6 ファクターモデルの導入
6.1 ファクター構築の準備
- CAPMの実証的検証に必要な市場ポートフォリオの構築
- ある特徴に基づいて各銘柄をランキングにし,ランキングに応じたポートフォリオの構築
6.2 市場ポートフォリオの構築
市場ポートフォリオ(market portfolio)とは,市場に存在する全ての危険資産を時価総額比率で保有したポートフォリオをいいます。
厳密には,リスク資産には株式や債券に代表される金融資産の他、不動産や貴金属などの実物資産も含まれますが、実用上はTOPIXやS&P500といった株価指数と同一視されることが多いです。
入手可能な全銘柄の前年末時価総額\sum ME_{j,t-1}と個別銘柄の時価総額 ME_{i,t-1} の比率をウェイト w_{i,t}^M として市場ポートフォリオを構築します。
w_{i,t}^M = \frac{ME_{i,t-1}^{12\text{月}}}{\sum_{j = 1}^N ME_{j,t-1}^{12\text{月}}}
株価は日々変動するため、時価総額も変動します。 そのため、毎年1月に時価の変動で崩れた比率をリセットするために、市場ポートフォリオの中身を入れ替えるリバランスを行います。
では練習用データで市場ポートフォリオを構築してみましょう。
monthly_dataは月次の株式データが収録されており、 annual_dataは年次の財務データが収録されています。 データの構造を確認しておきます。
Rows: 95,040
Columns: 24
$ year <dbl> 2015, 2015, 2015, 2015, 2015, 2015, 2015, 2015, 2015, 2015…
$ month <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 1, 2, 3, 4, 5, 6, 7…
$ month_ID <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,…
$ firm_ID <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ stock_price <dbl> 954, 960, 1113, 1081, 1317, 1366, 1353, 1209, 1291, 1407, …
$ DPS <dbl> 0, 0, 0, 0, 0, 29, 0, 0, 0, 0, 0, 29, 0, 0, 0, 0, 0, 40, 0…
$ n_shares <dbl> 2422000, 2422000, 2422000, 2422000, 2422000, 2422000, 2422…
$ adj_coef <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ R_F <dbl> 6.506826e-04, 5.834099e-04, 6.114423e-04, 6.848180e-04, 7.…
$ ME <dbl> 2310588000, 2325120000, 2695686000, 2618182000, 3189774000…
$ R <dbl> NA, 0.006289308, 0.159375000, -0.028751123, 0.218316374, 0…
$ Re <dbl> NA, 0.005705898, 0.158763558, -0.029435941, 0.217579602, 0…
$ industry_ID <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 1, 1, 1, 1…
$ sales <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 5948.96, 5…
$ OX <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 564.14, 56…
$ NFE <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 50.66750, …
$ X <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 513.48, 51…
$ OA <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 13865.58, …
$ FA <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 4642.16, 4…
$ OL <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 4534.22, 4…
$ FO <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 3959.70, 3…
$ BE <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 10013.82, …
$ lagged_BE <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
$ ROE <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…Rows: 7,920
Columns: 20
$ year <dbl> 2015, 2016, 2017, 2018, 2019, 2020, 2015, 2016, 2017, 2018…
$ firm_ID <dbl> 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 4, 4…
$ ME <dbl> 3577.294, 6883.324, 11376.990, 8694.752, 13957.518, 9708.9…
$ annual_R <dbl> NA, 0.99727265, 0.68786382, -0.21361287, 0.64683576, -0.28…
$ annual_R_F <dbl> 7.432089e-03, 5.649890e-04, 4.884804e-05, 5.786109e-03, -7…
$ annual_Re <dbl> NA, 0.99670766, 0.68781497, -0.21939898, 0.64760569, -0.28…
$ industry_ID <dbl> NA, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, …
$ sales <dbl> NA, 5948.96, 6505.06, 6846.38, 7572.24, 7537.63, 3505.75, …
$ OX <dbl> NA, 564.14, 691.18, 751.29, 958.53, 778.37, 45.82, 51.25, …
$ NFE <dbl> NA, 50.667498, 29.543157, 86.486500, 298.049774, -65.45877…
$ X <dbl> NA, 513.48, 661.64, 664.80, 660.48, 843.83, 40.07, 49.37, …
$ OA <dbl> NA, 13865.58, 13952.58, 18818.48, 18190.00, 20462.86, 2977…
