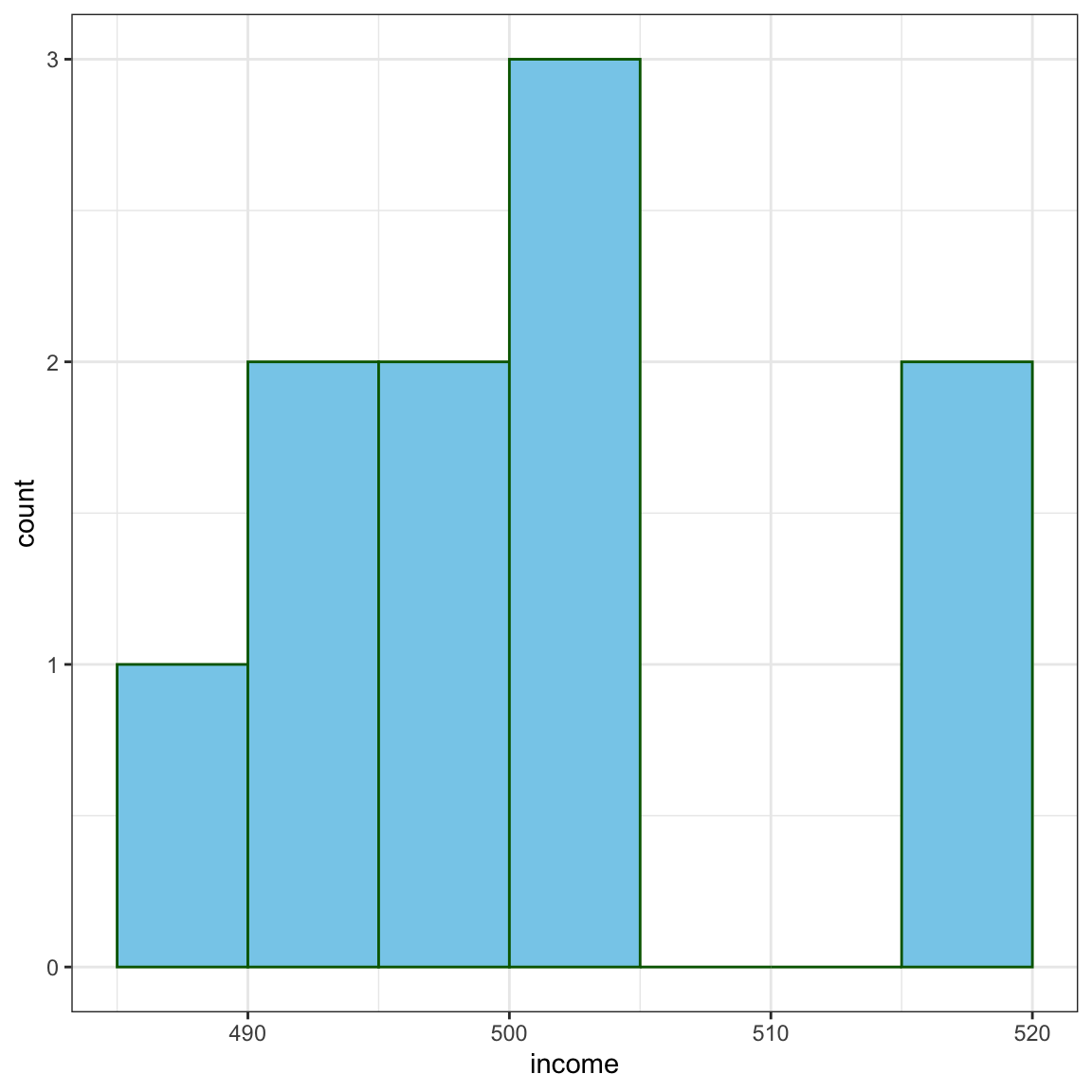
性別の度数分布の棒グラフ
ggplot(data = df_BB) +
aes(gender) +
geom_bar(
