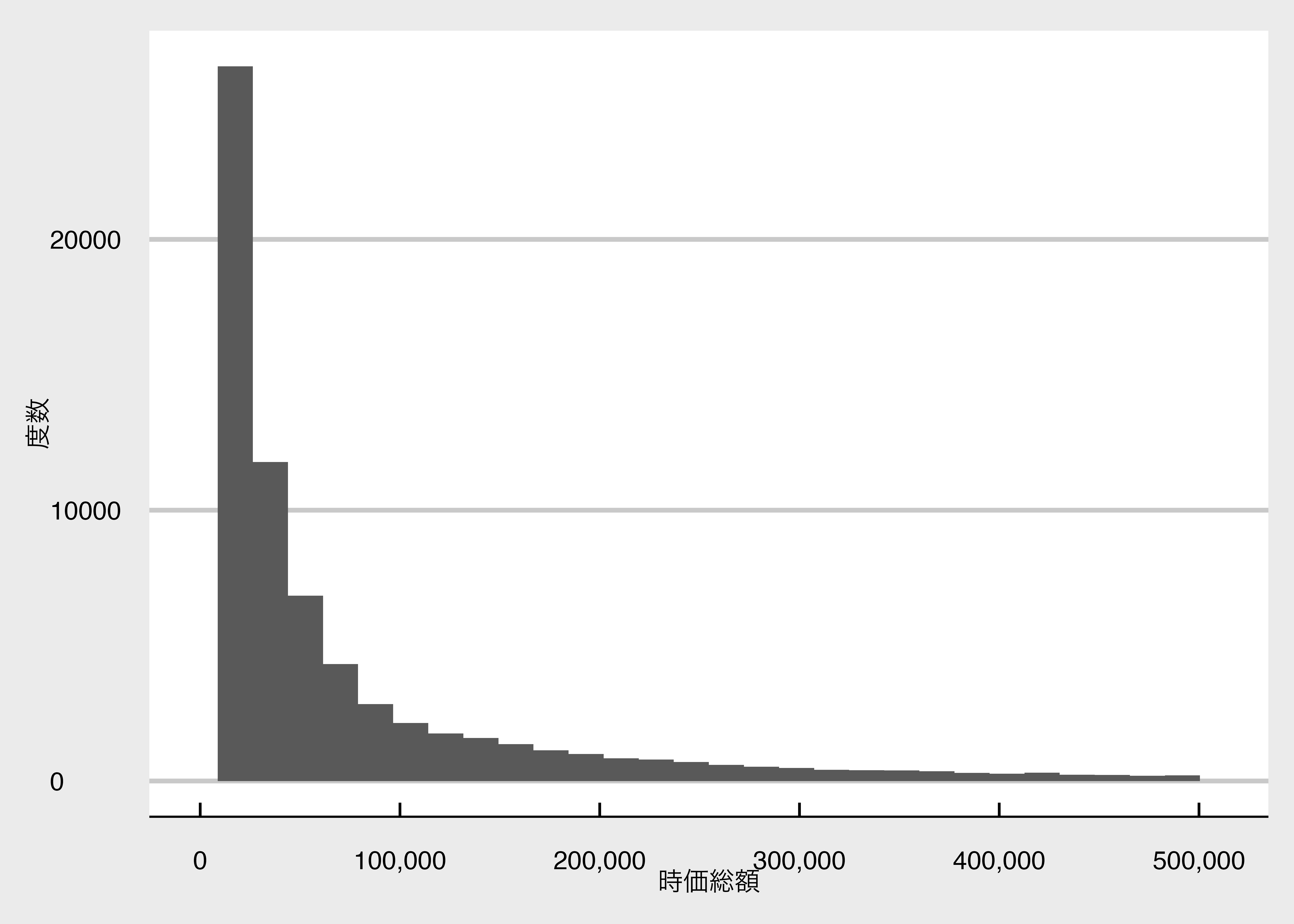
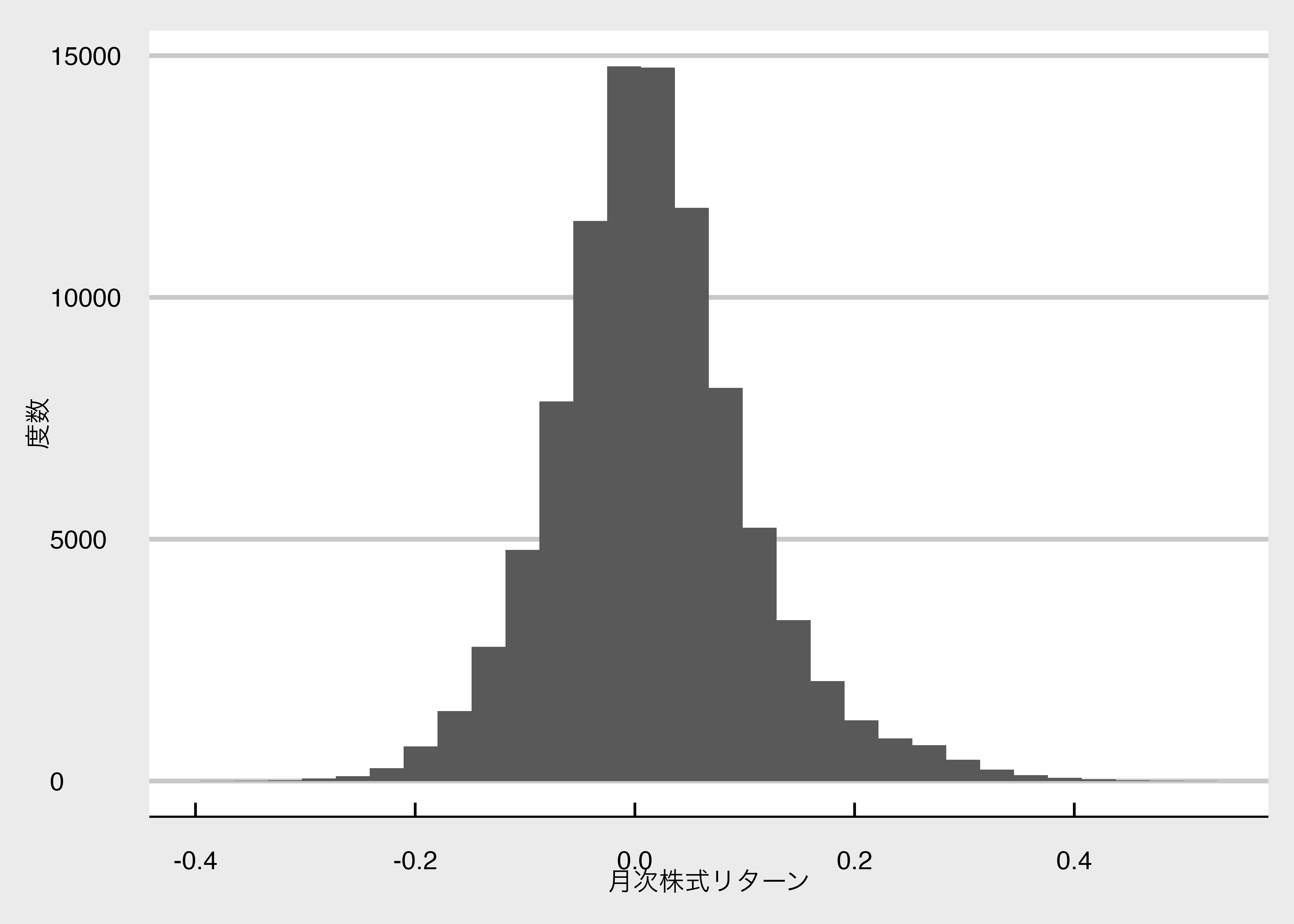