$ FA <dbl> NA, 4642.16, 7743.99, 7284.72, 9735.13, 10274.25, 2258.33,…
$ OL <dbl> NA, 4534.22, 5111.22, 5137.28, 5487.96, 5371.38, 1840.35, …
$ FO <dbl> NA, 3959.70, 6159.02, 10123.91, 11362.22, 13772.15, 2340.8…
$ BE <dbl> NA, 10013.82, 10426.33, 10842.01, 11074.95, 11593.58, 1054…
$ lagged_BE <dbl> NA, NA, 10013.82, 10426.33, 10842.01, 11074.95, NA, 1054.9…
$ ROE <dbl> NA, NA, 0.06607269, 0.06376165, 0.06091859, 0.07619267, NA…
$ lag_ME <dbl> NA, 3577.294, 6883.324, 11376.990, 8694.752, 13957.518, NA…
$ lagged_BEME <dbl> NA, NA, 1.4547942, 0.9164401, 1.2469602, 0.7934756, NA, 0.…この銘柄ごとの保有比率を計算するために,前年度末の時価総額を計算し,lagged_MEに代入します。 annual_dataは2015年から2020年のデータが入っています。 lag()で前期末の時価総額をlagged_MEに代入しようとしても2015年の前年のデータは存在しないので,欠損値になることに注意しましょう。
この処理の結果がおおよそこんな感じになっているはずです。
| firm_ID | year | ME | lagged_ME |
|---|---|---|---|
| 1 | 2015 | 3577.294 | NA |
| 1 | 2016 | 6883.324 | 3577.294 |
| 1 | 2017 | 11376.990 | 6883.324 |
このlagged_MEを使って保有比率を計算します。 年度ごとに時価総額を合計し、ある企業の前期末時価総額を合計時価総額で割ることで保有比率w_Mを計算します。
2015年のlagged_MEは欠損値なので,w_Mも欠損値になっていますが,2015年のデータはもう使わないので無視します。
次に,2016年以降の欠損値の行を削除するのではなく,保有比率w_Mをゼロに置き換えることで投資しないことを表します。 mutate()とreplace()を用いて変数の置き換えをします。
この処理は、
-
annual_dataにannual_dataを代入し直す -
mutate()関数で変数を変換する -
replace()関数でw_Mの値を置き換える
replace()関数は,第1引数のデータに対して,第2引数の条件を満たす要素を,第3引数の値に置き換えます。 ここでは,w_Mに対して,yearが2016以上で,かつw_Mが欠損値の場合のw_Mを0に置き換えています。
作成した保有比率を表すウェイトw_Mの合計が1になっているかどうかを確認します。
# A tibble: 6 × 2
year weight_sum
<dbl> <dbl>
1 2015 NA
2 2016 1
3 2017 1
4 2018 1
5 2019 1
6 2020 1確認できました。 これまでの操作で変数を追加したannual_dataにmonthly_dataに結合します。 完全外部結合(full outer join)を行います。 完全外部結合とは,データベースを連結する操作の1つで、2つのデータフレームからそれぞれ特定のキーとなる列を指定して,キーの値が一致する行同士は連結し、一致しない残りの行もそのまますべて抽出するものです。
ではfull_join()関数を使って,annual_dataとmonthly_dataをyearとfirm_IDの2つのキーで結合し,その結果をmonthly_dataに代入します。
できあがった拡大データセットmonthly_dataを確認します。
Rows: 95,040
Columns: 25
$ year <dbl> 2015, 2015, 2015, 2015, 2015, 2015, 2015, 2015, 2015, 2015…
$ firm_ID <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ month <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 1, 2, 3, 4, 5, 6, 7…
$ month_ID <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,…
$ stock_price <dbl> 954, 960, 1113, 1081, 1317, 1366, 1353, 1209, 1291, 1407, …
$ DPS <dbl> 0, 0, 0, 0, 0, 29, 0, 0, 0, 0, 0, 29, 0, 0, 0, 0, 0, 40, 0…
$ n_shares <dbl> 2422000, 2422000, 2422000, 2422000, 2422000, 2422000, 2422…
$ adj_coef <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ R_F <dbl> 6.506826e-04, 5.834099e-04, 6.114423e-04, 6.848180e-04, 7.…
$ ME <dbl> 2310588000, 2325120000, 2695686000, 2618182000, 3189774000…
$ R <dbl> NA, 0.006289308, 0.159375000, -0.028751123, 0.218316374, 0…
$ Re <dbl> NA, 0.005705898, 0.158763558, -0.029435941, 0.217579602, 0…
$ industry_ID <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 1, 1, 1, 1…
$ sales <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 5948.96, 5…
$ OX <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 564.14, 56…
$ NFE <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 50.66750, …
$ X <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 513.48, 51…
$ OA <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 13865.58, …
$ FA <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 4642.16, 4…
$ OL <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 4534.22, 4…
