## ファイナンス入門
```{r setup}
#| code-fold: true
pacman::p_load(
tidyverse, # 便利なパッケージ群
ggthemes, # ggplot2のテーマ集
plotly, # インタラクティブなグラフ作成
patchwork # 複数のグラフをまとめて表示
)
mystyle <- list(
# 1. ggthemes 自体の引数でフォントを指定します
theme_economist_white(
# gray_bg = FALSE,
base_family = "HiraKakuProN-W3"
),
scale_colour_economist(),
# theme_calc(base_family = "HiraKakuProN-W3"),
# scale_colour_calc(),
# 3. その他の微調整(フォントサイズなど)
theme(
text = element_text(size = 12), # フォントファミリーは上で指定済みなので省略可
# 必要であれば個別の要素を調整
# plot.title = element_text(hjust = 0.5),
axis.title = element_text(size = 12)
)
)
```
## 割引率
**ファイナンス**(finance)の大事な概念に**割引率**(discount rate)があります。
これは、<span class="markp">ある財の今の価値と将来の価値は異なっており、将来の価値を現在の価値(これを**現在価値**(present value)という)に変換するための係数</span>です。
たとえば,今の100万円が来年110万円になる世界において,
$$
100 = f(110)
$$
と表せる関数$f$が存在するとします。このとき,110万円を現在価値に変換するための係数が割引率です。
具体的に,
$$
f(110) = \frac{110}{1 + r}
$$
と表せるとき,$r$が割引率です。
$$
\begin{aligned}
100 &= \frac{110}{1 + r}\\
r &= \frac{110}{100} - 1 = 0.1
\end{aligned}
$$
この場合,割引率$r$は0.1(10%)となります。
割引率10%の世界において,今の100万円は1年後の110万円と同じ価値をもつ,ということを意味しています。
### 確実なキャッシュ・フローに対する割引率
- **現在価値** :将来に発生するキャッシュフローの現時点における価値
- **時間価値** :将来と現在の価値の違い
- **無リスク金利** (risk-free rate) :安全資産へと投資したときのリターンで,投資時点でリターンの額が確定します。
無リスク金利は**確率変数ではなく定数**(parameter)です。
上の式を年を$T$という記号で表して一般的に表現します。
$T$年後に**確実に**獲得できるキャッシュフローを$CF_T$で表し、無リスク割引率を$R_F$で表します[^1]。
このとき現在価値 $PV$ は以下のように計算されます。
[^1]: 無リスク割引率は無リスク金利と同義で,全くリスクのない確実に手に入れられる利息のようなものです。
$$
PV = \frac{CF_T}{(1 + R_F)^T}
$$
::: {.column-margin}
現時点で$CF_0$を1年間貯金する。利息$r$は$0.1$とする。
1年後に受け取れるキャッシュフロー$CF_1$は、貯金した元本$CF_0$と利息$CF_0 \times 0.1$となる。つまり、$CF_0 + CF_0 \times 0.1 = (1+0.1)CF_0$である。
逆に、来年$CF_1$受け取るためには、今いくら貯金するかを考える。必要な貯金額を$X$とすると、$X \times (1 + 0.1) = CF_1$となる。つまり$X = CF_1/ (1.1)$となる。
これが現在価値である。
:::
将来の確実なキャッシュ・フロー$CF_T$の現在価値は、割引率$R_F$と将来受け取る時点である$T$に依存している。$CF_T = 100$の場合、$R_F$と$T$の変化に応じて現在価値がどのように変化するのか確認する。
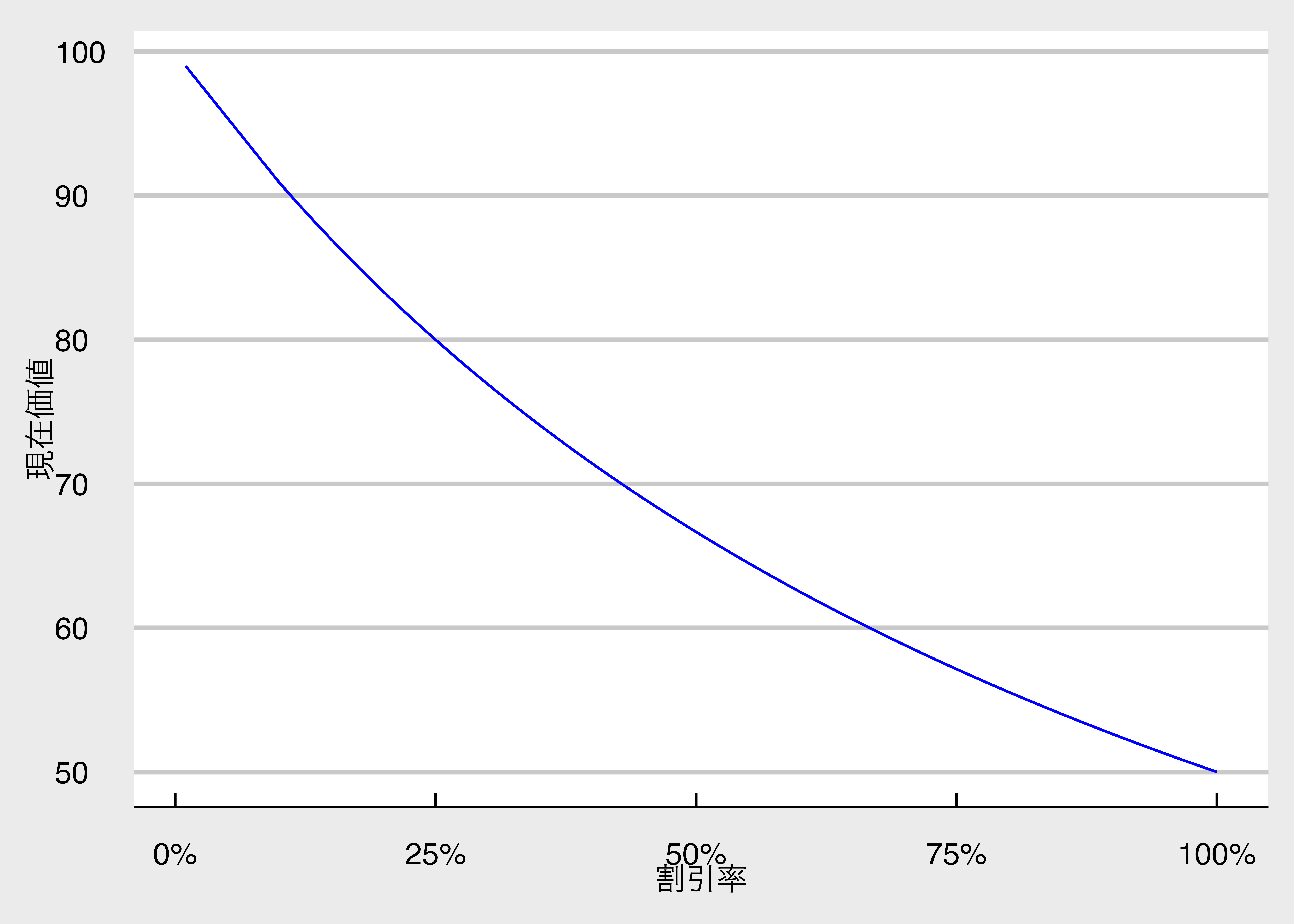
$T=1$として、横軸を割引率、縦軸を現在価値としたグラフが以下のものである。
割引率が大きくなるにつれて現在価値が小さくなることが分かる。
```{r pv_rf, filename = "現在価値と割引率"}
T_fixed <- 1 # 1年後に固定
data.frame(
R_F = c(0.01, seq(0.1, 1, by = 0.01))
) |>
mutate(
PV = 100 / (1 + R_F)^T_fixed
) |>
ggplot() + aes(x = R_F, y = PV) +
geom_line(color = "blue") +
scale_x_continuous(labels = scales::percent) + # 軸を%表示に
labs(x = "割引率", y = "現在価値") +
mystyle
```
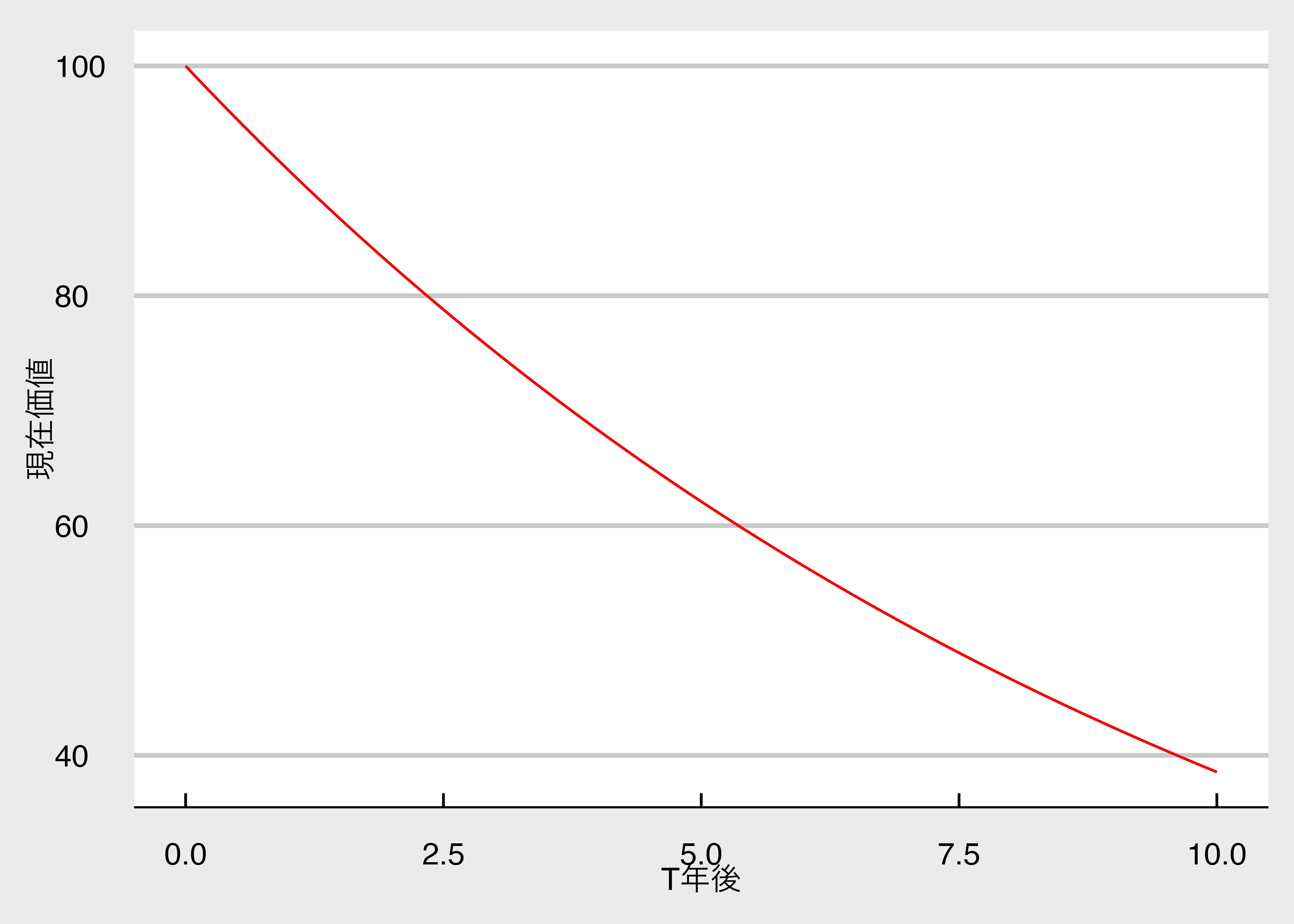
次に、$R_F = 0.1$ に固定して、横軸を年 $T$ 、縦軸を現在価値 $PV$ としてグラフが以下のものです。
図を見ると,キャッシュ・フローを受け取る時点が遠くなるほど、現在価値が小さくなることがわかります。
1年後に受け取れる100万円と,10年後に受け取れる100万円では,後者の方が価値が低い,というのは直観的ですよね。
```{r pv_T, filename = "現在価値と期間"}
R_F <- 0.1 # 無リスク利子率
T <- c(seq(0, 10, by = 0.1)) # 将来受け取る時点
PV <- 100 / (1 + R_F)^T # 現在価値の計算
df <- data.frame(T, PV) # データフレーム作成
# 作図
df |>
ggplot() +
aes(x = T, y = PV) +
geom_line(color = "red") +
xlab("T年後") + ylab("現在価値") + mystyle
```
### 不確実なキャッシュ・フローに対する割引率
<span class="marky">モデルに投資家の**リスクプレミアム**(risk premium; RP)を反映させることが割引率の2つ目の役割</span>です。
通常、将来キャッシュ・フローがいくらになるのか分からないのが普通であり、$CF$は様々な要因で変化する**確率変数**(random variable)であるため、現時点における**期待値**(expected value)で評価されます。
たとえば,1年後に確実に150万円もらえる投資Aと,確率50%で200万円,確率50%で100万円もらえる投資Bがあるとします。
期待値で評価すると,投資Aの期待キャッシュフローは150万円,投資Bの期待キャッシュフローは$0.5 \times 200 + 0.5 \times 100 = 150$万円となり,同じ期待キャッシュフローをもつことになります。
しかし,直観的に投資Bは100万円しか生み出さないリスクがある分,2つの投資の価値を現在の価値で比較すると,投資Aの方が価値が高いと思いませんか?