colour = "darkgreen",
fill = "skyblue") +
theme_bw()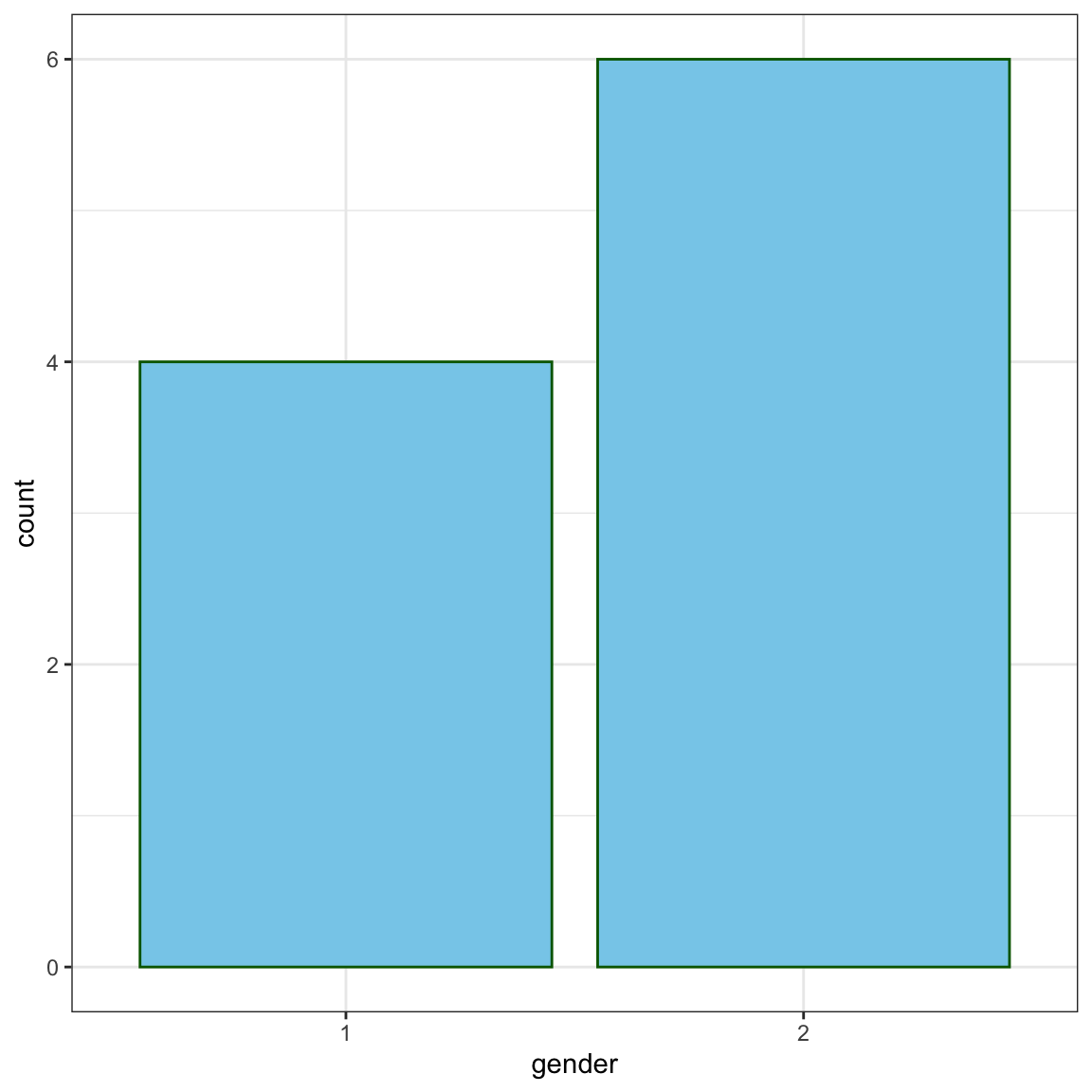
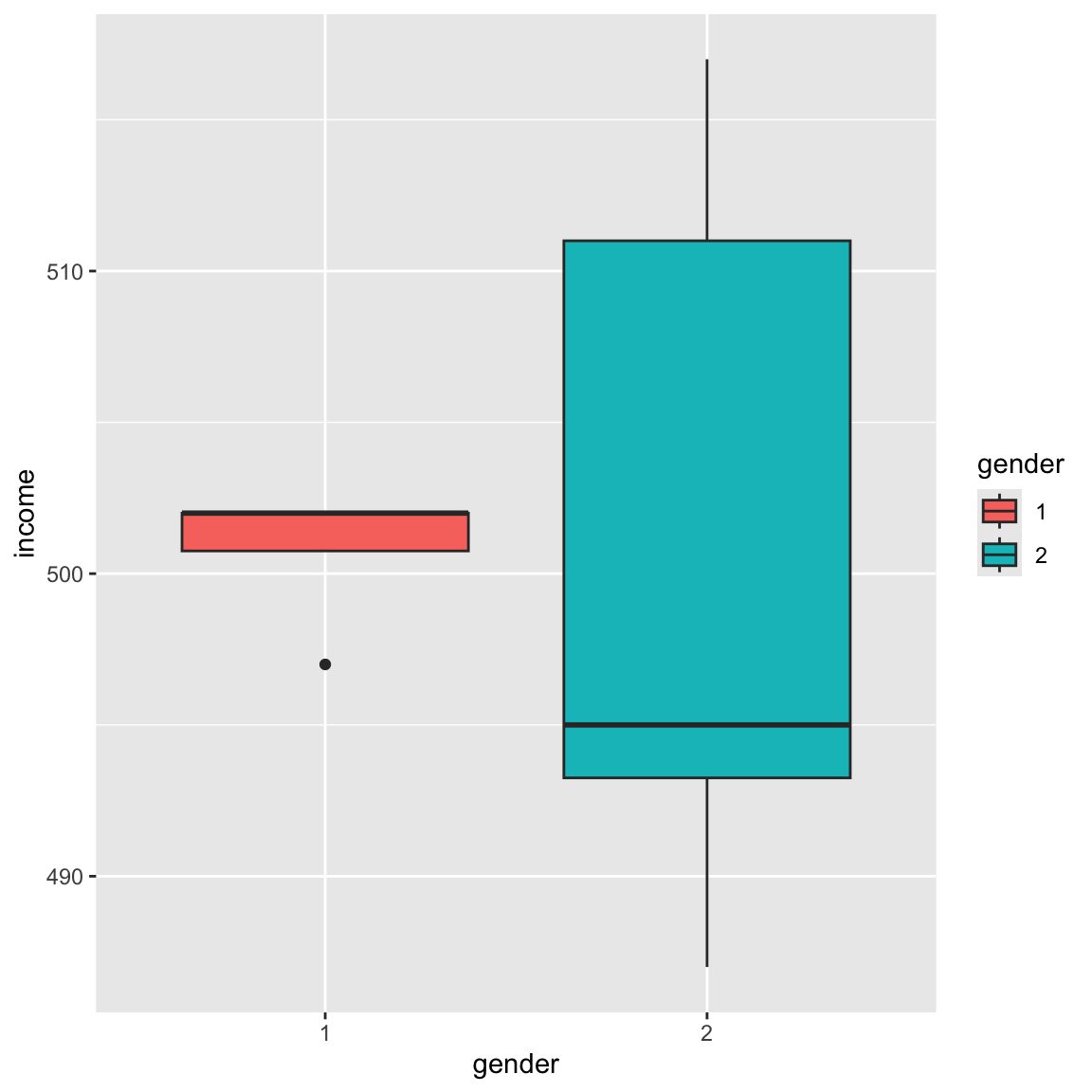
男女別の所得分布を表す箱ひげ図
ggplot(df_BB) +
aes(y = income, x = gender) +
geom_boxplot(aes(fill = gender))