$ FO <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 3959.70, 3…
$ BE <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 10013.82, …
$ lagged_BE <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
$ ROE <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
$ w_M <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, 2.233661e-…準備が整ったので,市場ポートフォリオの月次リターンを計算します。 t時点における市場ポートフォリオのリターンR_{M,t}は、個別銘柄のリターンR_{i,t}とウェイトw_{i,t}^Mの積の合計で表されます。
R_{M,t} = \sum_{i=1}^{N} w_{i,t}^M R_{i,t}
これをRで実装します。 monthly_dataをmonth_IDでグループ化し,summarise()関数を用いて,R_Mを計算し,その後でmutate()関数を用いて,R_Meを計算し,その結果をfactor_dataに代入します。
factor_dataの中身をsummary()で確認します。
month_ID R_F R_M R_Me
Min. :13.00 Min. :-2.329e-04 Min. :-0.102438 Min. :-0.102438
1st Qu.:27.75 1st Qu.:-4.107e-05 1st Qu.:-0.011056 1st Qu.:-0.010890
Median :42.50 Median : 3.870e-05 Median : 0.006081 Median : 0.006186
Mean :42.50 Mean : 9.991e-05 Mean : 0.004100 Mean : 0.004000
3rd Qu.:57.25 3rd Qu.: 1.323e-04 3rd Qu.: 0.031698 3rd Qu.: 0.031649
Max. :72.00 Max. : 6.326e-04 Max. : 0.111043 Max. : 0.110819 作成した市場ポートフォリオの超過リターンをヒストグラムにして分布を確認します。
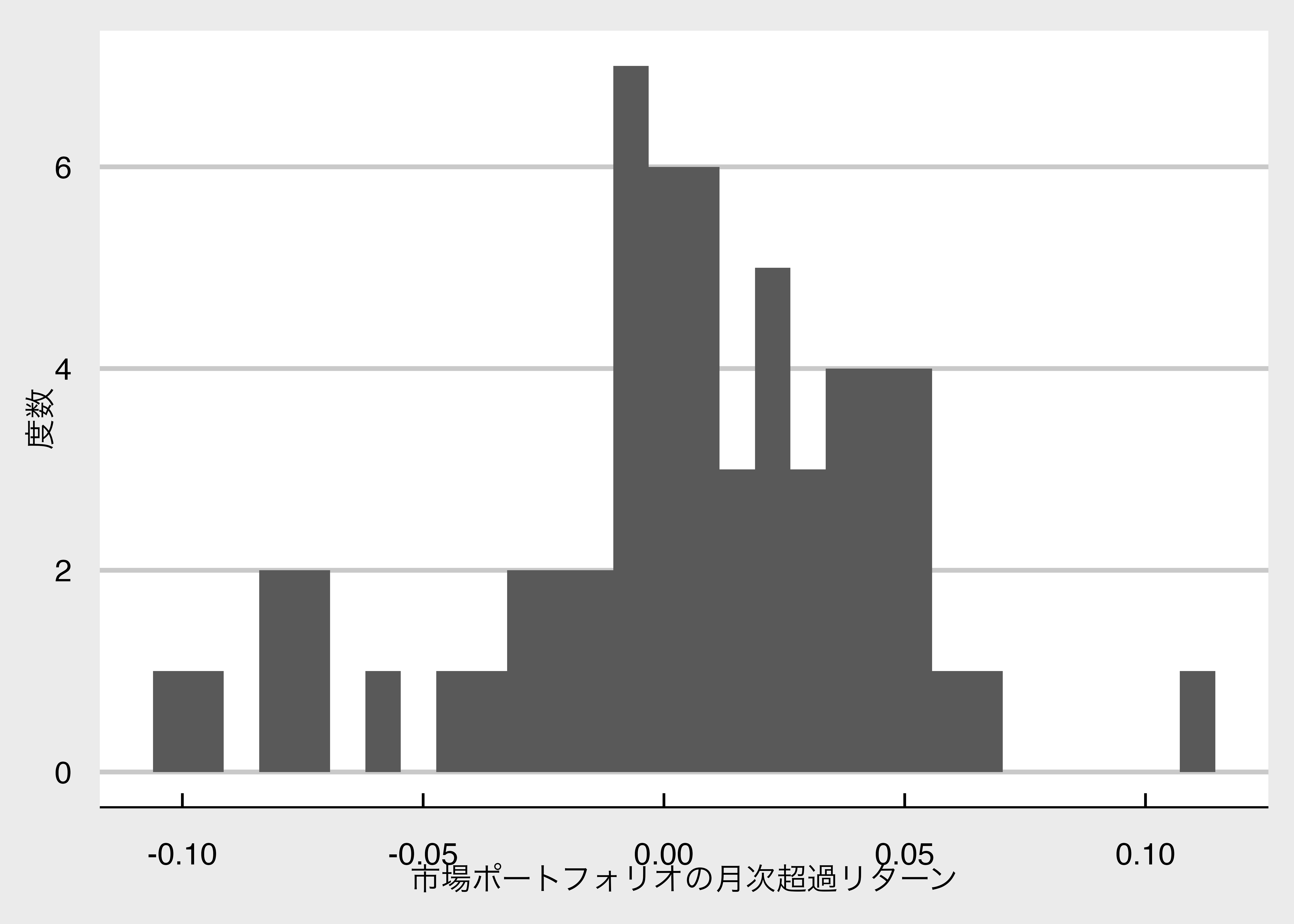
次に、市場ポートフォリオの累積リターンを計算します。 計算の仮定は以下の通りです。
-
month_IDが13の月初から運用スタートし、バイアンドホールドで運用すると仮定する。 - 毎年1月にコストなしでリバランスし、リバランス前後で元本の変動はないと仮定する。
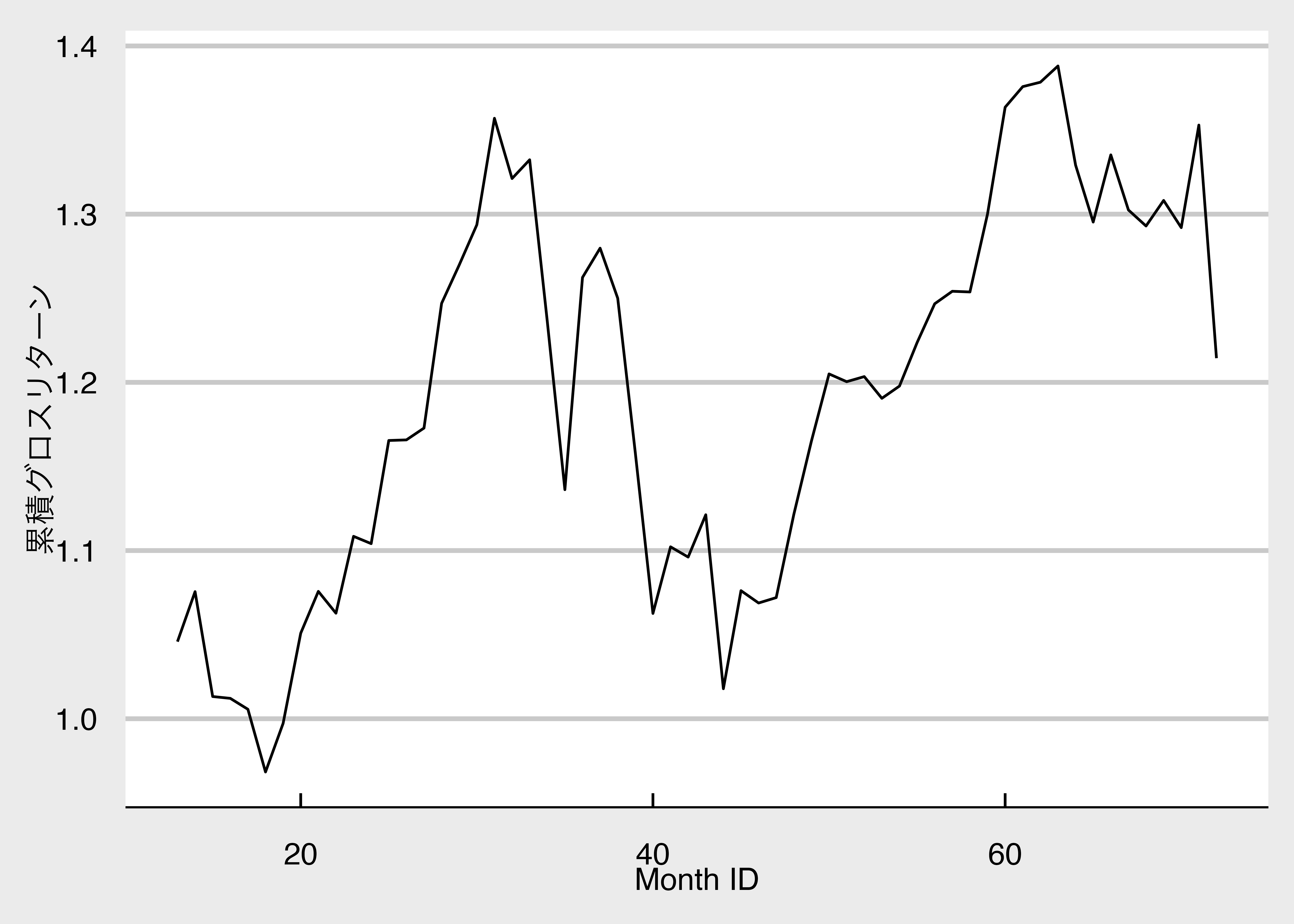
市場ポートフォリオの累積グロス・リターンを計算します。
作成した累積グロス・リターンを折れ線グラフで可視化します。
累積リターンであることが一発で分かるように、始点を1として、折れ線グラフを描き直します。 rbind()で始点となるデータを追加し、geom_hline()で始点の水準を点線で図示します。
市場ポートフォリオの累積リターンの可視化 (2)
df_g <- factor_data |>
mutate(
gross_R_M = 1 + R_M,
cumulative_gross_R_M = cumprod(gross_R_M)
) |>
select(month_ID, cumulative_gross_R_M) |>
add_row(month_ID = 12, cumulative_gross_R_M = 1, .before = 1)
# 折れ線グラフを作成
g <- ggplot(df_g) +
geom_line(aes(x = month_ID, y = cumulative_gross_R_M)) +
geom_hline(yintercept = 1, linetype = "dotted", color = "red") + # 元本の水準を点線で図示
labs(x = "Month ID", y = "Cumulative Gross Return") +
scale_x_continuous(expand = c(0, 0)) + ylim(0.5,1.5) + mystyle
print(g)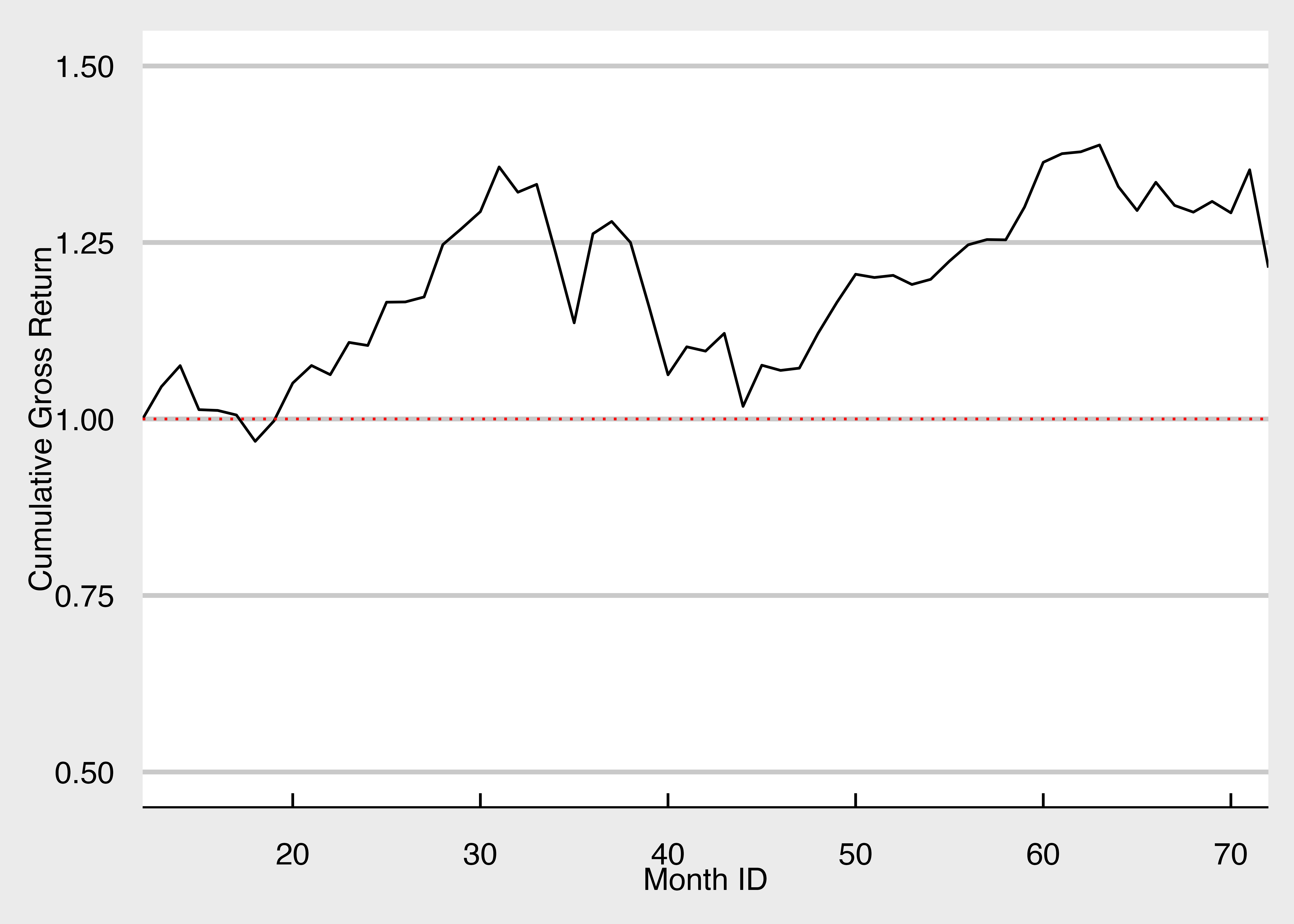
6.3 ポートフォリオ・ソート
ある特性に基づいて株式銘柄をランキングにし、そのランキングに基づいてポートフォリオを構築することをポートフォリオ・ソートと呼びます。 ポートフォリオ・ソートは、ファクター・モデルの検証において重要な手法です。 ここでは前年度末の時価総額に基づいて、企業を10個のグループに分類して、実現リターンの比較をしてみましょう。
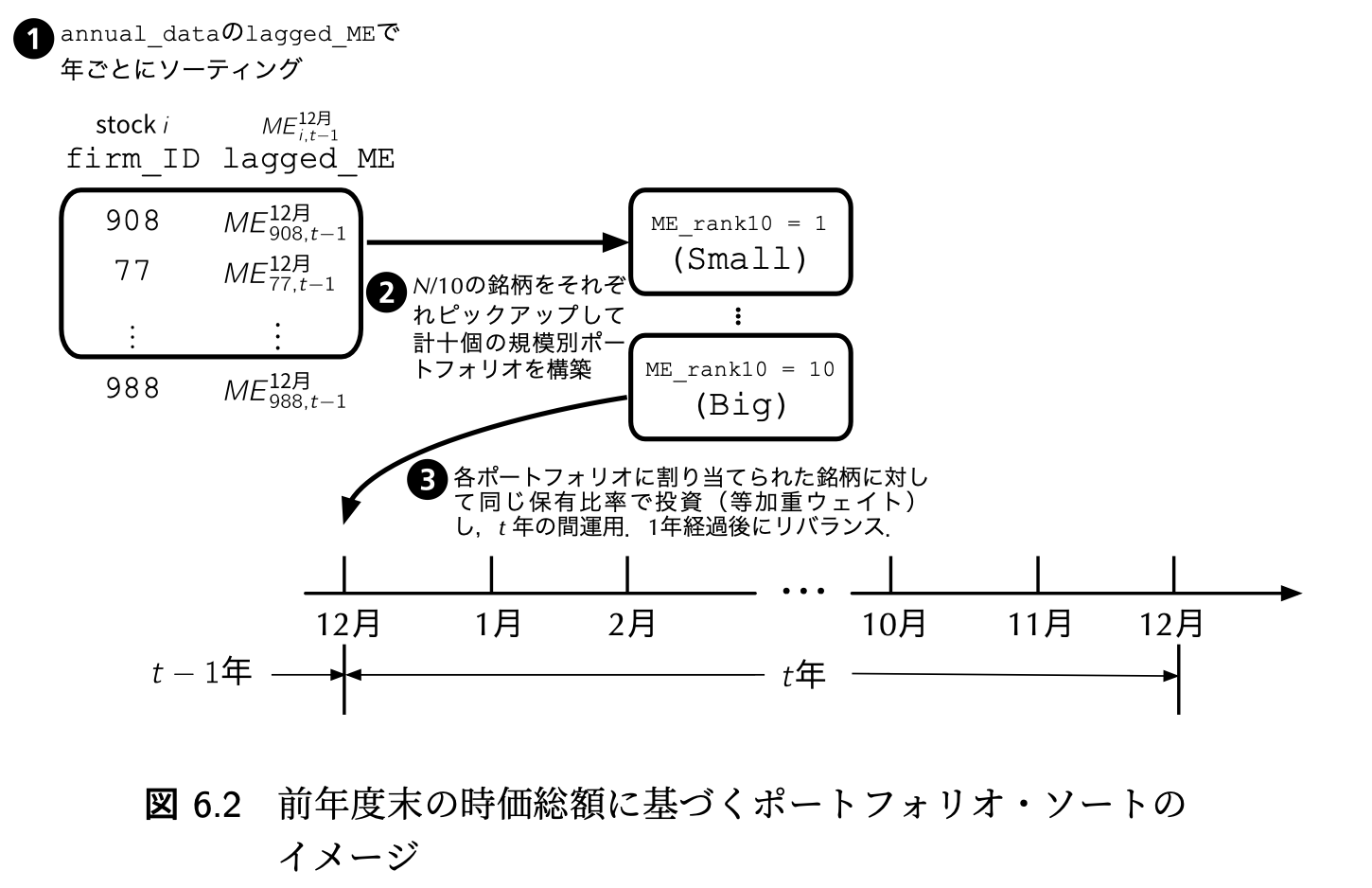
Rで時価総額ランキングを作成するには、ntile()関数を用います。 ntile()関数は、データを指定した数のグループに分類します。 以下のコードでは、mutate()関数でME_rank10を新たに作成しています。 ME_rank10は、lagged_ME変数をntile()関数で10個に分類し、as.factor()関数で因子型に変換したものです。
# A tibble: 6 × 23
year firm_ID ME annual_R annual_R_F annual_Re industry_ID sales OX
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2015 1 3577. NA 0.00743 NA NA NA NA
2 2016 1 6883. 0.997 0.000565 0.997 1 5949. 564.
3 2017 1 11377. 0.688 0.0000488 0.688 1 6505. 691.
4 2018 1 8695. -0.214 0.00579 -0.219 1 6846. 751.
5 2019 1 13958. 0.647 -0.000770 0.648 1 7572. 959.
6 2020 1 9709. -0.284 0.000380 -0.285 1 7538. 778.
# ℹ 14 more variables: NFE <dbl>, X <dbl>, OA <dbl>, FA <dbl>, OL <dbl>,
# FO <dbl>, BE <dbl>, lagged_BE <dbl>, ROE <dbl>, lag_ME <dbl>,
# lagged_BEME <dbl>, lagged_ME <dbl>, w_M <dbl>, ME_rank10 <fct>ME_rank10の値と、年・ランキングごとの会社数を確認してみましょう。
1 2 3 4 5 6 7 8 9 10 NA's
643 642 641 641 640 640 640 640 639 639 1515
1 2 3 4 5 6 7 8 9 10
2015 0 0 0 0 0 0 0 0 0 0
2016 125 124 124 124 124 124 124 124 124 124
2017 127 127 127 127 127 127 127 127 127 127