このリスクのある資産Bの割引率を$\tilde{R}$と表すと,2つの投資の現在価値は,次のようになります。
$$
\frac{150}{1 + R_F} \quad > \quad \frac{200 \times 0.5 + 100 \times 0.5}{1 + \tilde{R}}
$$
となるなら,
$$
R_F < \tilde{R}
$$
となります。この$R_F$と$\tilde{R}$の差が**リスクプレミアム**(risk premium: RP)です。リスクプレミアムは、リスクのある資産に投資することに対する追加的な見返りを意味します。
$$
\begin{aligned}
RP \equiv \tilde{R} - R_F\\
R_F + RP = \tilde{R}
\end{aligned}
$$
::: {.column-margin}
ここで、期待値をとる演算子(operator)を$\mathbb{E}$で表し、期待値をとる時点を添え字で表す。ここでは現時点$t=0$における期待値を$\mathbb{E}_0$と表現している。
たとえば,現時点を$t=0$として,1期先に起こりうる結果$X$が$100$か$200$であることが分かっていて,それぞれの発生確率が50%であったとする。この将来に起こりうる結果を現時点での情報を基に期待値をとる,ということは,
$$
\mathbb{E}[X] = 0.5 \times 100 + 0.5 \times 200 = 150
$$
となる。このように起こりうる結果と発生確率を掛けて足したものを**期待値**という。
:::
リスクプレミアムは割引率の調整で定量化されます。
$$
\begin{aligned}
PV_0 & = \frac{\mathbb{E_0}[CF_1]}{1 + R_F + \underbrace{(\tilde{R} - R_F)}_{\text{RP}}}\\
& =\frac{\mathbb{E_0}[CF_1]}{\underbrace{1+\tilde{R}}_{\text{リスク調整済み割引率}}}
\end{aligned}
$$
割引率は時間価値やリスクプレミアムに関する定量的な情報を含むので、タイミングやリスクの異なるキャッシュフローを現在価値という同一の尺度で評価できます。
### NPV法
先ほど学習した割引現在価値を判断の基準に,投資意思決定を行う方法を**NPV法**(Net Present Value Method)といいます。
いま,投資するかどうかを決めるタイミングを時点0($t=0$)とします。
キャッシュフローは$CF_t$で表し,マイナスなら支出,プラスなら収入を意味します。
将来キャッシュフローは不確実であるため,現時点での期待値$\mathbb{E_0}[CF_t]$で評価します。
ちなみに$CF_0$は時点0での投資なので,マイナスとなります。
投資時点からT年間にわたって毎年$\mathbb{E}[CF_t],\quad t = 1,\dots ,T$の期待キャッシュフローが生み出されるなら、それらを割引率$1 + \tilde{R}$で現在価値に直して足し合わせた値(つまりNPV)が、現時点で評価したプロジェクトの成果となります。
NPVはそのプロジェクトから発生するすべてのキャッシュフローの現在価値として解釈できます。
コーポレートファイナンスでは,
- NPVがゼロ以上のプロジェクトは投資を実行
- NPVが負のプロジェクトは投資を見送る
ことを推奨しています。
NPV法を一般的に表現すると次のようになります(p.48)。
$$
\begin{aligned}
NPV_0 &= \frac{CF_0}{(1+\tilde{R})^0} + \frac{\mathbb{E}[CF_1]}{(1+\tilde{R})^1} + \cdots + \frac{\mathbb{E}[CF_T]}{(1+\tilde{R})^T}\\
&= CF_0 + \sum_{t=1}^T\frac{\mathbb{E}[CF_t]}{(1+\tilde{R})^t}
\end{aligned}
$$
::: {.column-margin}
$x^0 = 1$ であることに注意してください。
:::
### 配当割引モデル
NPV法の考え方を株式投資に適用することもできます。
株式の保有期間を$T$年とし、時点$t$における株価を$P_t$で表します。
株式から生み出される将来キャッシュ・フローは、
- 一株当たり配当と,
- 売却時点での売却損益
であり、$t$時点の一株当たり配当を$D_t$,売却時点での一株当たり売却損益を$P_T - P_{T-1}$と表します。
将来配当や将来売却損益は確率変数であるため期待値で考え、それを割引率$\tilde{R}$で割り引くことで、一株当たりの株式価値を求めます。
$$
\begin{aligned}
P_0^* &= \frac{\mathbb{E_0}[D_1]}{1 + \tilde R} + \frac{\mathbb{E_0}[D_2]}{(1 + \tilde R)^2} + \cdots + \frac{\mathbb{E_0}[D_{\infty}]}{(1 + \tilde R)^{T}} + \frac{\mathbb{E_0}[P_T] - P_0}{(1+\tilde{R})^T}\\
&= \sum^{T}_{t=1} \frac{\mathbb{E_0}[D_t]}{(1+\tilde{R})^t} + \frac{\mathbb{E_0}[P_T] - P_0}{(1+\tilde{R})^T}
\end{aligned}
$$
十分長い期間$T \rightarrow \infty$を考えると,売却損益の現在価値はゼロに近づくため,株式の理論価値$P_0^*$は以下のように表せます。
$$
P_0^* = \sum^{\infty}_{t=1} \frac{\mathbb{E_0}[D_t]}{(1+\tilde{R})^t}
$$
これが**配当割引モデル**(Dividend Discount Model: DDM)です。
将来配当の予測値データがあれば,現時点における理論上の株価を計算することができます。
### ゴードン成長モデル
配当割引モデルは理論上は正しいのですが、将来の配当を無限に予測することは現実的ではありません。
そこで、<span class="markp">将来の配当が一定の割合で成長していくという仮定を置くこと</span>で、将来配当の予測を簡略化する方法があります。
より具体的に,期待一株当たり配当が**一定の割合で成長**していくと仮定した割引配当モデルを**ゴードン成長モデル**という。
直近の実現した一株当たり配当を$D_0$と置き、将来にわたってこの配当の期待値が一定割合$G$%で成長していくと仮定する。
つまり1時点先の配当額$D_1$が$(1 + G)D_0$となる、と仮定する。
すると、$t$ 時点先の配当額 $\mathbb{E}[D_t]$ は、成長率$G$を用いた複利計算により、
$$
D_t = (1+G)^t D_0
$$
で表すことができます。
一定割合で配当額が成長する株式の理論価値$P_0$を配当割引モデルで計算すると,
$$
\begin{aligned}
P_0 &= \frac{(1 + G) D_0}{(1+\tilde{R})} +
\frac{(1+G)^2 D_0}{(1+\tilde{R})^3} +
\frac{(1+G)^3 D_0}{(1+\tilde{R})^3} + \cdots \\
&= \sum^{\infty}_{t = 1}\frac{(1 + G)^t D_0}{(1 + \tilde{R})^t}\\
&=\frac{(1+G)D_0}{\tilde{R}-G}
\end{aligned}
$$
2本目の式から3本目の式への計算で、**等比級数の和の公式**を利用している。
::: {.callout-tip}
初項$a$,公比$r$の等比数列
$$
a, ar, ar^2, ar^3, \dots , ar^{n-1},ar^n , \dots
$$
がある。この等比数列の和を$S_n$で表す。
$$
S_n = a + ar + ar^2 + \cdots + ar^{n-1} + \cdots
$$
両辺に$r$を乗じると,
$$
rS_n = ar + ar^2 + \cdots + ar^{n-1} + ar^{n} + \cdots
$$
となる。そして,$S_n - rS_n$を計算すると,
$$
\begin{aligned}
S_n - r S_n &= a\\
(1-r)S_n &= a\\
S_n &= \frac{a}{1-r}
\end{aligned}
$$
上のゴードン成長モデルの初項は$(1+G)D_0/(1+\tilde R)$,公比は$(1 +G)/(1+\tilde R)$なので,
$$
\begin{aligned}
S_n
%P_0^* &= \frac{(1+G)D_0}{1+ \tilde R} + \frac{(1+G)^2 D_0}{(1+ \tilde R)^2} + \frac{(1+G)^3 D_0}{(1+ \tilde R)^3} + \cdots \\
&= \displaystyle \frac{\frac{(1+G)D_0}{(1 + \tilde R)}}{1 - \frac{1+G}{1+\tilde R}}\\
&= \displaystyle \frac{\frac{(1+G)}{(1 + \tilde R)}D_0}{\frac{(1+ \tilde R) - (1+G)}{1+\tilde R}}\\
%&= \displaystyle \frac{\frac{(1+G)}{(1 + \tilde R)}D_0}{\frac{\tilde R - G}{1+\tilde R}}\\
&= \displaystyle \frac{1+G}{\tilde R - G}D_0\\
\end{aligned}
$$
ただし,$\tilde{R} \not = G$の場合のみである。
:::
### 割引率と期待リターンの関係
割引率$R$は投資家が将来キャッシュフローを購入するにあたって最低限要求する期待リターン(**要求収益率**)とも解釈できます。
これくらいリスクのある投資をするのだから,リスクのない資産への投資よりも高いリターンを要求する,という考えを反映しています。
## 平均分散アプローチ入門
個々の投資家にとって<span class="markp">最適となる証券の組み合わせの比率を決めることを**最適ポートフォリオ選択**</span>といいます。
<span class="markp">ポートフォリオの価値をリターンの期待値と分散で評価する</span>考え方を**平均・分散アプローチ**といいます。
### ポートフォリオのリスクとリターン
1. 投資対象が銘柄Aと銘柄Bの2銘柄のみが投資対象であるケース
2. 各銘柄への投資割合を$w_A$と$w_B$
3. $w_A + w_B = 1$
記号の定義は以下の通りです。
- 元本 $X$
- 投資銘柄Aのリターン $1 + R_A$
- 投資銘柄Bのリターン $1 + R_B$
::: {.callout-note}
リターンの定義$(P_t - P_{t-1})/P_{t-1} = P_t/P_{t-1} -1$は**ネット・リターン**(net return)と呼ばれるものである。