2018 127 127 127 127 127 127 127 127 126 126
2019 131 131 131 131 130 130 130 130 130 130
2020 133 133 132 132 132 132 132 132 132 132ここでは、ME_rank10の値が10の企業が時価総額ランキングの上位10%に、1の企業が時価総額ランキングの下位10%に属することを意味します。
前回と同様に、full_join()関数でmonthly_dataとannual_dataを結合します。 drop_na()関数で欠損行を削除し、.by =month_IDとME_rank10に関してグループ化した上で、summarize()関数で月次超過リターンReの平均値を計算して、Re変数としています。
前年度末の時価総額に基づくポートフォリオ・ソート
# A tibble: 600 × 3
month_ID ME_rank10 Re
<dbl> <fct> <dbl>
1 25 2 0.0976
2 26 2 0.00392
3 27 2 0.0172
4 28 2 0.0773
5 29 2 0.00948
6 30 2 0.0473
7 31 2 0.0313
8 32 2 0.0136
9 33 2 0.00911
10 34 2 -0.0962
# ℹ 590 more rows準備が出来たので、各ポートフォリオの平均超過リターンを可視化してみましょう。 これにより、時価総額の大きい企業のポートフォリオが、時価総額の小さい企業のポートフォリオよりも高い、あるいは低いリターンを上げているかどうかを確認することができます。
各ポートフォリオの平均超過リターンを可視化
ME_cross_sectional_return <- ME_sorted_portfolio |>
summarize(
mean_Re = mean(Re),
.by = ME_rank10
) # 月次超過リターンの平均値を計算
g <- ggplot(ME_cross_sectional_return) +
aes(x = ME_rank10, y = mean_Re) +
geom_col() + # 棒グラフ
xlab("時価総額ランク") + ylab("平均月次超過リターン") +
scale_y_continuous(expand = c(0, 0)) +
ylim(0,0.02) + mystyle
print(g)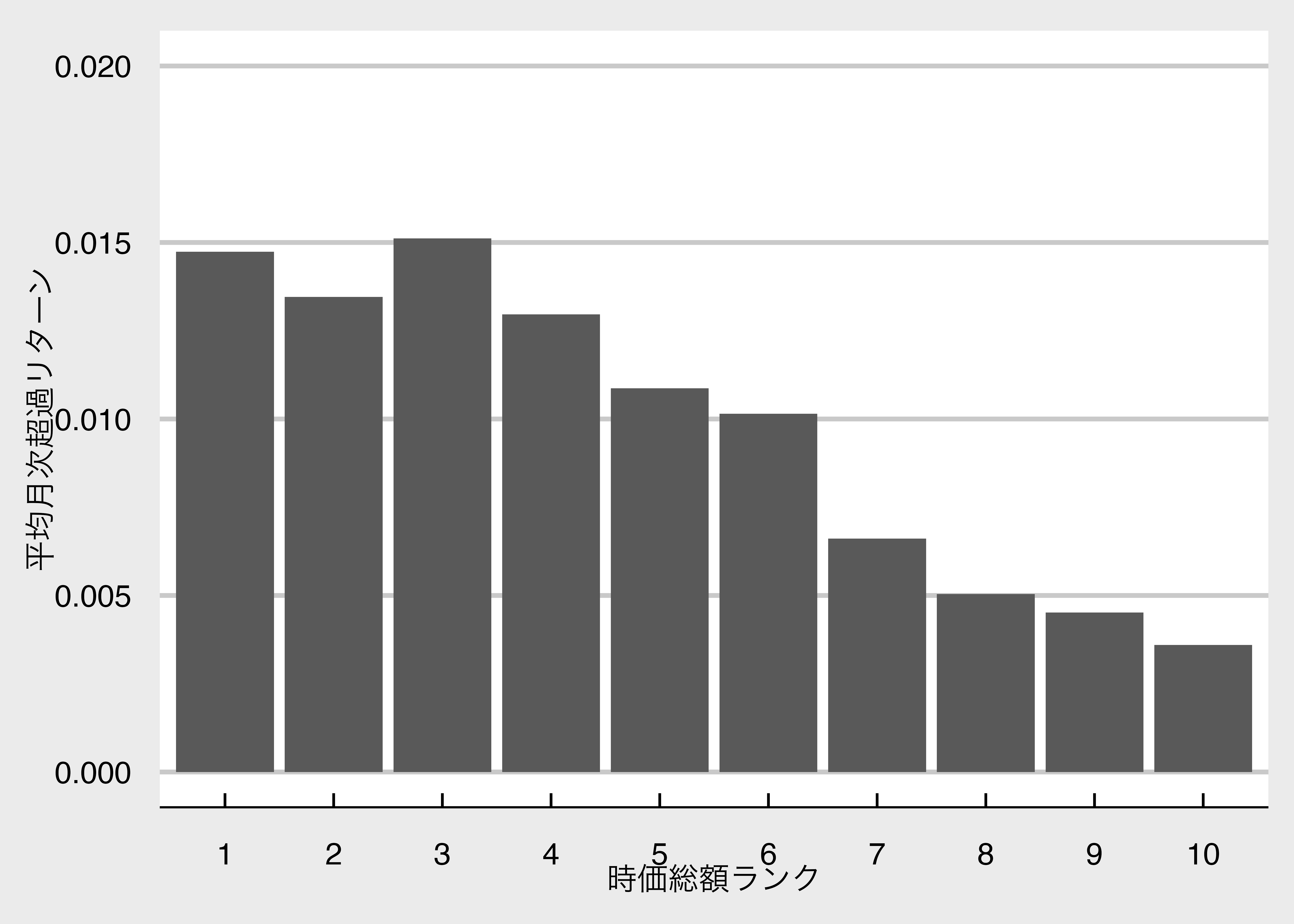
小型株ほど月次超過リターンの平均が高いことが分かりました。 このように、時価総額の大きい企業のポートフォリオと小さい企業のポートフォリオのリターンの差をサイズ・プレミアムと呼びます。
先ほどは各ポートフォリオの区分を同じウェイトで保有した場合のリターンを計算しましたが,コラムでは,時価総額の大きさに応じてウェイトを変えた時価総額加重ポートフォリオを作成して,先ほどの結果を再現してみる。
まずは等加重の場合のコードを確認する。
BPRに基づくポートフォリオ・ソート(等加重の場合)
annual_data <- annual_data |>
mutate(
lagged_BEME = lagged_BE / lagged_ME
) |>
mutate(
# 簿価時価比率に基づいて十個のグループに分類
BEME_rank10 = as.factor(ntile(lagged_BEME, 10)),
.by = year
)
BEME_sorted_portfolio <- annual_data |>
select(year, firm_ID, BEME_rank10, lagged_ME) |>
full_join(monthly_data, by = c("year", "firm_ID")) |>
drop_na() |>
summarize(
# 月次超過リターンの平均値を計算
Re = mean(Re),
.by = c(month_ID, BEME_rank10)
)
# 作図
BEME_sorted_portfolio |>
summarize(
mean_Re = mean(Re),
.by = BEME_rank10
) |>
ggplot() +
geom_col(aes(x = BEME_rank10, y = mean_Re)) +
geom_hline(yintercept = 0) + # y = 0の直線を追加
labs(x = "BE/ME Rank", y = "Mean Monthly Excess Return") +
scale_y_continuous(limits = c(-0.005, 0.02)) + mystyle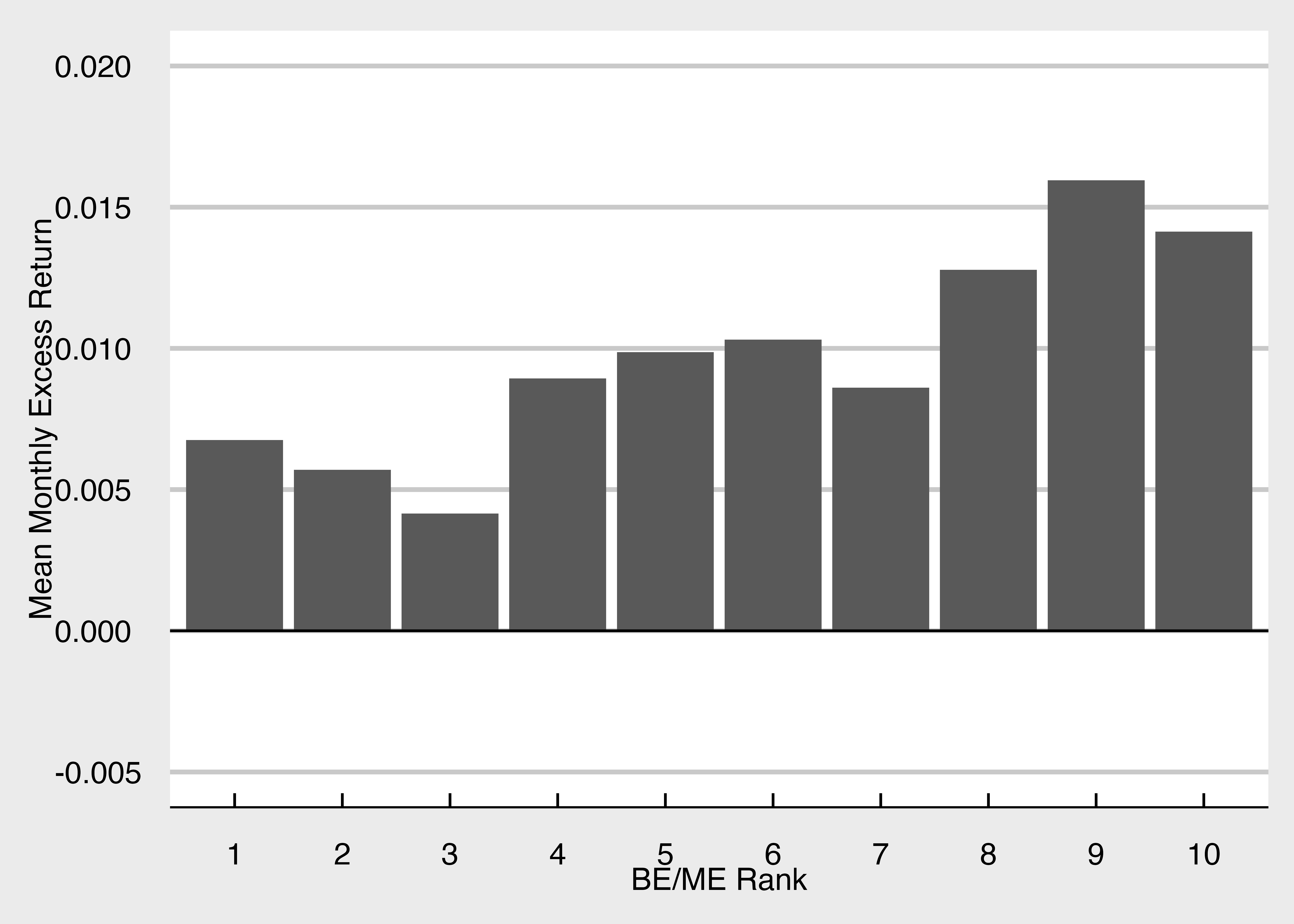
次に時価総額加重の場合のコードを確認します。
BPRに基づくポートフォリオ・ソート(時価総額加重の場合)
# 中盤で保有比率wと月次超過リターンReを計算している箇所を除けば,ch06_15aと全く同じ
annual_data <- annual_data |>
mutate(
lagged_BEME = lagged_BE / lagged_ME
) |>
mutate(
BEME_rank10 = as.factor(ntile(lagged_BEME, 10)),
.by = year
)
BEME_sorted_portfolio <- annual_data |>
select(year, firm_ID, BEME_rank10, lagged_ME) |>
full_join(monthly_data, by = c("year", "firm_ID")) |>
drop_na() |>
mutate(
# 各ポートフォリオで保有比率を計算
w = lagged_ME / sum(lagged_ME),
.by = c(month_ID, BEME_rank10)
) |>
summarize(
# 時価総額加重の月次超過リターンを計算
Re = sum(w * Re),
.by = c(month_ID, BEME_rank10)
)
BEME_sorted_portfolio |>
summarize(
mean_Re = mean(Re),
.by = BEME_rank10
) |>
ggplot() +
geom_col(aes(x = BEME_rank10, y = mean_Re)) +
geom_hline(yintercept = 0) +
labs(x = "BE/ME Rank", y = "Mean Monthly Excess Return") +
scale_y_continuous(limits = c(-0.005, 0.02)) + mystyle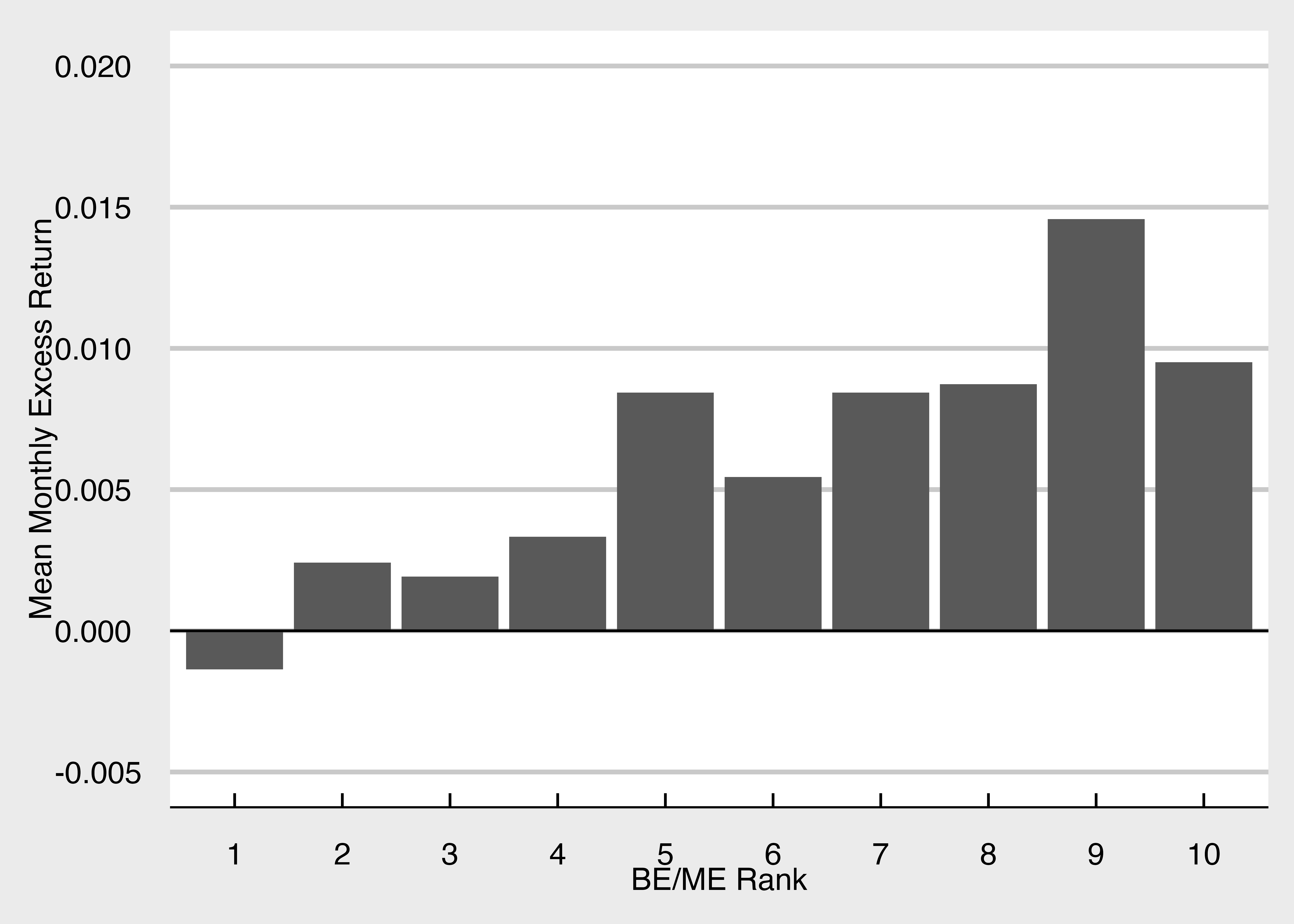
結果が異なっていることに注意しましょう。
次節では,この現象を,資産価格モデルの1つであるCAPM(Capital Asset Pricing Model)が説明できるかどうかを検証します。
6.4 CAPMの実証的な検証
6.4.1 CAPMを検証する意義
まずはCAPMの復習から始めましょう。 CAPMは,資産の期待リターンを,市場ポートフォリオの期待リターンと市場ポートフォリオとの共分散で説明するモデルです。
- 第1命題: 市場ポートフォリオは接点ポートフォリオと一致し,効率的フ ロンティア(資本市場線)上に位置する.
- 第2命題: 各証券のリスクプレミアムは,その証券のマーケット・ベータ に比例する.
\mathbb{E}[R_i] - R_F = \beta_i \left ( \mathbb{E}[R_M] - R_F \right ) ただし, \beta_i = \frac{\mathrm{COV}_{R_i, R_M}}{\mathrm{Var}_M}
このCAPMを回帰式で表現すると次のようになります。
R_{i,t}^e = \beta_i \times R_{M,t}^e + \varepsilon_{i,t} ここで、R^e_{i,t} = R_{i,t} - R_{F,t}である。 つまり、t時点における証券iの実現超過リターンR_{i,t}^eは、t時点における市場ポートフォリオの実現超過リターンR_{M,t}^eと、証券iの市場ポートフォリオに対するベータ係数\beta_iの積に、誤差項\varepsilon_{i,t}を加えたものとして表現されます。
また、誤差項\varepsilon_{i,t}に関して次の仮定を置きます。
- varepsilon _{i,t}は独立同一分布(i.i.d.)に従う
- E[\varepsilon_{i,t}] = 0
- E[R_{M,t}^e , \ \varepsilon_{i,t} ] = 0
こうすることで、CAPM式を線形回帰モデルで表現できるので、\beta_iの推定が可能となります。
6.4.1.1 時系列回帰
CAPM式は任意のi証券で成立するモデルのため、ポートフォリオにも応用できます。 つまりあるポートフォリオの超過リターンを、市場ポートフォリオの超過リターンと、そのポートフォリオに対するベータ係数の積で説明することができます。
R_{P,t}^e = \alpha _P + \beta_P R_{M,t}^e + \varepsilon_{P,t}
CAPMの式と比較すると、切片である\alpha _Pが追加されていることが分かります。 もし証券市場にCAPMの関係が成立しているなら、\alpha _Pはゼロとなっているはずです。 この$$を調べることで、CAPMの検証が可能となります。
ここでは、時系列回帰を使って、市場ポートフォリオの超過リターンを説明変数として、各ポートフォリオの超過リターンを説明するモデルを推定します。
# A tibble: 2 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 0.0121 0.00404 3.00 0.00395
2 R_Me 0.654 0.0976 6.70 0.00000000937# ch06_18: 時系列回帰 (2)
ME_sorted_portfolio |>
filter(ME_rank10 == 1) |>
ggplot(aes(x = R_Me, y = Re)) + # aes()関数はggplot()関数の中にも代入可能
geom_point() + # geom_point()関数と次のgeom_smooth()関数で共通のaes()関数を受け取る
geom_smooth(method = "lm", color = "black") +
labs(x = "Excess Return of Market Portfolio", y = "Excess Return of Small Size Portfolio") +
theme_classic()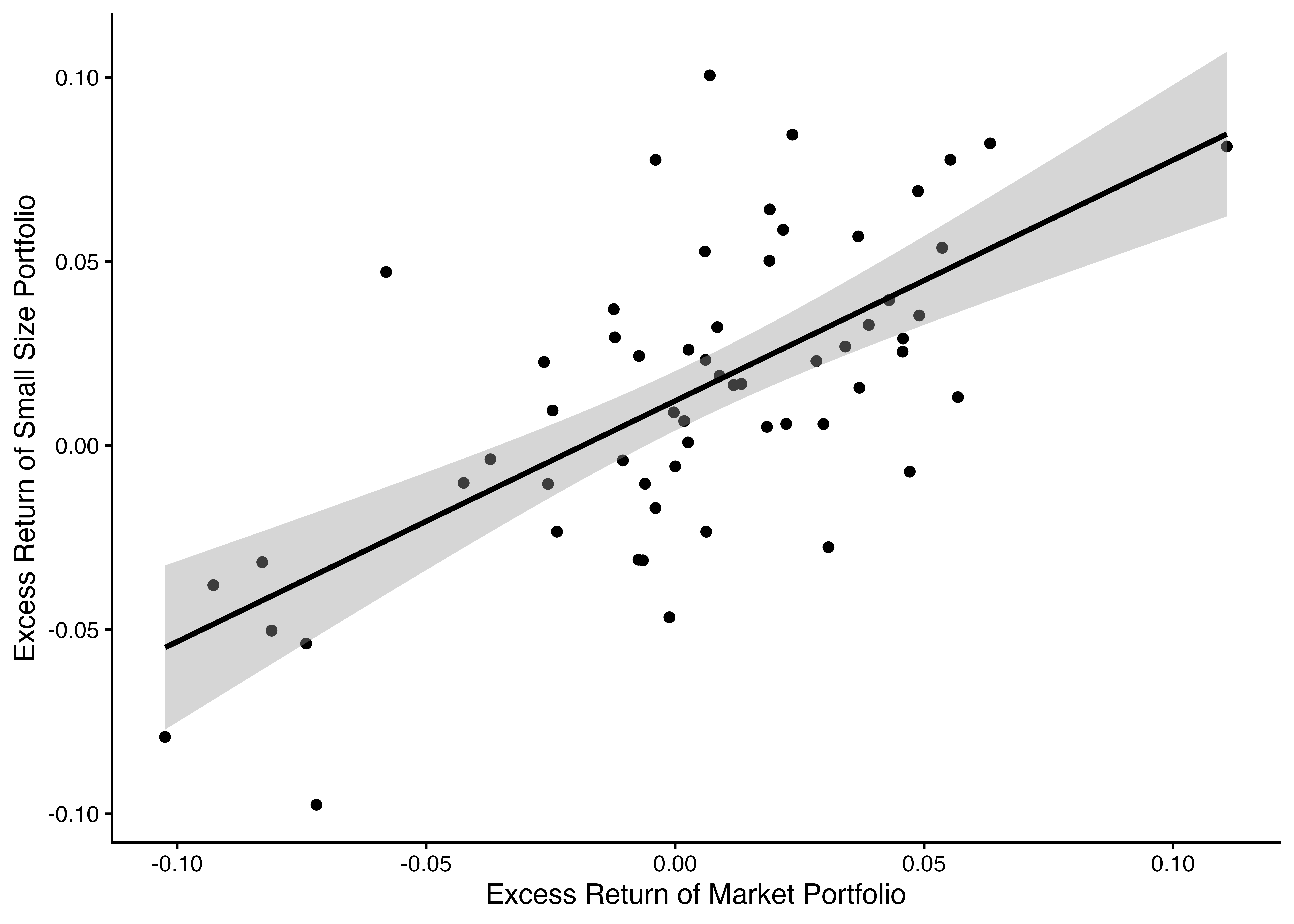
6.4.1.2 ポートフォリオごとの回帰
グループごとの線形回帰 (1) lapply()関数を使う場合
ME_sorted_portfolio_splitted <- split(ME_sorted_portfolio, ME_sorted_portfolio$ME_rank10) # 元データをME_rank10の値に応じて十個のデータフレームに分割
estimate_CAPM <- function(return_data) { # リターン・データを受け取り, CAPMの推定結果をデータフレームで返す関数を準備
lm_results <- lm(Re ~ R_Me, data = return_data)
tidied_lm_results <- tidy(lm_results)
}
CAPM_results_by_lapply <- lapply(ME_sorted_portfolio_splitted, estimate_CAPM)
# lapply()関数は第一引数にリスト, 第二引数に関数を取る
# lapplyの返り値はリストなので,一つのデータフレームにまとめたい場合はdo.call()関数を用いるグループごとの線形回帰 (2) map()関数を使う場合
ME_sorted_portfolio |>
nest(.by = ME_rank10) |> # 【修正1】ここでグループ化を指定して畳み込む
mutate(
# map()関数を用いて各グループを線形回帰
CAPM_regression = map(data, ~lm(Re ~ R_Me, data = .x)),
CAPM_summary = map(CAPM_regression, tidy)
# 【修正2】ここは既にランクごとの行になっているので .by は不要
) |>
select(-c(data, CAPM_regression)) |>
unnest(cols = CAPM_summary)# A tibble: 20 × 6
ME_rank10 term estimate std.error statistic p.value
<fct> <chr> <dbl> <dbl> <dbl> <dbl>
1 2 (Intercept) 0.0106 0.00375 2.83 6.44e- 3
2 2 R_Me 0.711 0.0908 7.83 1.19e-10
3 8 (Intercept) 0.00122 0.00168 0.723 4.73e- 1
4 8 R_Me 0.956 0.0407 23.5 2.59e-31
5 4 (Intercept) 0.00957 0.00289 3.31 1.62e- 3
6 4 R_Me 0.848 0.0699 12.1 1.54e-17
7 7 (Intercept) 0.00284 0.00173 1.64 1.06e- 1
8 7 R_Me 0.943 0.0418 22.6 2.16e-30