これにたいして,元本も含めたリターン$1 + R_t = P_t/P_{t-1}$は**グロス・リターン**(gross return)という。
:::
元本$X$のうち$w_A$分だけ銘柄Aに投資すると、1年後に期待値で$\mathbb{E}[X \times w_A \times (1+R_A)]$になります。
手元現金全額を銘柄AとBに振り分けると、
$$
\begin{aligned}
(1 + R_A) w_A X + ( 1 + R_B) w_B X
&= w_A X + w_A R_A X + w_B X + w_B R_B X\\
&= \left [\underbrace{(w_A+w_B)}_{\text{定義より} = 1}+(w_AR_A+w_BR_B) \right ]X\\
&= (1 + w_A R_A + w_B R_B)X
\end{aligned}
$$
となります。
この**1年後の価値と初期投資額の比**としてこのポートフォリオのリターン$1 + R_P$を計算します。
$$
\begin{aligned}
1 + R_P &= \frac{\overbrace{(1 + w_A R_A + w_B R_B)X}^{将来時点の評価額}}{\underbrace{X}_{初期投資}}\\
&= 1 + w_A R_A + w_B R_B\\
&= 1 + w_A R_A + w_B R_B\\
R_P &= w_A R_A + w_B R_B
\end{aligned}
$$
<span class="markp">ポートフォリオ構築時には、各銘柄の実現リターンはわからない</span>ので(つまり確率変数)、かわりに期待値や分散を評価します。
銘柄Aと銘柄Bのネット・リターンをそれぞれ$R_A$と$R_B$で表すと,期待値,分散,標準偏差は次のようになります。
- 期待値 $\mathbb{E}[R_A] = \mu _A$,$\mathbb{E}[R_B] = \mu_B$
- 分散 $\mathbb{V}[R_A] = \sigma^2_A$,$\mathbb{V}[R_B] = \sigma^2_B$
- 共分散 $\mathbb{Cov}[R_A, R_B] = \sigma_{AB}$
- 相関係数 $\rho = \frac{\sigma_{AB}}{\sigma_A \sigma_B}$
$$
\begin{aligned}
% \rho &= \frac{\mathbb{E}[(R_A - \bar R_A)(R_B - \bar R_B)]}{\mathbb{E}[(R_A - \bar R_A)^2]}
\rho &= \frac{\sigma _{AB}}{\sigma _A \times \sigma _B} \\
\sigma_{AB} & = \rho\sigma_A\sigma_B
\end{aligned}
$$
と表せます。
上の式より、ポートフォリオのリターンは$R_P = w_A R_A + w_B R_B$ なので、
ポートフォリオのリターンの期待値 $\mathbb{E}[R_P] = \mu_P$ も各銘柄の期待リターンの加重平均となります。
ここで投資割合$w_A$と$w_B$は定数であり,$R_A, R_B$は確率変数です。
$$
\begin{aligned}
\mathbb{E}[R_p] = \mu_P &= \mathbb{E}[w_A R_A + w_B R_B]\\
&= w_A \mathbb{E}[R_A] + w_B \mathbb{E}[R_B]\\
&=w_A\mu_A+w_B\mu_B
\end{aligned}
$$
つぎに,ポートフォリオのリターン$R_P$の分散$\mathbb{V}[R_P] = \sigma^2_P$は各銘柄の分散及び相関係数を用いて計算できます。
$$
\begin{aligned}
\mathbb{V}[R_P] = \sigma_P^2 &= \mathbb{V}[w_A R_A + w_B R_B]\\
&= w_A^2 \mathbb{V}[R_A] + w_B^2 \mathbb{V}[R_B] + 2 w_A w_B \mathbb{Cov}[R_A,R_B]\\
&= w_A^2 \sigma_A^2 + w_B^2 \sigma_B^2 + 2w_A w_B \sigma _{AB}\\
&= w^2_A \sigma^2_A + w^2_B \sigma^2_B +
\underbrace{2 w_A w_B \rho \sigma_A \sigma_B}_{ここの\rho の符号が重要}
\end{aligned}
$$
:::{.callout-tip}
## 確率変数の分散
確率変数$X$と$Y$の線形結合$aX + bY$の分散は次のように計算できます。
$$
\begin{aligned}
\mathbb{V}(aX + bY) &= \mathbb{E}\left[ \{ (aX + bY) - \mathbb{E}[aX + bY] \}^2 \right] \\
&= \mathbb{E}\left[ \{ (aX + bY) - (a\mu_X + b\mu_Y) \}^2 \right] \\
&= \mathbb{E}\left[ \{ a(X - \mu_X) + b(Y - \mu_Y) \}^2 \right] \\
&= \mathbb{E}\left[ a^2(X - \mu_X)^2 + 2ab(X - \mu_X)(Y - \mu_Y) + b^2(Y - \mu_Y)^2 \right] \\
&= a^2 \mathbb{E}\left[ (X - \mu_X)^2 \right] + 2ab \mathbb{E}\left[ (X - \mu_X)(Y - \mu_Y) \right] + b^2 \mathbb{E}\left[ (Y - \mu_Y)^2 \right] \\
&= a^2 \mathbb{V}(X) + b^2 \mathbb{V}(Y) + 2ab \mathrm{Cov}(X, Y)
\end{aligned}
$$
:::
ポートフォリオPの分散 $\mathbb{V}(R_P)$ は,各銘柄の分散に投資割合の二乗を乗じたものに,各銘柄のリターンの相関関係部分を加えたものとなっていることが分かります。
つまり,この2銘柄のリターンの相関係数$\rho$に応じて,ポートフォリオPの分散が大きくなるかどうかが決まる,ということです。
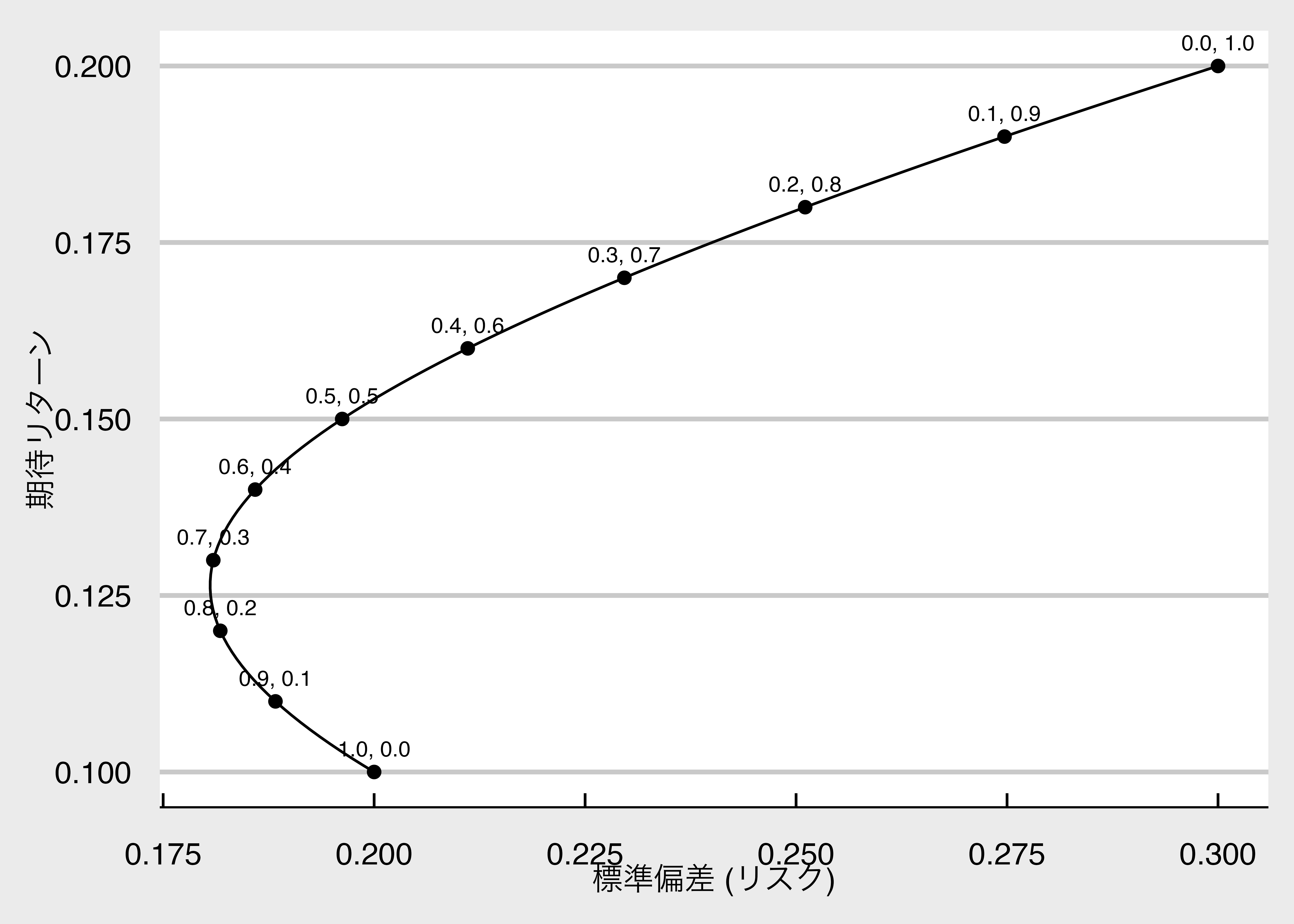
### 分散投資のメリット
保有比率$(w_A, w_B)$を変化させたときのポートフォリオの$\mu_P$と$\sigma_P$がどのように変化するかを確認しましょう。
分散は非負の値をとることに注意してください。
$$
\begin{aligned}
\mathbb{V}[R_P] = \sigma_P^2 &= w^2_A \sigma^2_A + w^2_B \sigma^2_B + 2\rho{w_Aw_B\sigma_A\sigma_B}\\
&= (w_A \sigma_A + w_B \sigma_B)^2 - 2w_A w_B \sigma _A \sigma_B + 2\rho{w_Aw_B\sigma_A\sigma_B}\\
% &= (w_A \sigma_A + w_B \sigma_B)^2 - (2 + 2\rho ) w_A w_B\sigma_A\sigma_B\\
&=\underbrace{(w_{A} \sigma_{A} + w_{B}\sigma_{B})^{2}}_{>0} - \underbrace{2(1-\rho )w_{A}w_{B} \sigma_{A}\sigma_{B}}_{ここ重要}
\end{aligned}
$$
$0 \leq w_{A} \leq 1$ かつ $0 \leq w_{B} \leq 1$ ,$w_A + w_B = 1$ のとき、
$$
2 ( 1- \rho ) w_A w_B \sigma _A \sigma _B \geq 0
$$
となります。
$\rho = 1$のときのみ等号で成立します。
したがって、$-1 \leq \rho < 1$ のとき、$( 1- \rho ) w_A w_B \sigma _A \sigma _B > 0$ となり,次の不等式が成立します。
$$
\begin{aligned}
\sigma_P^2 &= (w_{A}\sigma_{A}+w_{B}\sigma_{B})^{2} - \underbrace{2(1-\rho )w_{A}w_{B} \sigma_{A}\sigma_{B}}_{> 0}\\
\Longleftrightarrow \sigma _P^2 &\leq (w_A \sigma _A + w_B \sigma _B)^2 \\
\Longleftrightarrow \sigma_{P} & \leq
\underbrace{w_{A}\sigma_{A}+w_{B}\sigma_{B}}_{リスクの加重平均}
\end{aligned}
$$
となり,ポートフォリオのリスクを表す標準偏差$\sigma_P$が銘柄AとBの標準偏差の加重平均$w_{A}\sigma_{A} + w_{B} \sigma_{B}$以下になることがわかります。
これを**分散投資効果**という。
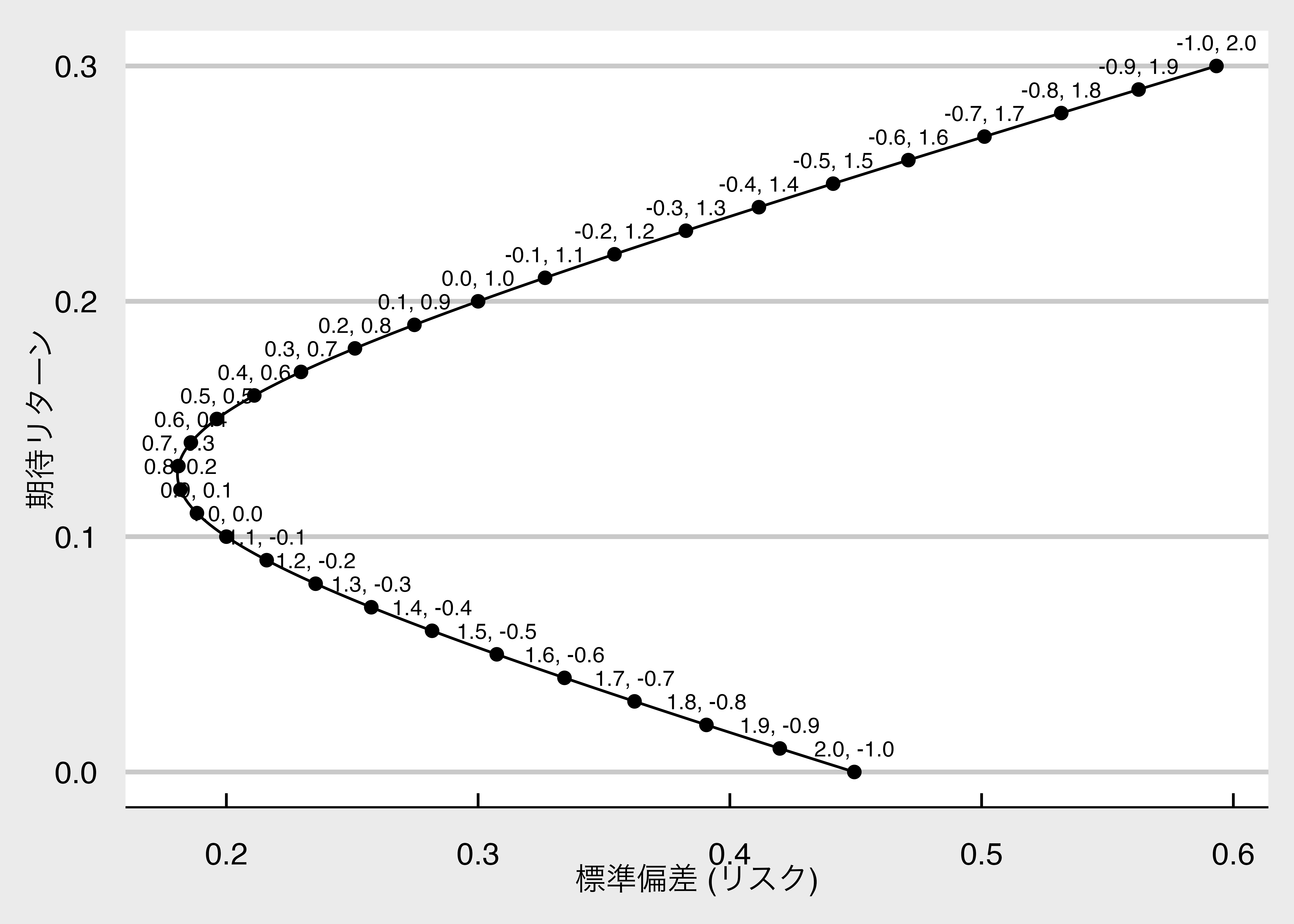
```{r diversified_investment, filename="分散投資効果 p.65"}
#| code-fold: true
# パラメータ設定
params <- list(
mu_A = 0.1, sigma_A = 0.2,
mu_B = 0.2, sigma_B = 0.3,
rho = 0.2
)
# データの生成
df_portfolio <- tibble(
wa = seq(0, 1, by = 0.01),
wb = 1 - wa
) |>
mutate(
mu_p = wa * params$mu_A + wb * params$mu_B,
var_p = wa^2 * params$sigma_A^2 + wb^2 * params$sigma_B^2 +
2 * params$rho * wa * wb * params$sigma_A * params$sigma_B,
sigma_p = sqrt(var_p),
# ラベル作成: 0.1刻みの点のみラベルを付ける
label = if_else(round(wa * 100) %% 10 == 0,
sprintf("%.1f, %.1f", wa, wb),
NA_character_)
)
# 作図
ggplot(df_portfolio, aes(x = mu_p, y = sigma_p)) +
geom_line() +
geom_point(data = df_portfolio |> filter(!is.na(label)), size = 2) +
geom_text(aes(label = label), na.rm = TRUE, vjust = -1, size = 3) +
coord_flip() +
labs(x = "期待リターン", y = "標準偏差 (リスク)") +
mystyle
```
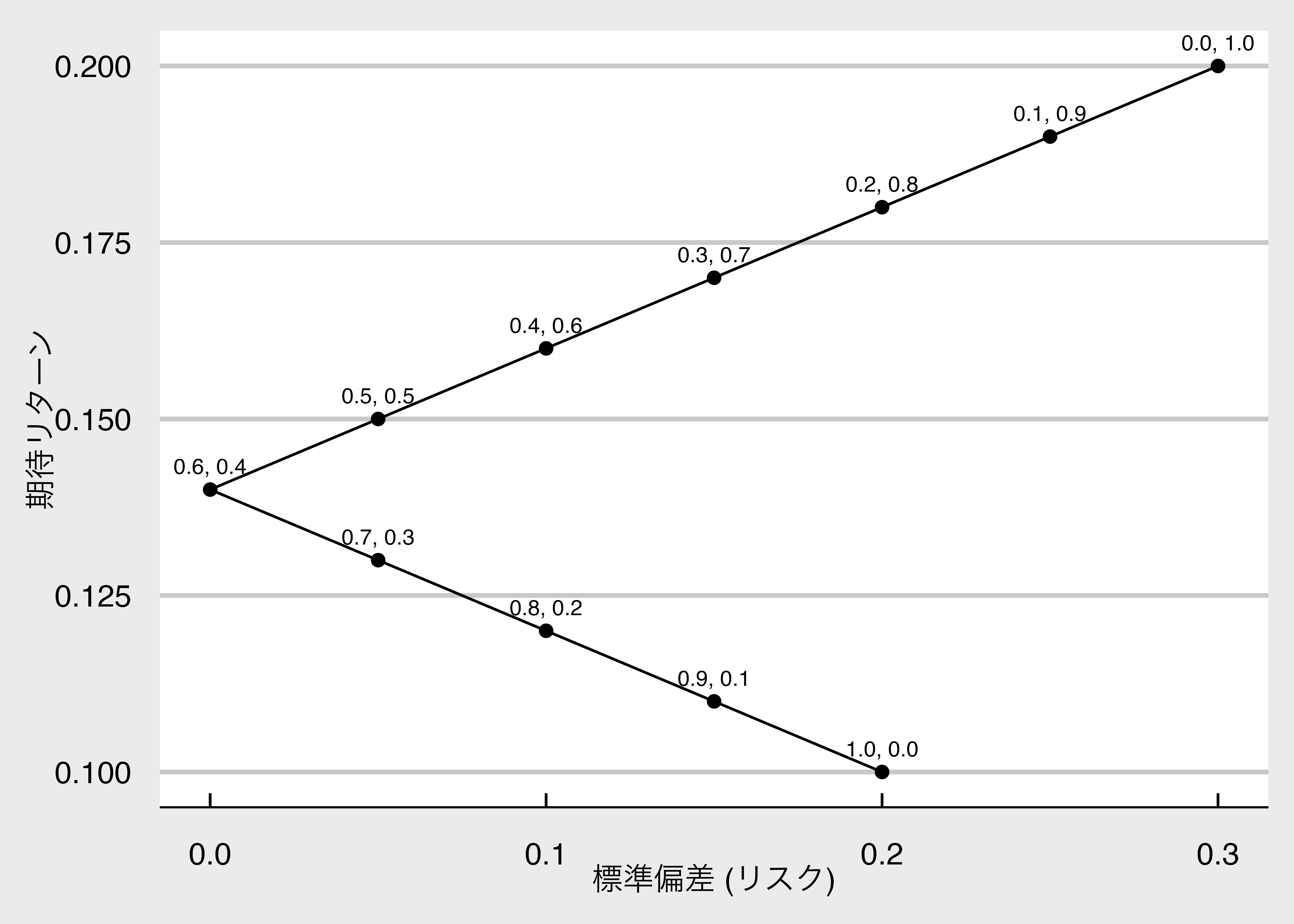
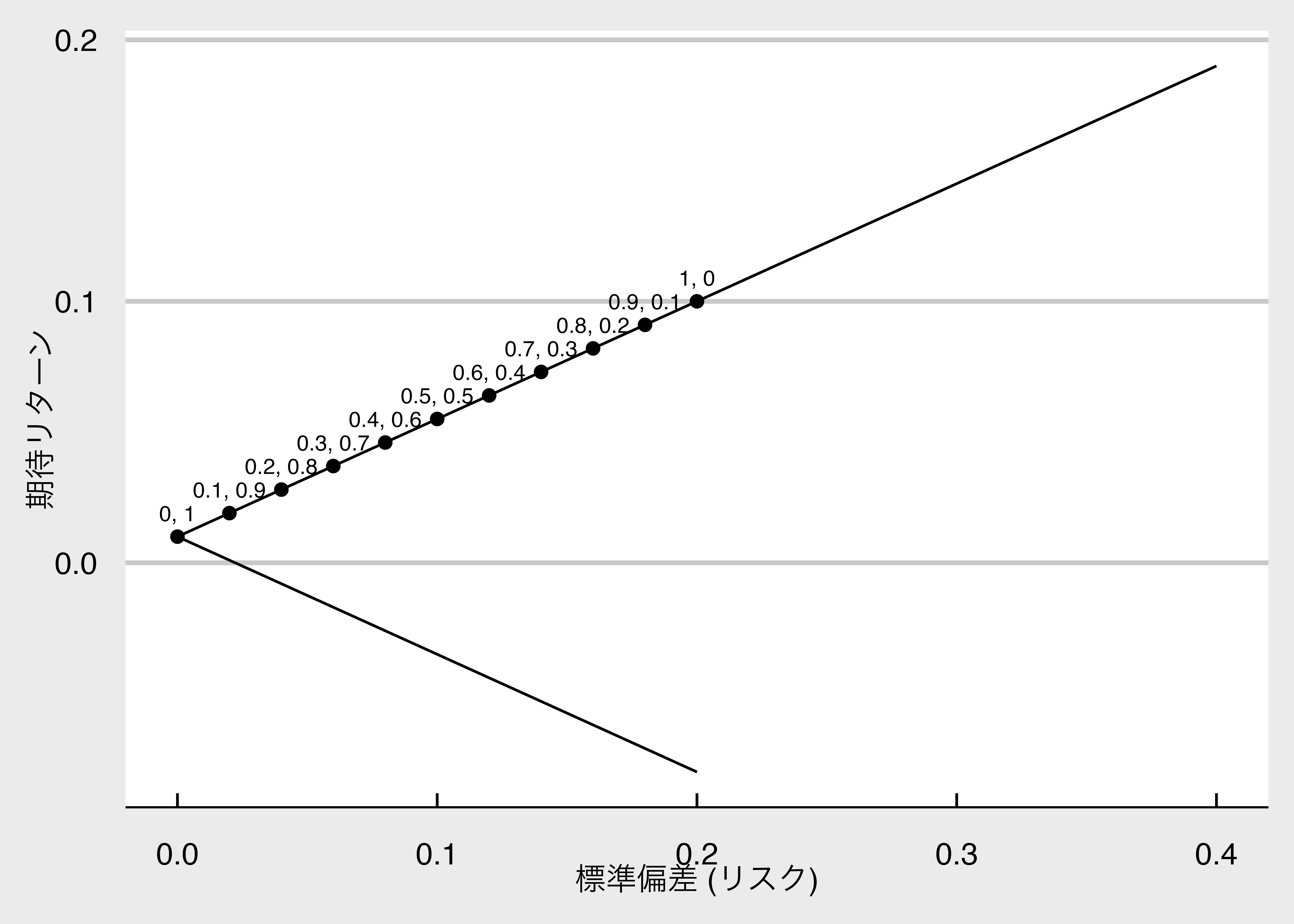