9 1 (Intercept) 0.0121 0.00404 3.00 3.95e- 3
10 1 R_Me 0.654 0.0976 6.70 9.37e- 9
11 9 (Intercept) 0.000406 0.00144 0.282 7.79e- 1
12 9 R_Me 1.03 0.0349 29.5 1.33e-36
13 3 (Intercept) 0.0120 0.00312 3.86 2.90e- 4
14 3 R_Me 0.770 0.0754 10.2 1.42e-14
15 6 (Intercept) 0.00653 0.00195 3.34 1.45e- 3
16 6 R_Me 0.904 0.0472 19.2 9.39e-27
17 5 (Intercept) 0.00728 0.00234 3.11 2.86e- 3
18 5 R_Me 0.896 0.0565 15.9 9.35e-23
19 10 (Intercept) -0.000659 0.00113 -0.582 5.63e- 1
20 10 R_Me 1.06 0.0273 38.9 2.93e-436.4.1.3 CAPMアルファ
CAPMアルファの可視化
CAPM_results |>
filter(term == "(Intercept)") |> # 定数項に関する推定結果のみを抽出
mutate(
# ME_rank10を整数型からファクター型に
ME_rank10 = as.factor(ME_rank10)
) |>
# 横軸をME_rank10, 縦軸をCAPM_alphaとする棒グラフ
ggplot() + aes(x = ME_rank10, y = estimate) +
geom_col() + # 棒グラフ
geom_hline(yintercept = 0) + # y = 0の直線を追加
labs(x = "ME Rank", y = "CAPM alpha") +
scale_y_continuous(limits = c(-0.003, 0.013)) +
mystyle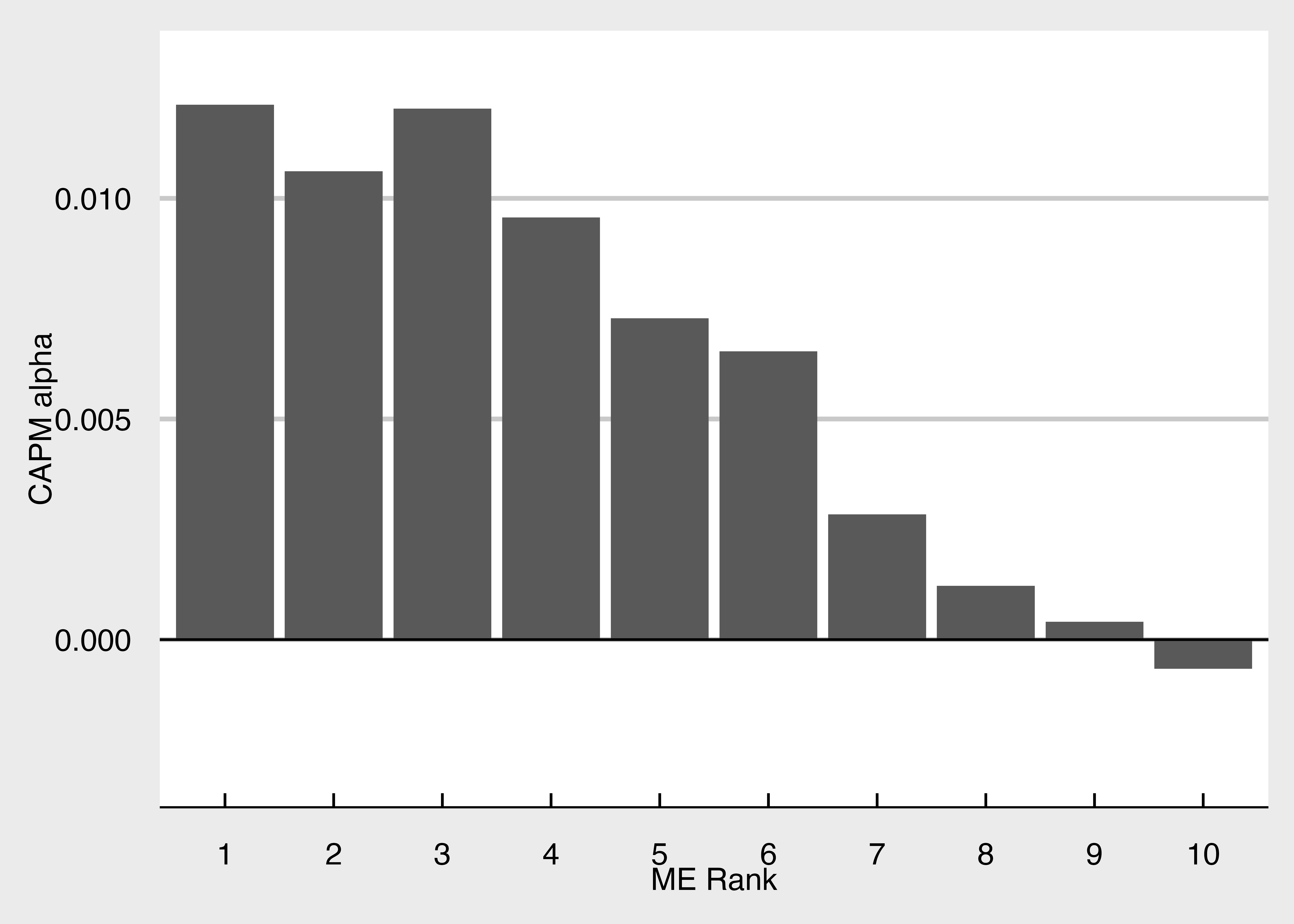
CAPMアルファの統計的な有意性を評価
CAPM_results |>
filter(term == "(Intercept)") |> # 定数項を抽出
rename(
# 列名を変更
CAPM_alpha = estimate,
p_value = p.value
) |>
mutate(
# 統計的に有意な結果を*で強調
significance = cut(p_value,
breaks = c(0, 0.01, 0.05, 0.1, 1),
labels = c("***", "**", "*", ""),
include.lowest = TRUE)
) |>
select(# 出力したい列を指定
ME_rank10, CAPM_alpha, p_value, significance
)# A tibble: 10 × 4
ME_rank10 CAPM_alpha p_value significance
<int> <dbl> <dbl> <fct>
1 1 0.0121 0.00395 "***"
2 2 0.0106 0.00644 "***"
3 3 0.0120 0.000290 "***"
4 4 0.00957 0.00162 "***"
5 5 0.00728 0.00286 "***"
6 6 0.00653 0.00145 "***"
7 7 0.00284 0.106 ""
8 8 0.00122 0.473 ""
9 9 0.000406 0.779 ""
10 10 -0.000659 0.563 "" 証券市場線の推定
ME_cross_sectional_return <- CAPM_results |>
filter(term == "R_Me") |> # R_Meの係数を抽出
rename(CAPM_beta = estimate) |> # 名称変更
select(ME_rank10, CAPM_beta) |> # 変数を選択
mutate( # ファクター型に変換
ME_rank10 = as.factor(ME_rank10)
) |>
# 超過リターンのデータと結合
full_join(
ME_cross_sectional_return, ., by = "ME_rank10"
)
# 平均超過リターンと平均市場ポートフォリオ超過リターンを計算
mean_R_Me <- mean(factor_data$R_Me)
ggplot(ME_cross_sectional_return) +
aes(x = CAPM_beta, y = mean_Re) +
geom_point() + # 散布図
geom_abline(intercept = 0, slope = mean_R_Me) + # 証券市場線
labs(x = "市場beta", y = "平均超過リターン") + #
scale_x_continuous(limits = c(0, 1.2), expand = c(0, 0)) +
scale_y_continuous(limits = c(0, 0.02)) + mystyle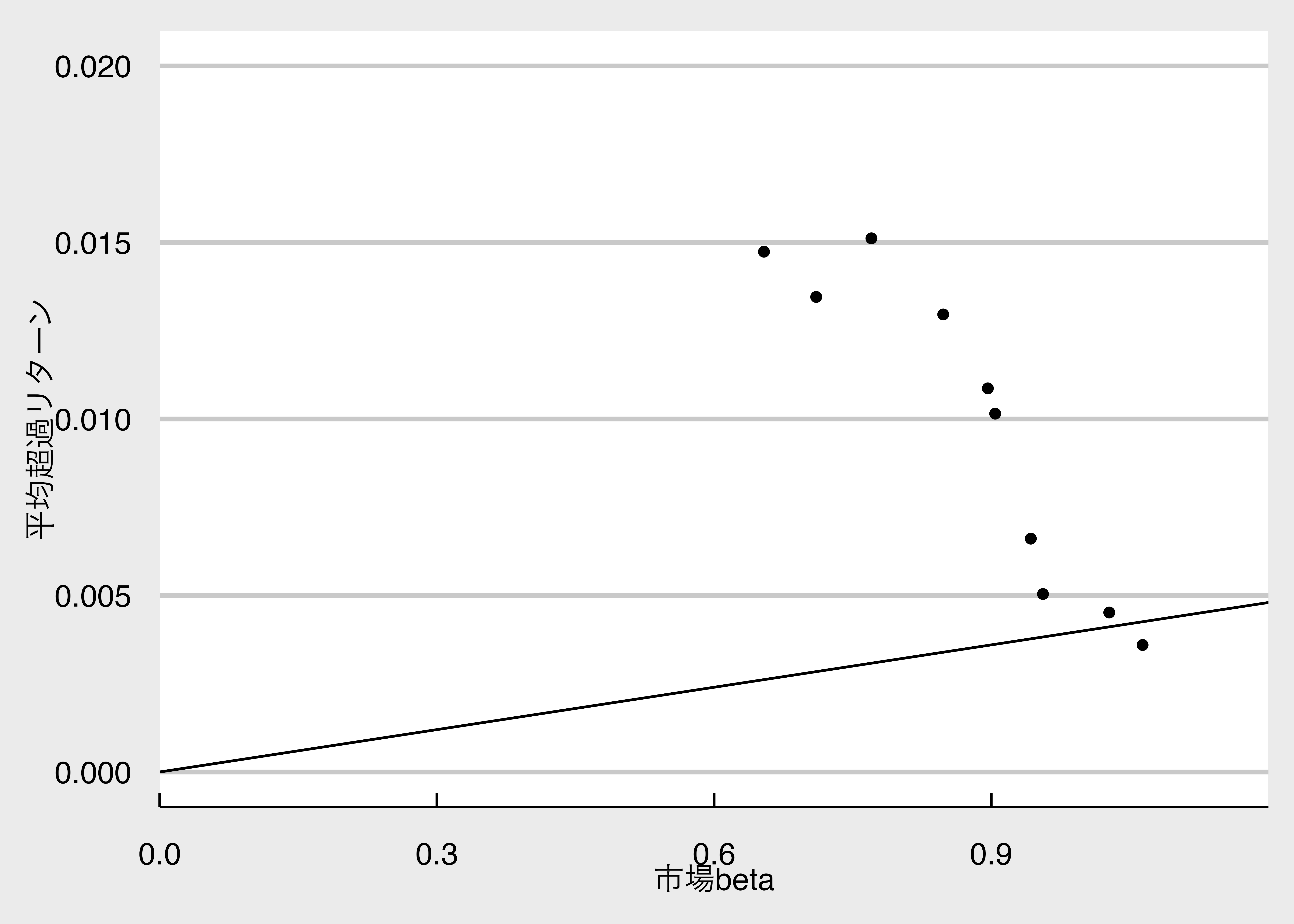
6.4.2 Fama-Frenchの3ファクター・モデル
6.4.2.1 銘柄のランク付け
簿価時価比率に基づくランク付け (1)
# A tibble: 7,920 × 26
year firm_ID ME annual_R annual_R_F annual_Re industry_ID sales OX
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2015 1 3577. NA 0.00743 NA NA NA NA
2 2016 1 6883. 0.997 0.000565 0.997 1 5949. 564.
3 2017 1 11377. 0.688 0.0000488 0.688 1 6505. 691.
4 2018 1 8695. -0.214 0.00579 -0.219 1 6846. 751.
5 2019 1 13958. 0.647 -0.000770 0.648 1 7572. 959.
6 2020 1 9709. -0.284 0.000380 -0.285 1 7538. 778.
7 2015 2 4087. NA 0.00579 NA 1 3506. 45.8
8 2016 2 5593. 0.375 -0.000770 0.376 1 3491. 51.2
9 2017 2 9153. 0.641 0.000380 0.640 1 3946. 83.4
10 2018 2 7104. -0.220 0.00371 -0.223 1 4139. 93.4
# ℹ 7,910 more rows
# ℹ 17 more variables: NFE <dbl>, X <dbl>, OA <dbl>, FA <dbl>, OL <dbl>,
# FO <dbl>, BE <dbl>, lagged_BE <dbl>, ROE <dbl>, lag_ME <dbl>,
# lagged_BEME <dbl>, lagged_ME <dbl>, w_M <dbl>, ME_rank10 <fct>,
# BEME_rank10 <fct>, ME_rank2 <fct>, BEME_percent_rank <dbl>簿価時価比率に基づくランク付け (2)
6.4.2.2 時価総額とBE/MEに基づくポートフォリオ・ソート
Size-BE/MEポートフォリオへの分類 (3)
# A tibble: 6 × 6
ME_rank2 BEME_rank3 FF_portfolio_type mean_BEME mean_ME mean_N_stocks
<fct> <fct> <fct> <dbl> <dbl> <dbl>
1 1 3 SH 1.97 11023. 260.
2 1 2 SN 0.973 11868. 226
3 1 1 SL 0.416 11601. 155.
4 2 2 BN 0.960 211793. 286
5 2 3 BH 1.72 151135. 125.
6 2 1 BL 0.468 414941. 230.Size-BE/MEポートフォリオの構築 (2)
FF_portfolio <- annual_data |>
select(
year, firm_ID, FF_portfolio_type, ME_rank2, BEME_rank3, w
) |>
full_join(
monthly_data,
by = c("year", "firm_ID")
) |> # 今までに準備したデータと月次データを結合
summarize(
ME_rank2 = ME_rank2[1],
BEME_rank3 = BEME_rank3[1],
R = sum(w * R, na.rm = TRUE), # 各ポートフォリオの月次リターンを計算
R_F = R_F[1],
.by = c(month_ID, FF_portfolio_type)
) |>
drop_na() # 欠損データを削除Size-BE/MEポートフォリオのリターンの可視化 (1)
FF_portfolio_mean_return <- FF_portfolio |>
mutate(Re = R - R_F) |>
summarize(
ME_rank2 = ME_rank2[1],
BEME_rank3 = BEME_rank3[1],
mean_Re = mean(Re),
.by = FF_portfolio_type
) # 各ポートフォリオの超過リターンの平均値を計算
ggplot(FF_portfolio_mean_return) +
geom_col(aes(x = BEME_rank3, y = mean_Re, fill = ME_rank2), position = "dodge") + # x軸をBEME_rank3, y軸をmean_Reに, ME_rank2のサブグループで色分け
scale_fill_grey() + # 棒グラフの色をモノトーンに
labs(x = "BE/ME Rank", y = "Mean Monthly Excess Return", fill = "ME Rank") +
scale_y_continuous(expand = c(0, 0)) + mystyle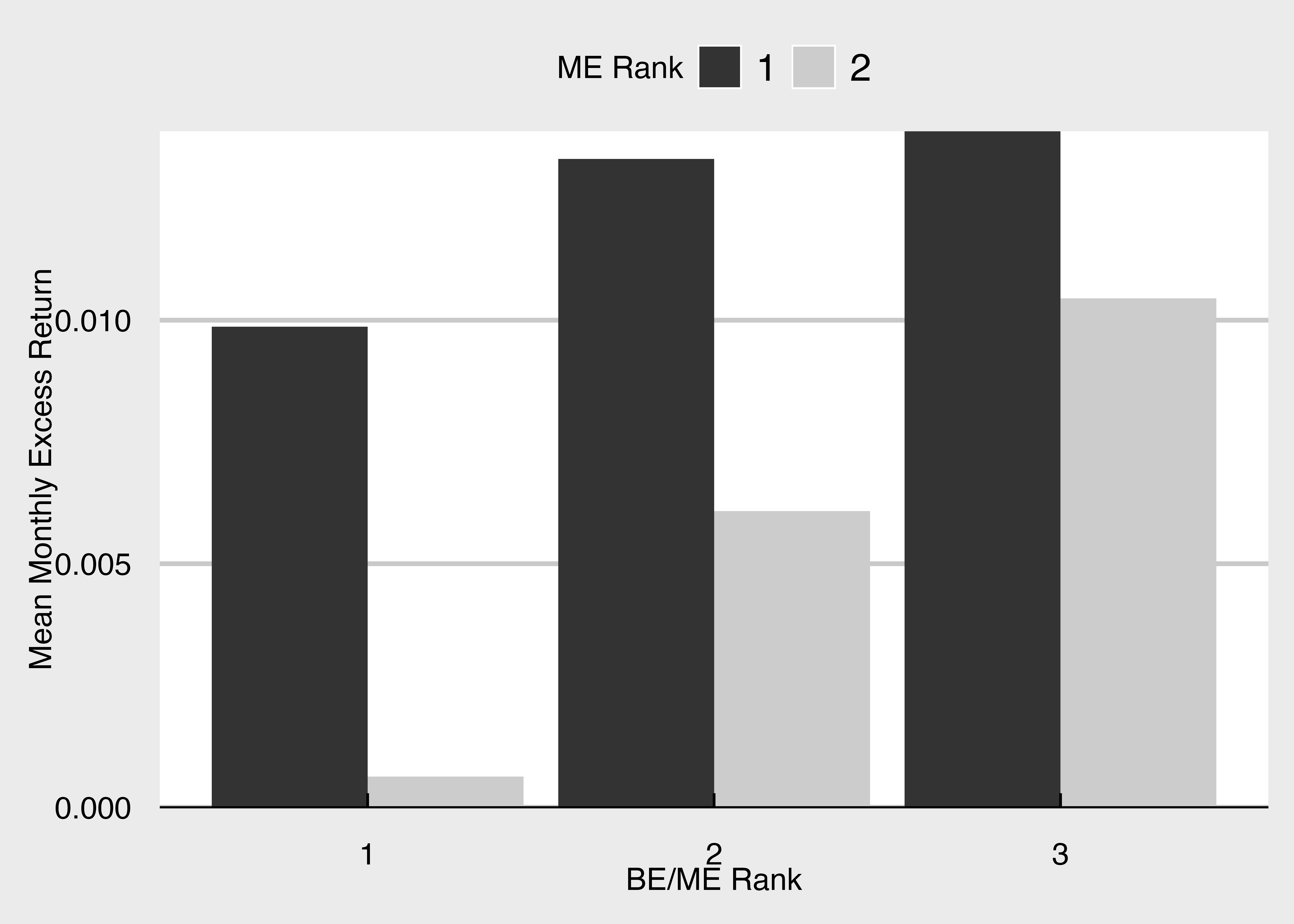
Size-BE/MEポートフォリオのリターンの可視化 (2)
ggplot(FF_portfolio_mean_return) +
geom_col(aes(x = BEME_rank3, y = mean_Re, fill = ME_rank2), position = "dodge") +
scale_fill_grey() +
geom_text(aes(x = BEME_rank3, y = mean_Re, group = ME_rank2, label = FF_portfolio_type), # (x, y)座標を指定して各ポートフォリオの名前をグラフに挿入
vjust = -0.5, # 棒グラフが重ならないよう文字ラベルを上にずらす
position = position_dodge(width = 0.9)) + # ME_rank2のサブグループで文字ラベルが左右にずれるよう調整
labs(x = "BE/ME Rank", y = "Mean Monthly Excess Return", fill = "ME Rank") +
scale_y_continuous(expand = c(0, 0), limits = c(0, 0.015)) + # 文字ラベルがはみ出ないようy軸の範囲を指定
theme_classic()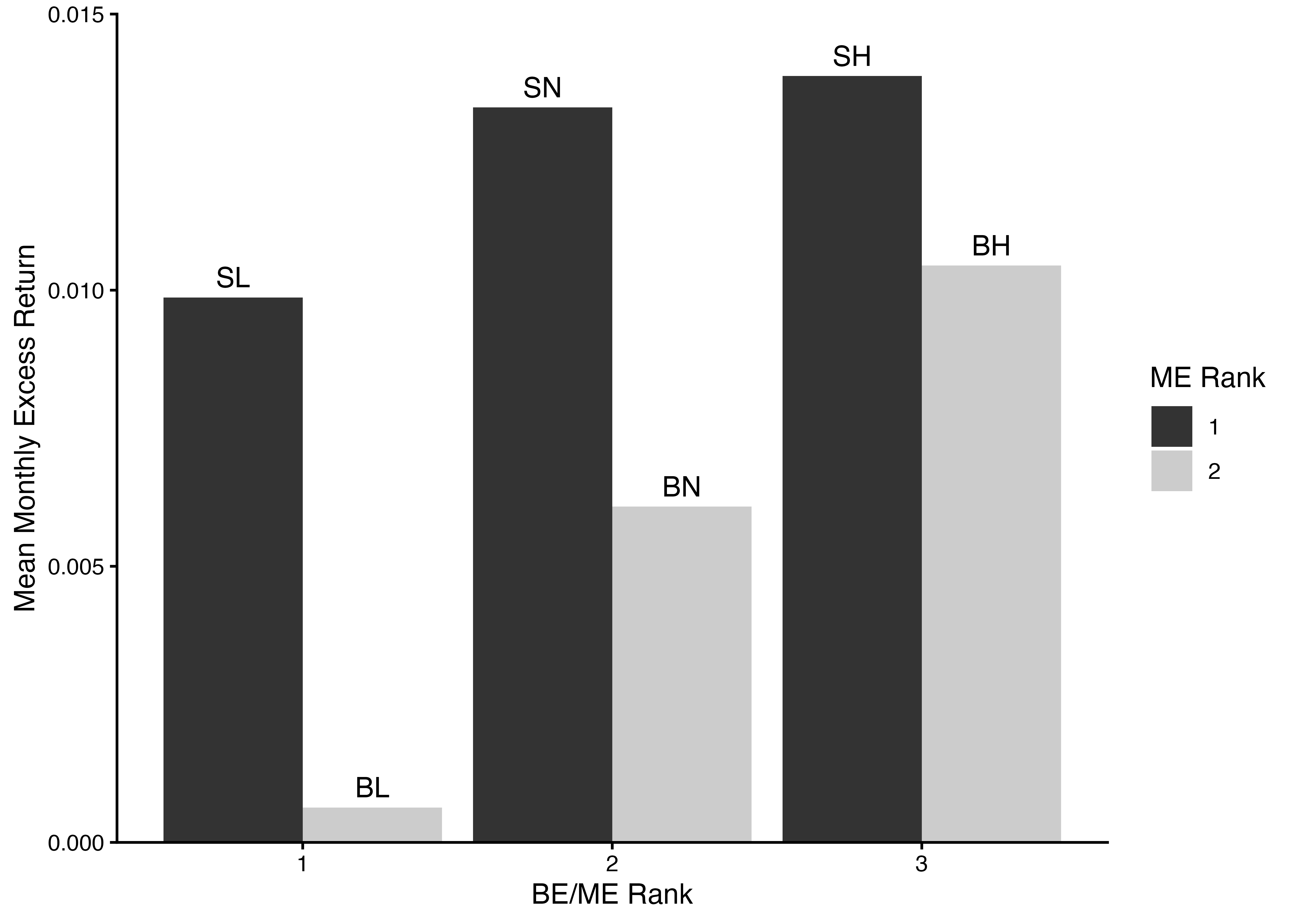