完全な負の相関$(\rho=-1)$であるの場合、$\sigma^{2}_{P}=0$のポートフォリオを構築できる。
確認のため、2銘柄の価格が完全な負の相関$\rho = -1$をもつとき、ポートフォリオPのリスク$\sigma_P$は
$$
\begin{aligned}
\mathbb{V}[R_P] = \sigma ^2_P &=(w_{A}\sigma_{A}+w_{B}\sigma_{B})^{2}-2(1- (-1))w_{A}w_{B} \sigma_{A}\sigma_{B}\\
&= (w_{A}\sigma_{A}+w_{B}\sigma_{B})^{2} -4w_{A}w_{B} \sigma_{A}\sigma_{B}\\
&= w_A ^2 \sigma _A^2 + w_B^2\sigma _B^2 + 2w_A w_B \sigma_A \sigma_B -4w_{A}w_{B} \sigma_{A}\sigma_{B}\\
&= w_A ^2 \sigma _A^2 - 2w_{A}w_{B} \sigma_{A}\sigma_{B} + w_B^2\sigma _B^2 \\
&= (w_{A}\sigma_{A} - w_{B}\sigma_{B})^{2}\\
\sigma _P &= | w_{A}\sigma_{A} - w_{B}\sigma_{B}|
\end{aligned}
$$
以下のように,$w_A \sigma _A = w_B \sigma_B$となるように$w_A$と$w_B$を選べば、$\sigma _P = 0$となるポートフォリオを作れる。
```{r, filename="完全な負の相関の分散投資効果 p.65"}
#| code-fold: true
# パラメータ設定
params <- list(
mu_A = 0.1, sigma_A = 0.2,
mu_B = 0.2, sigma_B = 0.3
)
# データ生成
df_neg_corr <- tibble(
wa = seq(0, 1, by = 0.01),
wb = 1 - wa
) |>
mutate(
mu_p = wa * params$mu_A + wb * params$mu_B,
# 完全な負の相関の場合、標準偏差は加重平均の差の絶対値になる
sigma_p = abs(wa * params$sigma_A - wb * params$sigma_B),
# ラベル作成: 0.1刻みの点のみラベルを付ける
label = if_else(round(wa * 100) %% 10 == 0,
sprintf("%.1f, %.1f", wa, wb),
NA_character_)
)
# 作図
ggplot(df_neg_corr, aes(x = mu_p, y = sigma_p)) +
geom_line() +
geom_point(data = df_neg_corr |> filter(!is.na(label)), size = 2) +
geom_text(aes(label = label), na.rm = TRUE, vjust = -1, size = 3) +
coord_flip() + # 縦軸をリターン、横軸をリスクにするため入れ替え
labs(x = "期待リターン", y = "標準偏差 (リスク)") +
mystyle
```
このケースでは、$\sigma_A = 0.2$、$\sigma_B = 0.3$となっているため、$0.2w_A = 0.3w_B$となる保有割合を考える。
$$
\begin{aligned}
0.2 w_A &= 0.3w_B\\
0.2 w_A &= 0.3(1-w_A)\\
0.2 w_A &= 0.3 - 0.3w_A\\
0.5 w_A &= 0.3\\
w_A &= 0.6
\end{aligned}
$$
となるため、銘柄Aに60%、銘柄Bに40%を投資することで、リスクゼロで期待リターン$0.6\times0.1 + 0.4 \times 0.2 = 0.14$を獲得することができる。
### 空売りの効果
空売り(short sale)とは、
1. 保有していない証券を誰か(普通は証券会社)から借りてきて売却し、
2. 一定期間後に買い戻して元の持ち主に返却する
取引をいい、**値下がりから利益を得る**。
空売りを行う投資家をショートセラー(short seller)という。
いままでは、$0 \leq w_A,w_B \leq 1$ という制約を置いていたが、この制約をはずして $w_A + w_B = 1$ のみを課す。
つまり$w_A < 0$や$w_B < 0$が空売りを表す。
```{r short_sale_effect, filename="空売りの効果 p.66"}
#| code-fold: true
# パラメータ設定
params <- list(
mu_A = 0.1, sigma_A = 0.2,
mu_B = 0.2, sigma_B = 0.3,
rho = 0.2
)
# データ生成
df_short <- tibble(
wa = seq(-1, 2, by = 0.01), # 空売りを考慮して範囲拡大
wb = 1 - wa
) |>
mutate(
mu_p = wa * params$mu_A + wb * params$mu_B,
sigma_p = sqrt(wa^2 * params$sigma_A^2 + wb^2 * params$sigma_B^2 +
2 * params$rho * wa * wb * params$sigma_A * params$sigma_B),
wa_int = round(wa * 100), # 100倍して整数化
# 条件:
# 1. wa が -1 以上 2 以下 (wa_int が -100 ~ 200)
# 2. wa が 0.1 刻み (wa_int が 10 で割り切れる)
is_label_target = (wa_int >= -100 & wa_int <= 200) & (wa_int %% 10 == 0),
label = if_else(is_label_target,
sprintf("%.1f, %.1f", wa, wb),
NA_character_)
)
# 作図
ggplot(df_short, aes(x = mu_p, y = sigma_p)) +
geom_line() +
# ラベルがある点(0 <= wa <= 1)のみポイントとテキストを表示
geom_point(data = df_short |> filter(!is.na(label)), size = 2) +
geom_text(aes(label = label), na.rm = TRUE, vjust = -1, size = 3) +
coord_flip() +
labs(x = "期待リターン", y = "標準偏差 (リスク)") +
mystyle
```
先ほどの空売りなしのケースと比べると,曲線が大きく広がっていることがわかります。
次に,安全資産を加えた3資産の場合を考えます。
### 安全資産の導入
**安全資産の購入**についても考える。
安全資産Fのリターンを$R_F$、ポートフォリオPの保有比率を$w_F$,銘柄Aと銘柄Bと安全資産の投資割合をそれぞれ$w_A, w_B, w_F$で表します。
まず銘柄Aと安全資産の2資産からなるポートフォリオを考えます。
各資産への投資割合を$w_A + w_F = 1, \quad w_B = 0$ とする場合を考える。
この安全資産と銘柄AからなるポートフォリオPの(ネット)リターン $\tilde R_P$ は,
$$
\tilde R_{P} = w_{F} R_{F} + w_{A} \tilde R_{A}
$$
となり,このポートフォリオの期待値は,
$$
\begin{aligned}
\mu_{P} =\mathbb{E}[R_P] &=\mathbb{E}[ w_F R_{F} + w_{A} \tilde{R_A} ]\\
&=w_F R_{F}+w_{A} \mathbb{E}[\tilde{R_A}]\\
&=w_F R_{F}+w_{A} \mu_{A}\\
&=(1-w_A) R_{F}+w_{A} \mu_{A}\\
&=R_{F} - w_{A}R_F + w_A\mu_A\\
&=R_{F} + w_A(\underbrace{\mu_A - R_F}_{\tiny リスクプレミアム})
\end{aligned}
$$
となります。
もちろん安全資産のリターンは定数なので,期待値をとってもそのままです。
$\mu_{A} - R_{F}$ はリスク資産である銘柄Aの**リスクプレミアム**を表しています。
通常,リスクのある資産の期待リターンは安全資産のリターンより大きいため,リスクプレミアムは正の値となります。
したがって,リスク資産への投資割合 $w_A$ を1単位増加させれば,$\mathbb{E}[R_P]$ はリスクプレミアム分増加する
つぎに,ポートフォリオのリスクを表す標準偏差 $\sigma _P$ とリターンの関係は次式で表せます。
まず安全資産のリスクはゼロであるため,リスク資産の銘柄Aを保有する分だけリスクが生じる。
$$
\begin{aligned}
\sigma_P^2 = \mathbb{V}[R_P] &= \mathbb{V}[w_FR_F + w_A R_A]\\
&= \mathbb{V}[w_A R_A]\\
&= w_A^2 \mathbb{V}[R_A]\\
&= w_A^2 \sigma _A^2 \\
\sigma _P & = |w_A| \sigma_A
\end{aligned}
$$
空売りを想定する場合$w_A < 0$となるため,標準偏差を求める際に絶対値をとっています。
空売りはない状況(つまり,$w_A>0$)を想定すると,
$$
\begin{aligned}
\sigma _P = w_A \sigma _A\\
w_A = \frac{\sigma_P}{\sigma _A}
\end{aligned}
$$
のように,リスク資産である銘柄Aへの投資割合$w_A$が,ポートフォリオPとリスク資産Aのリスクの割合で決定されることがわかります。
これを,ポートフォリオの期待リターン$\mu_P$に代入すると、
$$
\begin{aligned}
\mu_{P} &= R_F + w_A(\mu_A - R_F)\\
& = R_F + \frac{\sigma_P}{\sigma _A}(\mu_A - R_F) \\
&= R_{F}+\frac{\mu_{A}-R_{F}}{\sigma_{A}}\sigma_{P}
\end{aligned}
$$
となり,期待リターン$\mu_P$は,切片が$R_F$,傾きが$(\mu_A - R_F)/\sigma_A$とする$\sigma_P$の線形関数となる。
```{r safe_asset_allocation, filename="安全資産の導入 p.68"}
#| code-fold: true
# パラメータ設定
params <- list(
R_F = 0.01, # 安全資産利子率
mu_A = 0.1, # 銘柄A 期待リターン
sigma_A = 0.2 # 銘柄A 標準偏差
)
# データ生成
df_safe <- tibble(
wa = seq(-1, 2, by = 0.01) # 銘柄Aへの投資比率