Size-BE/MEポートフォリオのリターンの可視化 (3)
initial_point <- tibble(
month_ID = c(12, 12), # 累積リターンの起点を定義
cumulative_gross_R = c(1, 1),
FF_portfolio_type = c("BL", "SH")
)
FF_portfolio_cumulative_return <- FF_portfolio |>
mutate(# グロス・リターンを累積
cumulative_gross_R = cumprod(1 + R),
.by = FF_portfolio_type
) |>
filter(FF_portfolio_type %in% c("BL", "SH")) |>
select(month_ID, cumulative_gross_R, FF_portfolio_type) |>
bind_rows(initial_point)
ggplot(FF_portfolio_cumulative_return) +
geom_line(aes(x = month_ID, y = cumulative_gross_R, linetype = FF_portfolio_type)) +
scale_linetype_manual(values = c("longdash", "solid")) +
geom_hline(yintercept = 1, linetype = "dotted") +
labs(x = "Month ID", y = "Cumulative Gross Return", linetype = "") +
scale_x_continuous(expand = c(0, 0)) + mystyle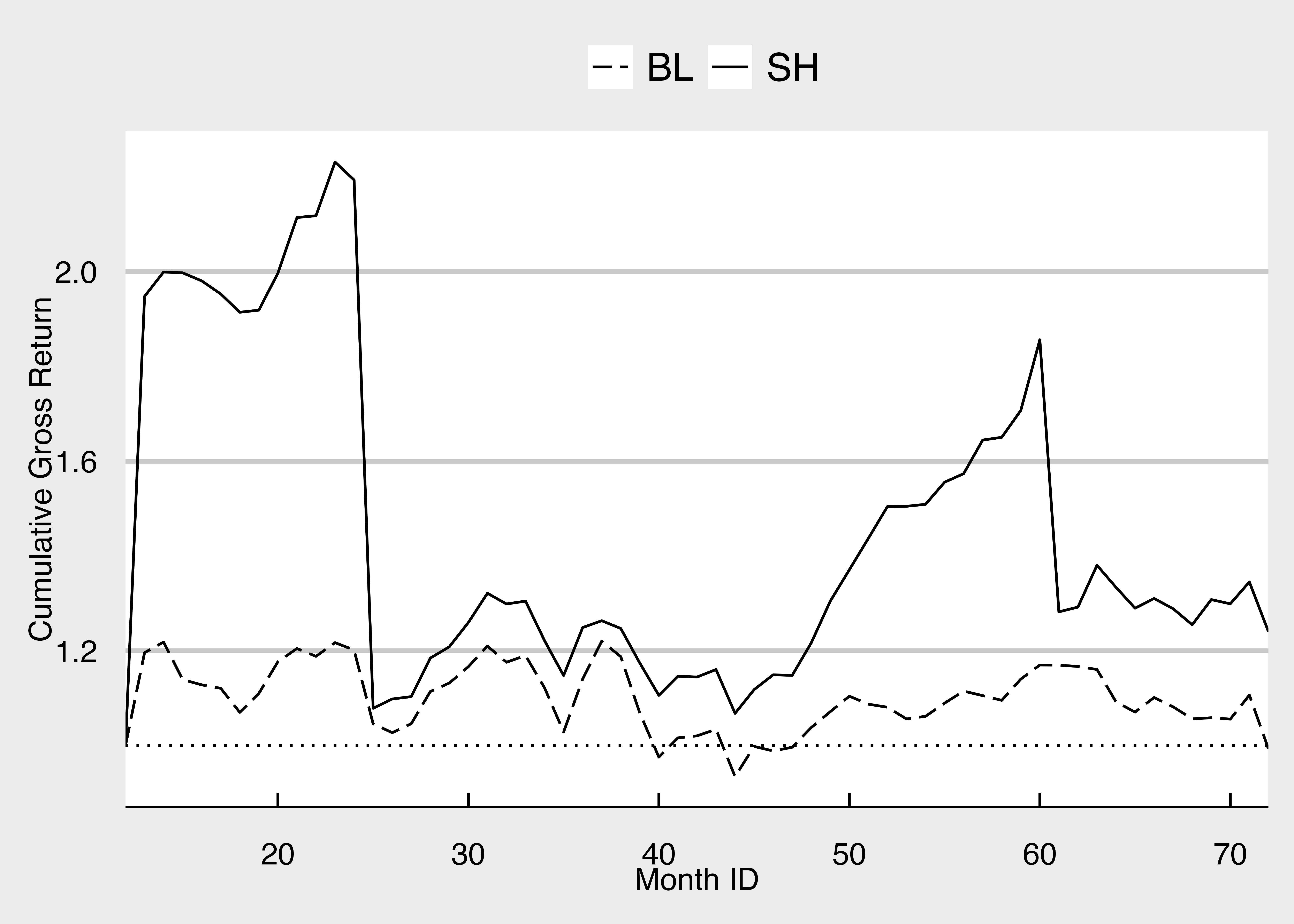
6.4.2.3 ファクター・リターンの計算
SMBとHMLの構築 (2)
6.4.2.4 FF3アルファ
FF3モデルの推定
ME_sorted_portfolio <- ME_sorted_portfolio |>
select(-c(R_Me, R_M)) |>
# 3ファクターの実現値をME_sorted_portfolioに追加
full_join(factor_data, by = "month_ID")
FF3_results <- list(NA) # 推定結果を保存するために空のリストを準備
for(i in 1:10) {
FF3_results[[i]] <- ME_sorted_portfolio |>
filter(ME_rank10 == i) |>
lm(Re ~ R_Me + SMB + HML, data = _) |> # 3ファクターの実現値を独立変数として重回帰
tidy() |>
mutate(ME_rank10 = i) |> # 推定対象のポートフォリオ名を保存
select(ME_rank10, everything()) # ME_rank10を第一列に移動
}
FF3_results <- do.call(rbind, FF3_results) # do.call()関数を用いて複数のデータフレームから構成されるリストを一つのデータフレームに統合FF3アルファの可視化
FF3_results |>
filter(term == "(Intercept)") |> # 定数項に関する推定結果のみを抽出
mutate(
ME_rank10 = as.factor(ME_rank10)
) |> # ME_rank10を整数型からファクター型に
ggplot() +
# 横軸をME_rank10, 縦軸をFF3_alphaとする棒グラフ
geom_col(aes(x = ME_rank10, y = estimate)) +
geom_hline(yintercept = 0) +
labs(x = "ME Rank", y = "FF3 alpha") +
scale_y_continuous(limits = c(-0.003, 0.013)) + mystyle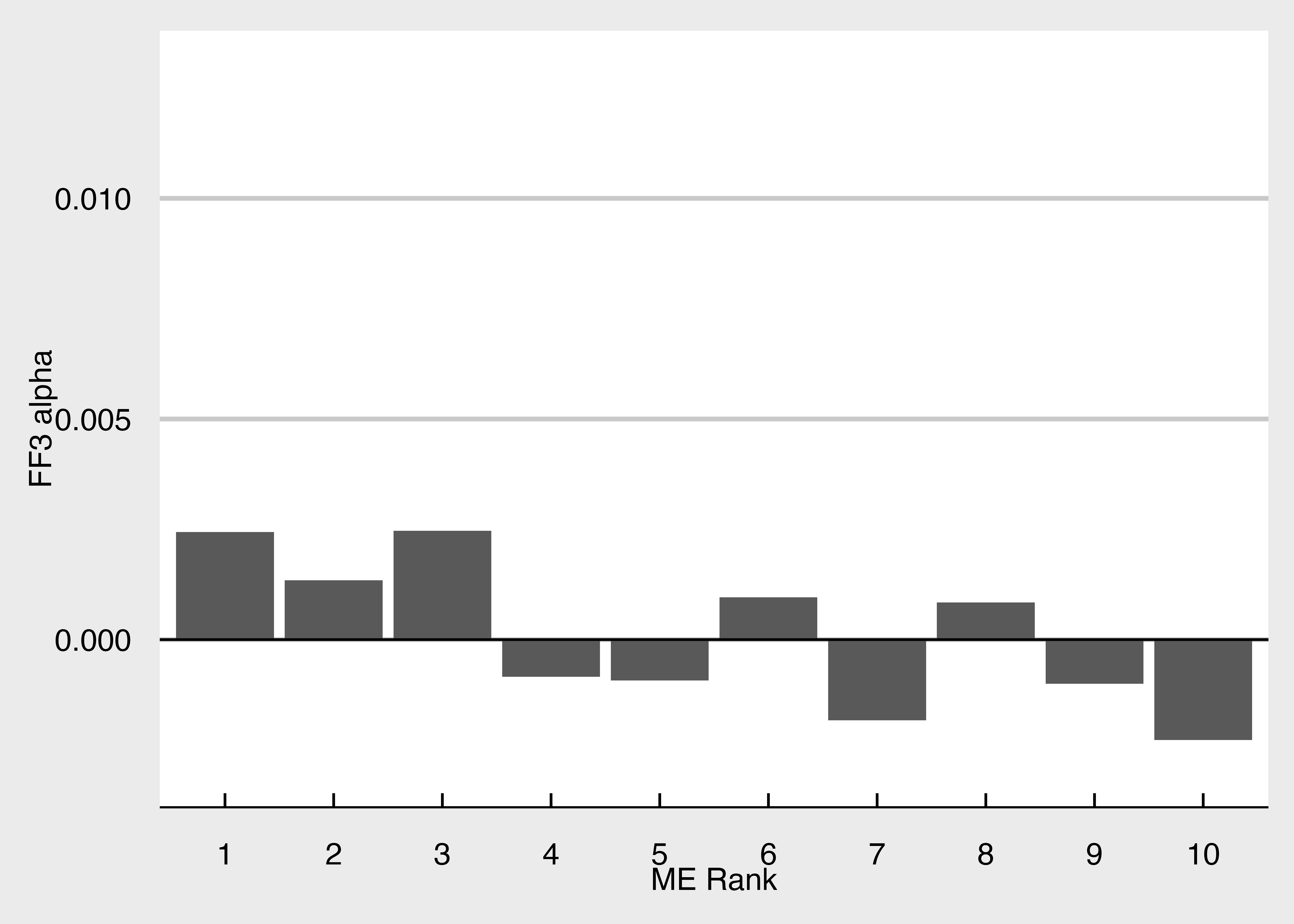
FF3アルファの統計的な有意性を評価
FF3_results |>
filter(term == "(Intercept)") |> # 定数項に関する推定結果のみを抽出
rename(
FF3_alpha = estimate,
p_value = p.value
) |> # 列名を変更
mutate(
significance = cut(p_value,
breaks = c(0, 0.01, 0.05, 0.1, 1),
labels = c("***", "**", "*", ""),
include.lowest = TRUE)
) |> # 統計的に有意な結果を*で強調
select(ME_rank10, FF3_alpha, p_value, significance)# A tibble: 10 × 4
ME_rank10 FF3_alpha p_value significance
<int> <dbl> <dbl> <fct>
1 1 0.00244 0.181 ""
2 2 0.00134 0.412 ""
3 3 0.00246 0.0893 "*"
4 4 -0.000843 0.335 ""
5 5 -0.000924 0.336 ""
6 6 0.000957 0.456 ""
7 7 -0.00183 0.119 ""
8 8 0.000842 0.555 ""
9 9 -0.00100 0.522 ""
10 10 -0.00228 0.0492 "**"