) |>
mutate(
wf = 1 - wa, # 安全資産への投資比率
mu_p = params$R_F + wa * (params$mu_A - params$R_F),
sigma_p = abs(wa) * params$sigma_A, # 空売り時は絶対値
# ラベルの作成
wa_int = round(wa * 100),
is_label_target = (wa_int >= 0 & wa_int <= 100) & (wa_int %% 10 == 0),
label = if_else(is_label_target,
sprintf("%g, %g", wa, wf),
NA_character_)
)
# 作図
ggplot(df_safe, aes(x = mu_p, y = sigma_p)) +
geom_line() +
geom_point(data = df_safe |> filter(!is.na(label)), size = 2) +
geom_text(aes(label = label), na.rm = TRUE, vjust = -1, size = 3) +
coord_flip() +
labs(x = "期待リターン", y = "標準偏差 (リスク)") +
mystyle
```
### 3資産のポートフォリオ
リスク資産AとB,安全資産Fの3資産に投資するポートフォリオを考える。
ここで,$w_A + w_B > 0$を仮定し,少なくとも少しはリスク資産を保有するケースを考える。
当然だけれど,$w_A = w_B =0$のケースでは,安全資産のみを保有するケースとなり,リスクも無く,リターンも確定している。
3資産A,B,Fへの投資割合をそれぞれ$w_A$,$w_B$,$w_F$とすると,
3資産からなるポートフォリオの期待リターンは次のように計算できる。
$$
\begin{aligned}
\mathbb{E}[R_{P}] &= w_FR_F + w_A \mathbb{E} [\tilde R_A] + w_B \mathbb{E}[ \tilde R_B] \\
& =
w_{F} R_{F} + (w_{A} + w_{B}) \left(\frac{w_{A}}{w_{A}+w_{B}} \mathbb{E} [\tilde R_{A}] + \frac{w_{B}}{w_{A}+w_{B}} \mathbb{E}[ \tilde R_{B} ]\right)
\end{aligned}
$$
安全資産への投資割合$w_F$とリスク資産への投資割合$w_C = w_A + w_B$とまとめて,式を変形させる。
安全資産への投資以外の資金で構築したリスク資産AとBからなるポートフォリオを$P_C$を考えると,$P_C$の期待リターン$R_C$は次のように計算できる。
$$
\begin{aligned}
R_{C} &= \frac{w_{A}}{w_{A}+w_{B}} \mathbb{E}[\tilde R_{A}] + \frac{w_{B}}{w_{A}+w_{B}}\mathbb{E}[ \tilde R_{B}]\\
\end{aligned}
$$
安全資産FとポートフォリオCを保有した場合の期待リターンは次式となる。
$$
\begin{aligned}
\mu_{P} & = \mathbb{E}[w_F R_F + w_A R_A + w_B R_B]\\
&= w_FR_F + w_A \mathbb{E}[R_A] + w_B \mathbb{E}[R_B]\\
&= w_FR_F + (w_A + w_B) \underbrace{ \left( \frac{w_A}{w_A + w_B} \mathbb{E}[R_A] + \frac{w_B}{w_A + w_B} \mathbb{E}[R_B] \right )}_{=w_C\text{とおく}}\\
&= w_F R_F + w_{C}\mu_C
\end{aligned}
$$
安全資産と2つのリスク資産からなるポートフォリオの期待リターンは,安全資産の期待リターンとリスク資産の期待リターンの和となる。
安全資産と2つのリスク資産に投資可能な場合,$(\mu_P, \sigma _P)$の取りうる値を図示できる。テキストの数値例を用いてRで図示してみる。
- リスク資産Aの期待リターン 0.1,標準偏差 0.2
- リスク資産Bの期待リターン 0.2,標準偏差 0.3
- 安全資産の期待リターンを 0.01
- リスク資産AとBの間の相関係数は0.2
- 安全資産,銘柄A,銘柄Bへの投資割合を0.2,0.3,0.5とするポートフォリオを考える。このポートフォリオの期待リターン$\mu_P$と標準偏差$\sigma_P$は次のようになる。
## 最適ポートフォリオ問題
「どのようなポートフォリオが投資家にとって望ましいか」
一般に、投資家はリスクが小さい一方でリターンが大きいポートフォリオを好む。
ここでは,リターンをポートフォリオの期待リターン$\mu_P$,リスクをポートフォリオの標準偏差$\sigma _P$で表し,この2つの変数から構成される平面$(\mu_P, \sigma_P)$上で最適ポートフォリオ問題を分析する。
### 効率的フロンティア
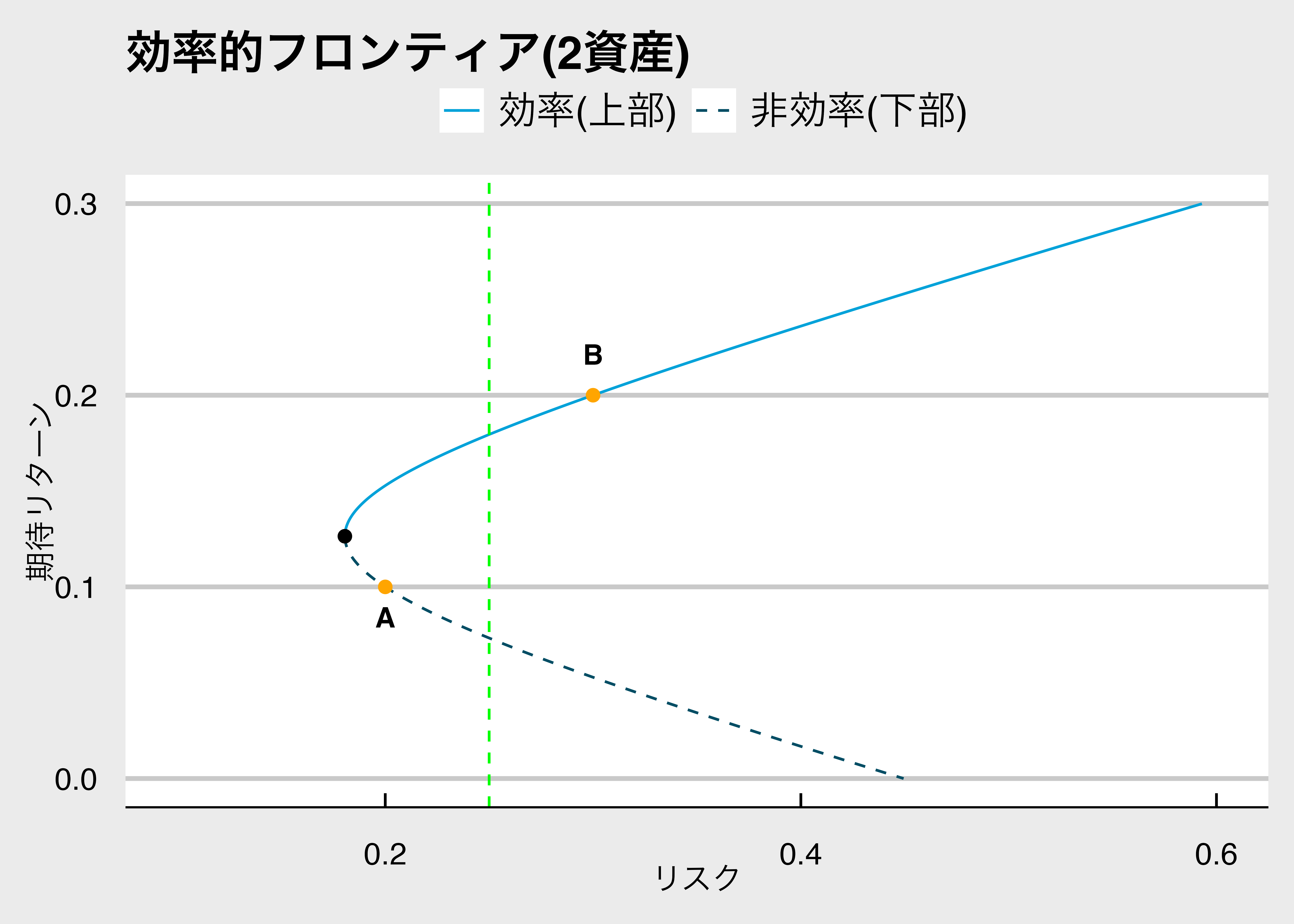
リスク資産Aと資産Bにのみ投資可能であり,それぞれに異なる割合で投資したポートフォリオDとEを比較する(以下の図)
- 標準偏差はともに0.25 $\sigma _D = \sigma _E = 0.25$
- Dの方がEよりも期待リターンが大きい,$\mu _D > \mu _E$
つまり,<span class="markp">同じリスク(標準偏差)ならリターン(期待リターン)が高いポートフォリオに投資したほうがいいです</span>。
以下のグラフでいうと、同じリスク(緑のライン上)なら、リターンの高いポートフォリオが望ましい。そのため青い線が効率的フロンティアとなり、点線は選択されないポートフォリオになります。
```{r graph_efficient_frontier_modern, filename="効率的フロンティア"}
#| code-fold: true
# --- 1. パラメータ設定 ---
params <- list(
mu_A = 0.1, sigma_A = 0.2, # 株式Aの標準偏差
mu_B = 0.2, sigma_B = 0.3, # 株式Bの標準偏差
rho = 0.2 # 相関係数
)
# --- 2. 最小分散ポートフォリオ (MVP) の算出 ---
# 分散・共分散
cov_ab <- params$rho * params$sigma_A * params$sigma_B
var_a <- params$sigma_A^2
var_b <- params$sigma_B^2
# MVPにおける資産Aのウェイト w_mvp
# 公式: w = (Var(B) - Cov(A,B)) / (Var(A) + Var(B) - 2Cov(A,B))
w_mvp <- (var_b - cov_ab) / (var_a + var_b - 2 * cov_ab)
# MVPのリターンとリスク(しきい値として使用)
mu_mvp <- w_mvp * params$mu_A + (1 - w_mvp) * params$mu_B
sigma_mvp <- sqrt(w_mvp^2 * var_a + (1 - w_mvp)^2 * var_b + 2 * w_mvp * (1 - w_mvp) * cov_ab)
# --- 3. プロット用データの作成 ---
df_plot <- tibble(
w = seq(-1, 2, by = 0.001)
) |>
mutate(
mu_p = w * params$mu_A + (1 - w) * params$mu_B,
sigma_p = sqrt((w * params$sigma_A)^2 +
((1 - w) * params$sigma_B)^2 +
2 * w * (1 - w) * cov_ab),
frontier_type = if_else(mu_p >= mu_mvp, "効率(上部)", "非効率(下部)")
)
# --- 4. プロット作成 ---
ggplot(df_plot, aes(x = sigma_p, y = mu_p)) +
geom_path(
aes(color = frontier_type,
linetype = frontier_type)
) +
geom_vline(xintercept = 0.25, color = "green", linetype = "dashed") +
# 資産A (緑)
annotate("point", x = params$sigma_A, y = params$mu_A, color = "orange", size = 2) +
annotate("text", x = params$sigma_A, y = params$mu_A, label = "A", vjust = 2, fontface = "bold") +
# 資産B (オレンジ)
annotate("point", x = params$sigma_B, y = params$mu_B, color = "orange", size = 2) +
annotate("text", x = params$sigma_B, y = params$mu_B, label = "B", vjust = -1.5, fontface = "bold") +
# 最小分散ポートフォリオ MVP (黒)
annotate("point", x = sigma_mvp, y = mu_mvp, color = "black", size = 2) +
# C. 見た目の調整
scale_color_manual(values = c("効率(上部)" = "red", "非効率(下部)" = "blue")) +
scale_linetype_manual(values = c("効率(上部)" = "solid", "非効率(下部)" = "dashed")) +
labs(title = "効率的フロンティア(2資産)",
x = "リスク",
y = "期待リターン",
color = "",
linetype = "") +
mystyle +
xlim(0.1, 0.6) + ylim(0.0, 0.3)
```
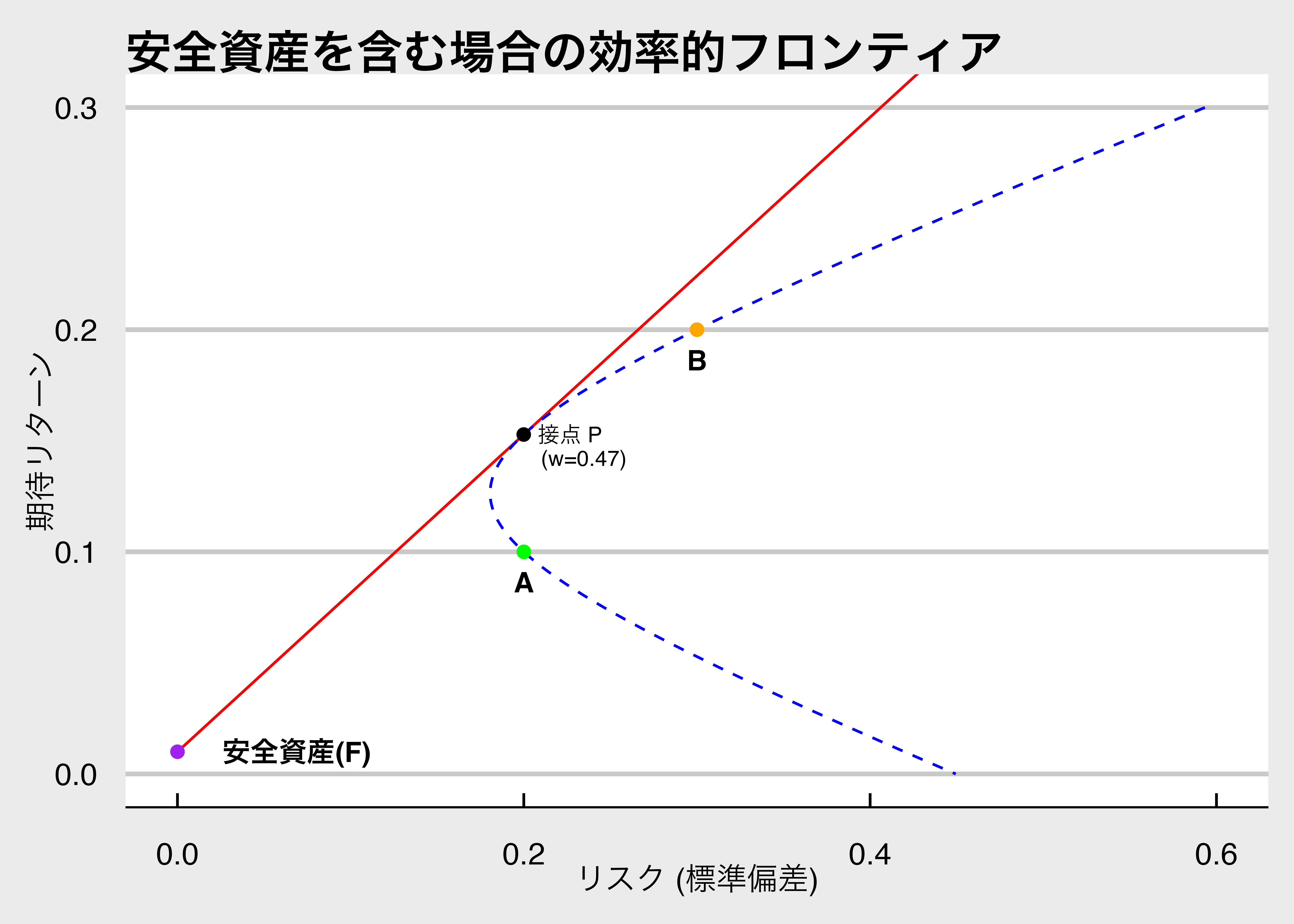
<span class="markp">リスク資産AとBに加え、安全資産Fにも投資可能な場合、効率的フロンティアは**直線**になります。</span>
この効率的フロンティアは**資本市場線**(Capital Market Line; CML)とも呼ばれます。
資本市場線の傾きは、この金融市場における**リスクとリターンのトレードオフ**を表しているといえます。
```{r graph_cml_fixed_coord, filename="3資産の効率的フロンティア"}
#| code-fold: true
# --- 1. パラメータ設定 ---
params <- list(
mu_A = 0.1, sigma_A = 0.2,
mu_B = 0.2, sigma_B = 0.3,
rho = 0.2, R_F = 0.01
)
# --- 2. データの作成 ---
# 2-1. リスク資産のみのフロンティア
df_frontier <- tibble(
w = seq(-1, 2, by = 0.001)
) |>
mutate(
mu_p = w * params$mu_A + (1 - w) * params$mu_B,
sigma_p = sqrt((w * params$sigma_A)^2 + ((1 - w) * params$sigma_B)^2 +
2 * w * (1 - w) * params$rho * params$sigma_A * params$sigma_B),
sharpe_ratio = (mu_p - params$R_F) / sigma_p
)
# 2-2. 接点ポートフォリオ
tangency_port <- df_frontier |> slice_max(sharpe_ratio, n = 1)
# 2-3. 資本市場線 (CML)
df_cml <- tibble(
sigma_p = c(0, 0.6),
mu_p = c(params$R_F, params$R_F + tangency_port$sharpe_ratio * 0.6)
)
# --- 3. プロット作成 ---
ggplot() +
# A. 資本市場線 (CML)
geom_line(
data = df_cml,
aes(x = sigma_p, y = mu_p),
color = "red"
) +
# B. リスク資産のみのフロンティア
geom_path(
data = df_frontier,
aes(x = sigma_p, y = mu_p),
color = "blue",
linetype = "dashed"
) +
# C. ポイントの描画
# 資産A
annotate("point", x = params$sigma_A, y = params$mu_A, color = "green", size = 2) +
annotate("text", x = params$sigma_A, y = params$mu_A, label = "A", vjust = 2, fontface = "bold") +
# 資産B
annotate("point", x = params$sigma_B, y = params$mu_B, color = "orange", size = 2) +
annotate("text", x = params$sigma_B, y = params$mu_B, label = "B", vjust = 2, fontface = "bold") +
# 安全資産
annotate("point", x = 0, y = params$R_F, color = "purple", size = 2) +
annotate("text", x = 0, y = params$R_F, label = "安全資産(F)", hjust = -0.3, fontface = "bold") +
# 接点ポートフォリオ
annotate("point", x = tangency_port$sigma_p, y = tangency_port$mu_p, color = "black", size = 2) +
annotate("text", x = tangency_port$sigma_p, y = tangency_port$mu_p,
label = paste0("接点 P \n(w=", sprintf("%.2f", tangency_port$w), ")"),
hjust = -0.2, vjust = 0.8, lineheight = 0.9, size = 3) +
# D. テーマなどの設定
labs(title = "安全資産を含む場合の効率的フロンティア",
x = "リスク (標準偏差)",
y = "期待リターン") +
# 【修正】データを消さずにズームするために coord_cartesian を使用
coord_cartesian(xlim = c(0, 0.6), ylim = c(0, 0.3)) +
# テーマ設定
theme_economist_white(base_family = "HiraKakuProN-W3") +
theme(
text = element_text(size = 12),
axis.title = element_text(size = 12),
legend.position = "none"
)
```
安全資産が利用可能な場合、投資家は「安全資産」と「任意のリスク資産ポートフォリオ」を組み合わせることができます。
先ほどの式で確認した通り、安全資産とあるポートフォリオを組み合わせると、リスク・リターン平面上では直線が描かれます。
では、投資家はどのリスク資産ポートフォリオと安全資産を組み合わせるべきでしょうか?
図の紫の点(安全資産 $R_F$)からスタートします。
そこから、青い点線(リスク資産のみのフロンティア)上の任意の点に向けて直線を引くことができます。
投資家は、同じリスクならより高いリターンを好むため、傾きが最も急になる直線を選ぼうとします。
その直線とは、安全資産の点から伸び、リスク資産のフロンティアに接する直線(赤い実線)となります。
この接点となるポートフォリオを**接点ポートフォリオ**(Tangency Portfolio)と呼びます。
この赤い直線上の組み合わせは、青い曲線上のどの点よりも(接点を除いて)左上に位置するため、より効率的です。
したがって、安全資産が存在する場合の効率的フロンティアはこの**直線(資本市場線)**となります。
::: {.callout-note title="【直感的理解】なぜ曲線ではなく直線が最強なのか?"}
この理屈は、**「ピンと定規」**を使うと直感的に理解できます。
1. **リスク資産のエリア(青い曲線)** <br>
これまで見てきた双曲線(青い点線)は、株式などのリスク資産だけで作れる限界ラインでした。
投資家はこのライン上のどこかを選ぶしかありませんでした。
2. **安全資産(紫の点)** <br>
ここに「リスクゼロでお金が増える」安全資産($R_F$)が登場します。
これはグラフの左端(リスク0)の軸上にピンを刺すようなものです。
3. **混ぜると「直線」になる** 安全資産と、あるリスク資産を混ぜてポートフォリオを作ると、
グラフ上ではその2点を結ぶ直線が描かれます。
投資家は、安全資産のピン($R_F$)を支点にして、定規をリスク資産のエリア(青い曲線)に向けて伸ばすことができます。
4. **定規を跳ね上げる(最適化)** 投資家は「同じリスクなら、できるだけ高いリターン」を欲しがります。
つまり、$R_F$に刺したピンを支点にして、定規の角度をできるだけ急にして、グイッと上に持ち上げたいと考えます。
- 定規が曲線の内側を通るとき(割線):もっと上にいけます。
- 定規が曲線から離れてしまったとき:そのような商品は存在しないので買えません。
定規を限界まで上に持ち上げたとき、定規は青い曲線の一番出っ張った部分に「ピタリ」と接するはずです。この**「接した状態の直線」**こそが、物理的に可能な範囲で最もリターン効率が良いライン(効率的フロンティア)となります。
そして、その接点にあるのが「接点ポートフォリオ」です。
これ以外の青い曲線上の点は、すべてこの直線の下側(=効率が悪い)に来てしまうため、選ばれなくなります。
:::
<!-- 以下では,各資産のパラメータを変更したら,効率的フロンティアや接点ポートフォリオがどのように変化するかを確認できるインタラクティブなグラフを示します。 -->
### 投資家のリスク回避度と最適ポートフォリオ
効率的フロンティアのうち、どの点が投資家の最適ポートフォリオになるのか,について考える。
そのためには投資家のリスク・リターンのトレードオフに関する**選好(preference)**の特徴,つまり**リスクの回避度**の情報が必要となる。
$(\mu_P,\rho_p)$平面上でそれを描く方法の一つが**無差別曲線**(indifference curve)である。
**無差別曲線**とは,投資家の効用(utility)が**一定**となるリスクとリターンの組み合わせを描いた曲線をいう。つまり同じ効用水準を達成できるリスクとリターンの組み合わせを表現した曲線である。
#### 効用関数の例
以下では,財$x$と$y$を消費したときの効用$U$を図示しています。
この消費者の効用関数は$U(x,y) = x^{\frac 25} \times y^{\frac 35}$としている。
:::{.column-margin}
なぜこのような設定にしているのかというと,この効用関数は**限界代替率逓減**(diminishing marginal rate of substitution)を満たしており,たくさん消費すると効用が増えるが,その増え方がだんだん小さくなる,という現実をよく表している性質を持っているからです。
:::
```{r utility_intersection_line_with_contours}
#| code-fold: true
#| warning: false
#| message: false
# 1. 効用関数のデータ作成
x <- 1:50
y <- 1:50
u_func <- function(x, y) { x^(2/5) * y^(3/5) }
U <- outer(x, y, u_func)
# 2. 予算制約面のデータ作成
bc_x_vec <- seq(0, 25, length.out = 50)
bc_z_vec <- seq(0, 50, length.out = 50)
bc_x_mat <- matrix(rep(bc_x_vec, times = 50), nrow = 50, ncol = 50)
bc_z_mat <- matrix(rep(bc_z_vec, each = 50), nrow = 50, ncol = 50)
bc_y_mat <- (100 - 4 * bc_x_mat) / 6
# 3. 交線のデータ作成
line_x <- seq(0, 25, length.out = 100)
line_y <- (100 - 4 * line_x) / 6
line_z <- u_func(line_x, line_y)
# 4. 描画
plot_ly() |>
# (A) 効用関数の曲面 + 等高線
add_surface(
x = ~x, y = ~y, z = ~U,
opacity = 0.6,
colorscale = "Viridis",
name = "効用関数",
showscale = FALSE, # 【追加】カラーバー(色の凡例)を消す
contours = list(
z = list(
show = TRUE,
usecolormap = TRUE,
highlightcolor = "#ff0000",
project = list(z = TRUE)
)
)
) |>
# (B) 予算制約面
add_surface(
x = bc_x_mat,
y = bc_y_mat,
z = bc_z_mat,
opacity = 0.3,
colorscale = list(c(0, 1), c("blue", "blue")),
showscale = FALSE, # 元からある設定(ここも消す)
name = "予算制約"
) |>
# (C) 交線
add_paths(
x = line_x, y = line_y, z = line_z,
line = list(width = 2, color = "red"),
name = "予算線上の効用"
) |>
layout(
title = "効用最大化:曲面・予算制約・無差別曲線",
showlegend = FALSE, # 【追加】項目名(線や面の名前)の凡例を消す
scene = list(
xaxis = list(title = "財 x"),
yaxis = list(title = "財 y"),
zaxis = list(title = "効用 U"),
camera = list(eye = list(x = -1.5, y = 1.5, z = 1.2))
)
)
```
この山のような部分が効用関数の曲面を表しており,$x$と$y$をたくさん消費すれば効用水準が高くなっています。
青い面は予算制約面を表しており,この面の上は予算を使い切って消費することを意味しています。
つまり青い面上の点で,もっとも満足度が高い場所が,最適消費点となります。
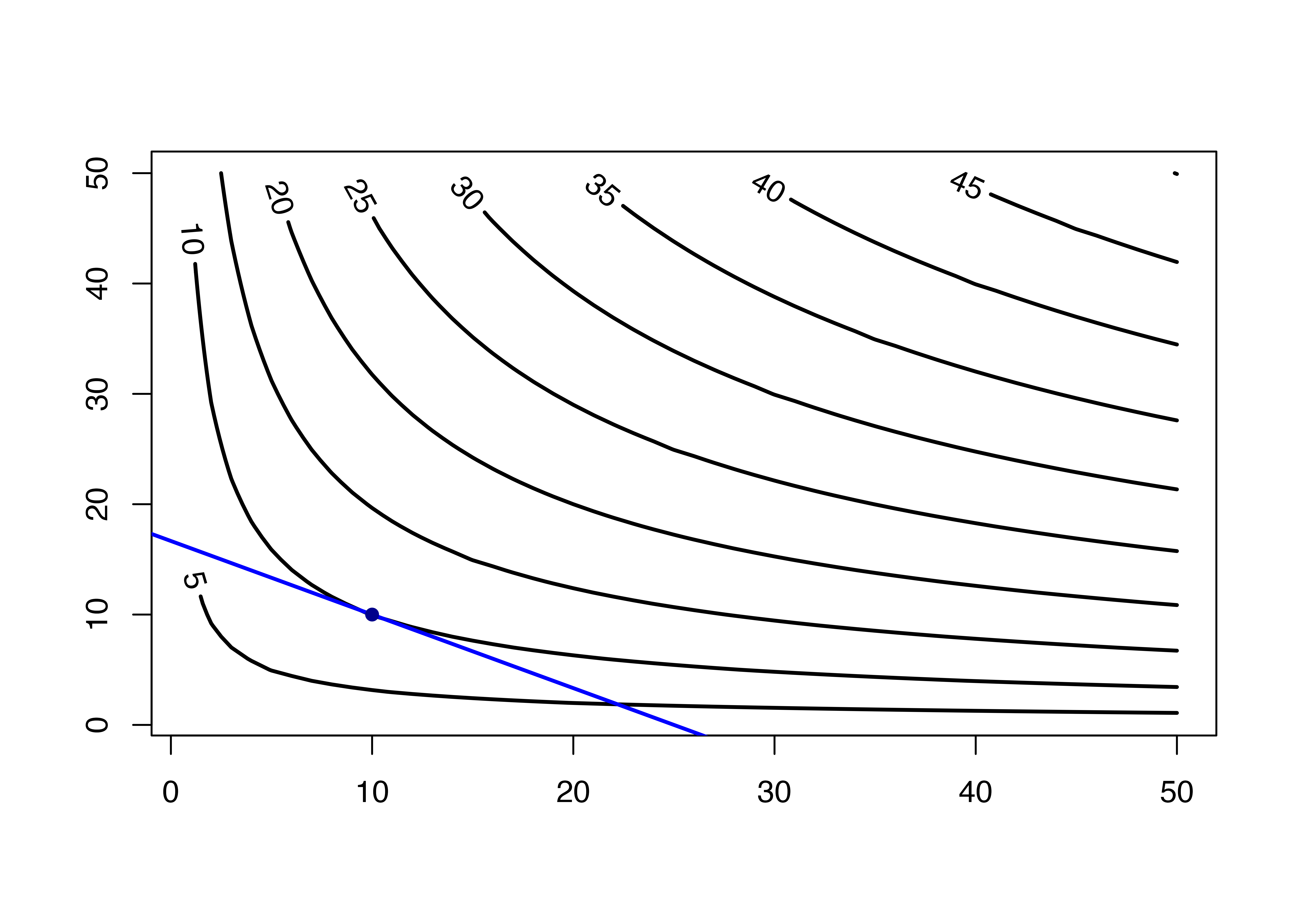
分かりやすくするために,この三次元の図を上から見た図を考えます。
青いラインは予算制約で,青い線の内側が**消費可能集合**(affordable set)となります。
右上に行くほど効用が高くなるので,予算制約と無差別曲線の接点が最適消費点となります。
```{r indifference_curve}
#| fig-cap: "無差別曲線と消費可能集合"
contour(x, y, U, method = "edge", labcex = 1, lwd = 2)
abline(a = 100/6, b = -4/6, lwd = 2, col = "blue") #予算制約線
points(x = 10, y = 10, lwd = 3, col = "darkblue", pch = 16) #最適消費点
```
無リスク利子率が10%で,リスクプレミアムが5%,$\beta$ が1.2の場合の期待リターンは,
$R_F + \beta \times (R_M - R_F) = 0.1 + 1.2 \times 0.05 = 0.16$ となります。
このときの無差別曲線は$U = 0.16$ となるようなリスクとリターンの組み合わせを表します。
<!-- リスクとリターンの無差別曲線 -->
<!--  -->
<!-- 複数のポートフォリオを比べるとき,この図の左上のものほど高リターン低リスクに対応するので、より高い効用水準が実現する。 -->
無差別曲線の**局所的な傾き**は、その投資家が追加的なリスクを引き受けるうえで要求するリスクプレミアム,つまり傾き=我慢料の相場を表しています。
したがって,リスク回避的な投資家ほど,リスクを1単位負担する際に,より大きなリスクプレミアムを要求するので、傾きは大きくなる,ということです。
無差別曲線と効率的フロンティアが接する点が、この投資家にとっての最適ポートフォリオとなります。
投資可能なポートフォリオの範囲で、最も左上の無差別曲線を実現するのが接点となる。
どの点が最適ポートフォリオとして選ばれるかは個々の投資家の無差別曲線の形状(リスク回避度)に依存する。最適ポートフォリオにおいて、無差別曲線と効率的フロンティアの局所的な傾きは一致(接線だから当然)するため、その投資家が要求するリスクプレミアムがちょうど実現されている。
上図の場合,この投資家の最適ポートフォリオは$(w_F,w_{tan})\approx(0.29,0.71)$の比率で構成される。
接点ポートフォリオは銘柄Aに47%、銘柄Bに53%投資するポートフォリオだったので、最適保有比率は、$(w_F,w_A,w_B)\approx(0.29,0.33,0.38)$と書き換えられる。
### トービンの分離定理
安全資産が投資可能な場合の最適ポートフォリオ問題を考える。
1. 接点ポートフォリオを求め、リスク資産同士の相対的な保有比率を求める。
2. 投資家ごとのリスク回避度に応じて安全資産と接点ポートフォリオの最適保有比率の決定
1は各投資家で共通している。
いったん接点ポートフォリオを求めてしまえば、他の投資家はその情報を用いて2を考えればよい。
最適ポートフォリオ問題を2段階に分離できるという命題は、**トービンの分離定理**(又は二基金分離定理)と呼ばれている。
## CAPM
金融市場全体の均衡を考えるために、**資本資産価格モデル**(Capital Asset Pricing Model; CAPM)を学習します。
### 仮定の確認
- **選好** : ポートフォリオを**期待値と標準偏差の基準で評価**
- **取引コスト** : 取引コストは存在せず、空売りも自由
- **流動性** : どれだけ売買しても証券の価格は不変
- **情報集合** : みんな同じ情報を共有
上記の仮定を満たす市場のことを、**完全資本市場**(完全市場: perfect market)と呼びます。
空想上の市場ですが、理論構築の大事な出発点です。
### CAPMの第一命題
先の仮定の下で、安全資産が投資可能なとき、全ての投資家の最適ポートフォリオ問題に対してトービンの分離定理を応用することができます。
全ての投資家は「安全資産」と「接点ポートフォリオ」のみに投資し、危険資産に限定すれば全員が同じ構成比率のポートフォリオ(接点ポートフォリオ)を保有します。
金融市場全体の均衡を議論するうえで、市場にその資産が供給されている以上、誰かがその最適ポートフォリオの一部として保有しているはずです。
すなわち、需要と供給が一致している点がポイントです。
以上の議論をよりフォーマルに述べるために、市場ポートフォリオを導入します。
::: {.callout-important}
## 市場ポートフォリオ
**市場ポートフォリオ (market portfolio)** とは、市場に存在する全ての危険資産を時価総額比率で保有したポートフォリオをいう。厳密には、リスク資産には株式や債券に代表される金融資産の他、不動産や貴金属などの実物資産も含まれるが、実用上はTOPIXやS&P500といった株価指数と同一視されることが多い。
:::
::: {.callout-important}
## CAPMの第一命題
市場ポートフォリオは接点ポートフォリオと一致し、効率的フロンティア(資本市場線)上に位置する。
:::
投資家は市場ポートフォリオに投資するとき、$\sigma_M$ のリスクを背負う見返りとして、$R_F$ に加えて $\mu_M-R_F$ だけ追加的な報酬を期待します。
この追加的な報酬を**市場リスクプレミアム** (market risk premium) といいます。したがってこの命題の下では、資本市場線を市場リスクプレミアム $(\mu_M-R_F)$ を利用して、以下のように表せます。
$$
\mu_P = R_F + \frac{\mu_M - R_F}{\sigma_M} \sigma_P
$$
<!--  -->
前の章で用いたパラメータをそのまま考えます。
接点ポートフォリオの保有比率は概ね47%を銘柄Aに、53%を銘柄Bに投資する結果となりました。CAPMの第一命題によると、均衡した市場における銘柄AとBの時価総額比率は約0.47対0.53になっていなければなりません。
この命題に従えば、投資家は各銘柄の期待リターンや分散から接点ポートフォリオを計算する必要はなく、単に時価総額加重で市場ポートフォリオを保有すればよいことになります。
- **パッシブ運用:** 幅広い銘柄に分散投資し、市場平均と同じようなパフォーマンスを目指す運用手法。
- **アクティブ運用:** 市場平均を上回るパフォーマンスを目指し、投資銘柄を絞ったり、投資比率を工夫したりする運用方法。
任意のポートフォリオの収益性を測る指標として、**シャープ・レシオ**が提唱されています。シャープ・レシオは追加的なリスク・テイクによってどれだけリスクプレミアムを改善できるのかを表す指標です。CAPMの第一命題によると、市場ポートフォリオはシャープ・レシオを最大化するという意味で最も効率的なポートフォリオであり、資本市場線の傾き $\frac{\mu_M - R_F}{\sigma_M}$ は市場ポートフォリオのシャープ・レシオと一致します。
$$
\text{Sharpe Ratio} = \frac{\mu_P-R_F}{\sigma_P}
$$
### CAPMの第二命題
第二命題は個々の資産のリスクとリターンのトレードオフを数式で表現したものです。
ある証券に投資するときのリスクと、その証券に投資するときの期待リターンとの関係を知ることができるようになります。
各投資家が証券 $i$ を追加的に保有する際、重要となるのは市場ポートフォリオとの相関です。分散が大きい資産であっても、市場ポートフォリオと負に相関していれば、その資産を追加的に保有することでポートフォリオ全体のリスクは低減されます。CAPMの第二命題は、この相関を以下の**マーケット・ベータ**として定量化します。
(※ $R_i$ は証券 $i$ のリターン、$R_M$ は市場ポートフォリオのリターン)
この $\beta_i$ は市場ポートフォリオのリスクを1としてベンチマーク化し、その証券のリスクがベンチマークの1を上回るか下回るかを測るものです。$\beta_i$ が大きいほど証券 $i$ は投資家にとってリスク(システマティック・リスク)が大きいことを意味します。CAPMの世界では、証券 $i$ のリスクはその証券のリターンの標準偏差ではなく、この $\beta_i$ によって測られます。
$$
\beta_i = \frac{\mathbb{Cov}[R_i, R_M]}{\mathbb{Var}[R_M]}
$$
金融市場全体が均衡しているには、リスクの高い証券はその分だけ期待リターンも高くなければなりません。
もし $\beta_i$ が低いにもかかわらず期待リターンが高い証券があるなら、投資家は市場ポートフォリオから離れてその証券をさらに買い増しするインセンティブを持ちます。
その結果、市場価格が上がり、期待リターンが下がるため、最終的に $\beta_i$ に応じた期待リターンが均衡で実現されます。
これまでは市場リスクプレミアムを $\mu_M - R_F$ と表記していましたが、以後ではより一般的な $\mathbb{E}[R_M] - R_F$ と表記します。
::: {.callout-important}
## CAPMの第二命題
各証券のリスクプレミアムは、その証券のマーケット・ベータに比例する。
この式は、証券 $i$ のリスクプレミアム $\mathbb{E}[R_i]-R_F$ を、$\beta_i$ と市場リスクプレミアム $\mathbb{E}[R_M]-R_F$ に分解している。
:::
$$
\begin{aligned}
\mathbb{E}[R_i]-R_F = \beta_i (\mathbb{E}[R_M] - R_F)\\
\text{ただし、 } \beta_i = \frac{\mathbb{Cov}[R_i,R_M]}{\mathbb{Var}[R_M]}
\end{aligned}
$$
通常、市場リスクプレミアムは正の値をとるので、CAPMの第二命題によると、個々の証券のリスクプレミアムは $\beta_i$ に関して線形に増加します。
$\beta_i$ はあくまで市場ポートフォリオとの相関でリスクを定量化しているのがポイントです。
いくら個々の証券の分散(リスク)が大きくても、それが市場ポートフォリオと相関しない固有リスクであれば、リスクプレミアムには反映されません。
期待値をとる前の $R_i$ を分解して確認します。
$$
R_i = R_F + \beta_i (R_M - R_F) + \varepsilon_i
$$
ここで $\varepsilon_i$ は期待値ゼロで $R_M$ と相関しない誤差項です。
$$
\mathbb{E}[\varepsilon_i] = 0, \qquad \mathbb{Cov}[\varepsilon_i, R_M] = 0
$$
分散を計算すると以下のようになります。
$$
\begin{aligned}
\mathbb{Var}[R_i] &= \mathbb{Var}[\beta_i R_M + \varepsilon_i]\\
& = \beta_i^2 \mathbb{Var}[R_M] + \mathbb{Var}[\varepsilon_i] + \underbrace{2\mathbb{Cov}[\beta_i R_M, \varepsilon_i]}_{\tiny =0}\\
& = \underbrace{\beta_i^2 \mathbb{Var}[R_M]}_{\tiny 市場ポートフォリオとの相関による寄与分} + \underbrace{\mathbb{Var}[\varepsilon_i]}_{\tiny 誤差項による寄与分}
\end{aligned}
$$
$R_i$ の分散は、市場ポートフォリオとの相関による寄与分(システマティック・リスク)と誤差項による寄与分(固有リスク)に分解できます。
誤差項の分散が大きければその分だけ $R_i$ の分散も大きくなりますが、証券 $i$ のリスクプレミアムは $\beta_i(\mathbb{E}[R_M]-R_F)$ のままで変化はありません。つまり、分散投資によって消去可能な固有リスクに対しては、市場は報酬(プレミアム)を与えないのです。
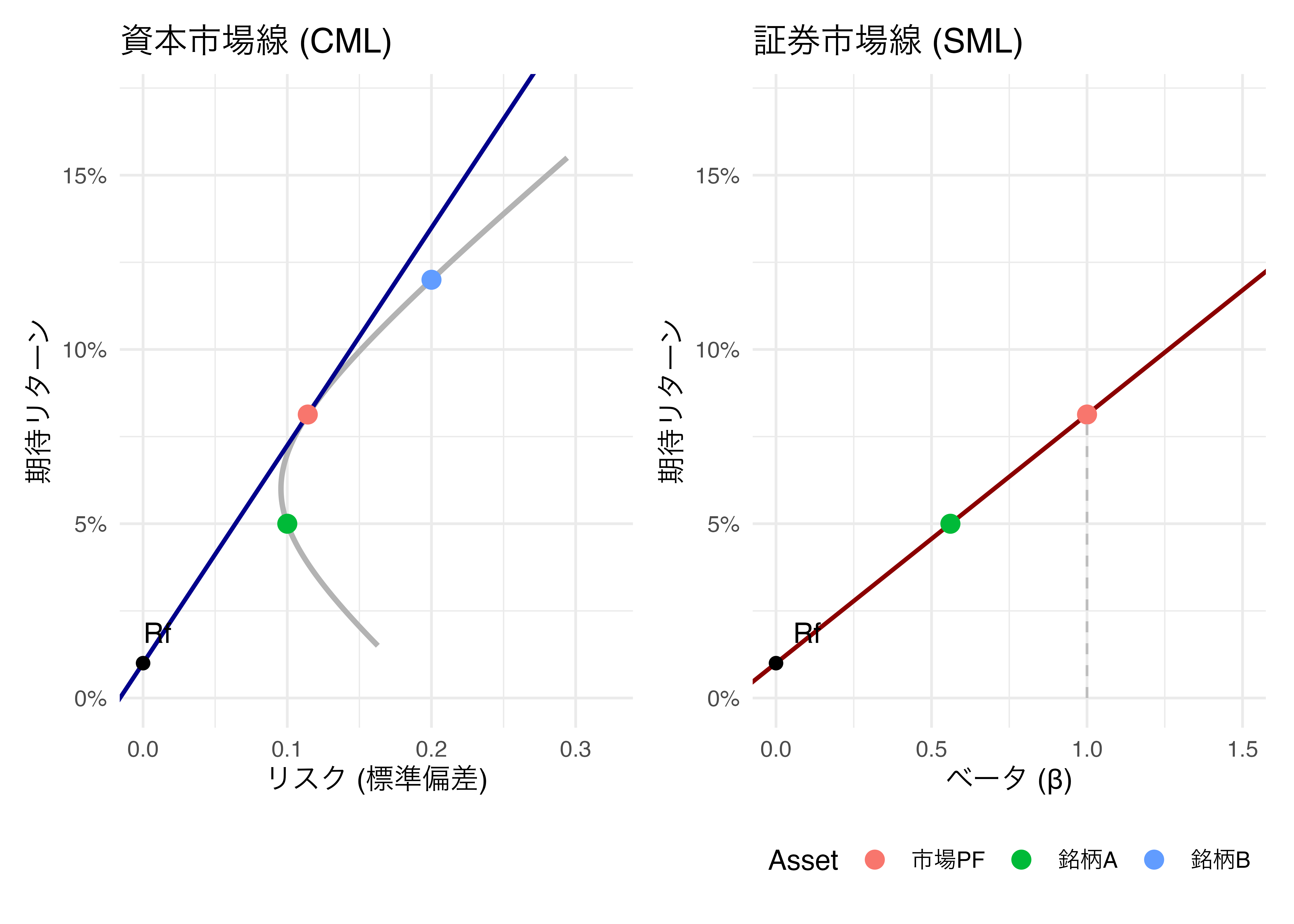
### 証券市場線
下左の図が示すように、安全資産と複数の危険資産が投資可能な場合、投資家の最適ポートフォリオは資本市場線上の1点(オレンジの点)となります。
一方、CAPMの第二命題が示唆するように、各証券のリスク(ベータ)とリターンとの関係は、右上がりの直線となります(図2.14 右図)。
縦軸に各証券の期待リターン、横軸に各証券のリスクを表すマーケット・ベータをとると、CAPMが完全に成立する世界では全ての資産が一直線上に並びます。この直線を**証券市場線** (Securities Market Line; SML) と呼びます。
定義通り $\beta$ を計算すると銘柄Aは約 $0.63$、銘柄Bは約 $1.33$ となります。
両者の期待リターンおよび $\beta$ を図示すると証券市場線に乗っており、この仮想的な市場ではCAPMが成立していることがわかります。
```{r securities_market_line, filename = "証券市場線のプロット"}
#| code-fold: true
# -------------------------------------------------------
# 1. パラメータ設定 (本文の記述と整合するように調整した数値)
# -------------------------------------------------------
# ※ ユーザーの手元に前の章のデータがある場合はそれを読み込んでください。
# ここでは本文中の「A:47%, B:53%」「Beta A:0.63, Beta B:1.33」
# と概ね一致するパラメータを設定します。
mu_A <- 0.05 # 銘柄Aの期待リターン
sig_A <- 0.10 # 銘柄Aの標準偏差
mu_B <- 0.12 # 銘柄Bの期待リターン
sig_B <- 0.20 # 銘柄Bの標準偏差
rho <- 0.2 # 相関係数
Rf <- 0.01 # 安全利子率
# 共分散
cov_AB <- rho * sig_A * sig_B
# -------------------------------------------------------
# 2. 接点ポートフォリオ(市場ポートフォリオ)の計算
# -------------------------------------------------------
# 過剰リターンベクトル
R_excess <- c(mu_A - Rf, mu_B - Rf)
# 分散共分散行列
Sigma <- matrix(c(sig_A^2, cov_AB, cov_AB, sig_B^2), nrow = 2)
# 接点ポートフォリオのウェイト計算 (解析解)
Sigma_inv <- solve(Sigma)
w_tangency_unscaled <- Sigma_inv %*% R_excess
w_M <- w_tangency_unscaled / sum(w_tangency_unscaled) # ウェイトの和を1にする
# 市場ポートフォリオの期待リターンとリスク
mu_M <- as.numeric(t(w_M) %*% c(mu_A, mu_B))
sig_M <- as.numeric(sqrt(t(w_M) %*% Sigma %*% w_M))
# Betaの計算: Cov(Ri, RM) / Var(RM)
# Cov(Ra, Rm) = w_A*Var(A) + w_B*Cov(A,B)
cov_AM <- w_M[1] * sig_A^2 + w_M[2] * cov_AB
cov_BM <- w_M[1] * cov_AB + w_M[2] * sig_B^2
beta_A <- cov_AM / sig_M^2
beta_B <- cov_BM / sig_M^2
# データフレーム化 (プロット用)
assets <- tibble(
Asset = c("銘柄A", "銘柄B", "市場PF"),
Mu = c(mu_A, mu_B, mu_M),
Sigma = c(sig_A, sig_B, sig_M),
Beta = c(beta_A, beta_B, 1) # 市場PFのベータは定義上1
)
# -------------------------------------------------------
# 3. 効率的フロンティアのデータ生成 (左図用)
# -------------------------------------------------------
w_seq <- seq(-0.5, 1.5, length.out = 300)
frontier_data <- tibble(
w_A = w_seq,
w_B = 1 - w_seq
) %>%
mutate(
Mu = w_A * mu_A + w_B * mu_B,
Sigma = sqrt(w_A^2 * sig_A^2 + w_B^2 * sig_B^2 + 2 * w_A * w_B * cov_AB)
)
# -------------------------------------------------------
# 4. 作図 (ggplot2)
# -------------------------------------------------------
# --- 左図: 資本市場線 (CML) ---
p_cml <- ggplot() +
# 効率的フロンティア(双曲線)
geom_path(data = frontier_data, aes(x = Sigma, y = Mu),
color = "gray70", size = 1) +
# 資本市場線 (CML): 切片Rf, 接点を通る直線
geom_abline(intercept = Rf, slope = (mu_M - Rf) / sig_M,
color = "darkblue", linetype = "solid", size = 0.8) +
# 各資産のポイント
geom_point(data = assets, aes(x = Sigma, y = Mu, color = Asset), size = 3) +
# Rfの点
geom_point(aes(x = 0, y = Rf), color = "black", size = 2) +
annotate("text", x = 0.01, y = Rf, label = "Rf", vjust = -1) +
# ラベル類
labs(title = "資本市場線 (CML)",
x = "リスク (標準偏差)", y = "期待リターン") +
theme_minimal() +
scale_x_continuous(limits = c(0, max(frontier_data$Sigma)*1.1)) +
scale_y_continuous(limits = c(0, max(frontier_data$Mu)*1.1), labels = scales::percent) +
theme(legend.position = "none") # 凡例は右図と共通または省略
# --- 右図: 証券市場線 (SML) ---
p_sml <- ggplot() +
# 証券市場線 (SML): 切片Rf, 傾き(Rm-Rf)
geom_abline(intercept = Rf, slope = (mu_M - Rf),
color = "darkred", linetype = "solid", size = 0.8) +
# 各資産のポイント
geom_point(data = assets, aes(x = Beta, y = Mu, color = Asset), size = 3) +
# 補助線 (市場PFのベータ=1を示す線)
geom_segment(aes(x = 1, xend = 1, y = 0, yend = mu_M),
linetype = "dashed", color = "gray") +
# Rfの点
geom_point(aes(x = 0, y = Rf), color = "black", size = 2) +
annotate("text", x = 0.1, y = Rf, label = "Rf", vjust = -1) +
# ラベル類
labs(title = "証券市場線 (SML)",
x = "ベータ (β)", y = "期待リターン") +
theme_minimal() +
scale_x_continuous(limits = c(0, 1.5)) +
scale_y_continuous(limits = c(0, max(frontier_data$Mu)*1.1), labels = scales::percent) +
theme(legend.position = "bottom")
# --- 図の結合 ---
p_combined <- p_cml + p_sml
p_combined
```
## N資産が投資可能な場合への拡張
ここまではリスク資産が銘柄AとBの二つしかない場合を分析してきましたが,平均分散アプローチやCAPMは危険資産の数が任意の$N$個であっても成立します。