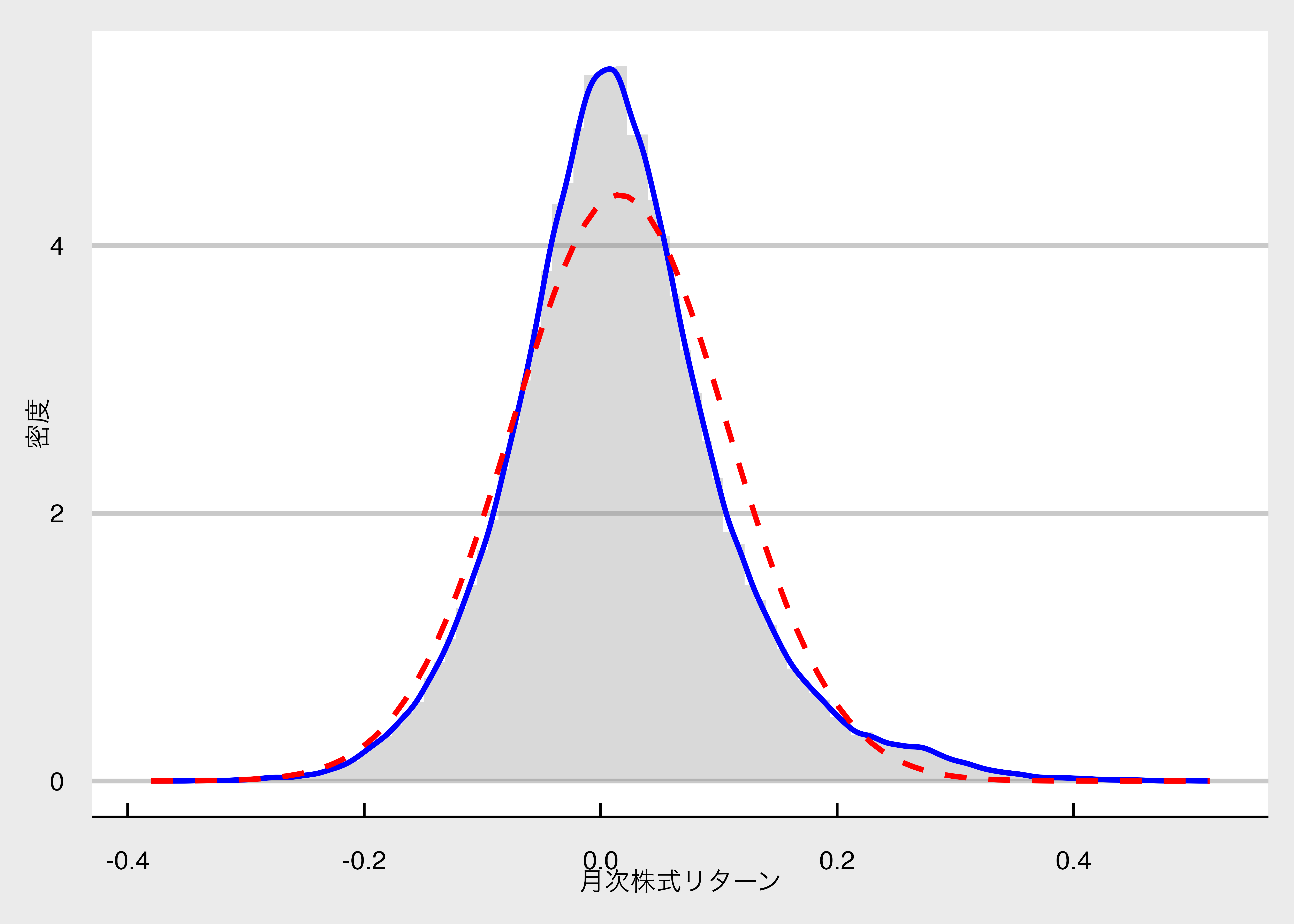
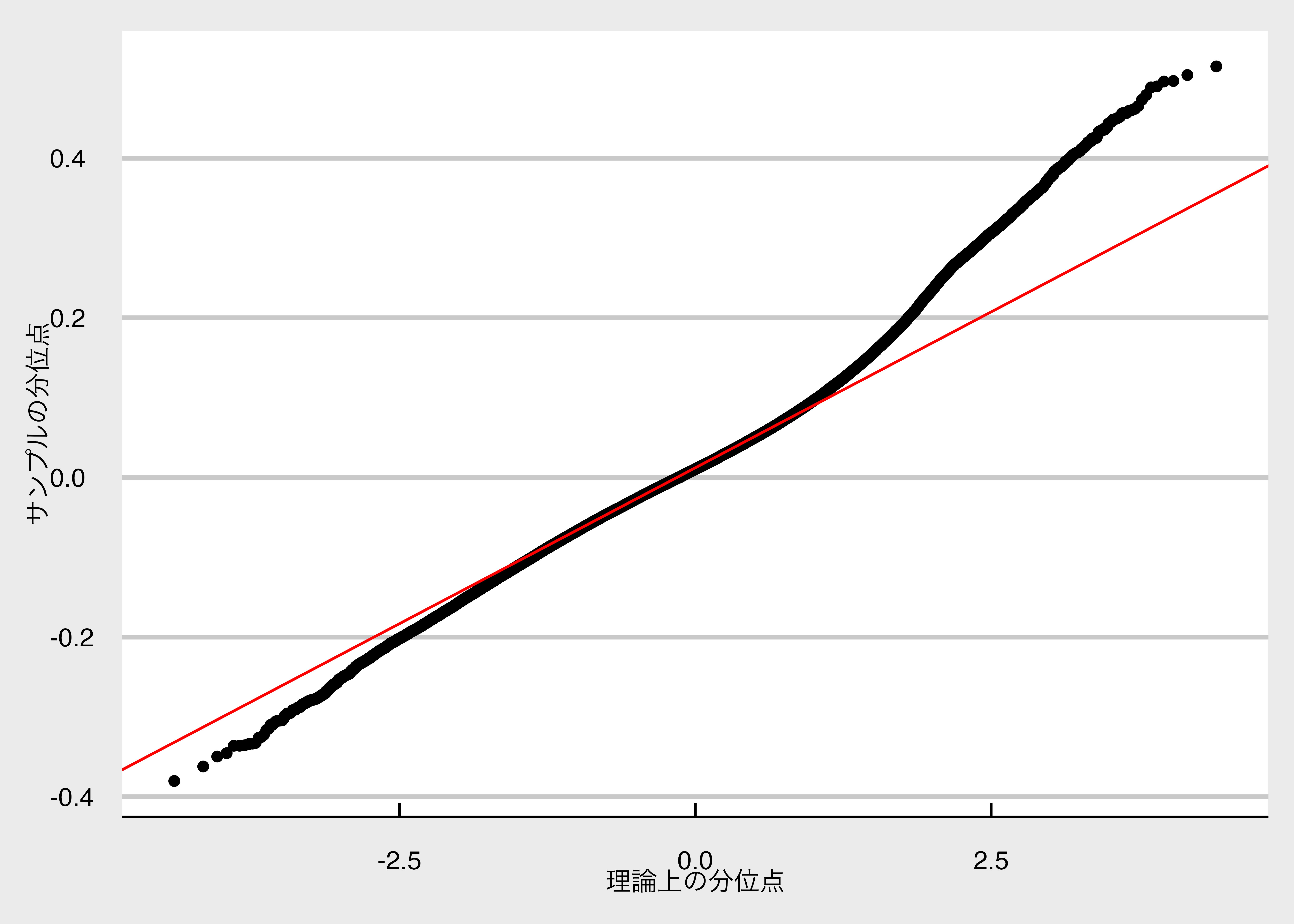
Rows: 95,040
Columns: 9
$ year <dbl> 2015, 2015, 2015, 2015, 2015, 2015, 2015, 2015, 2015, 2015…
$ month <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 1, 2, 3, 4, 5, 6, 7…
$ month_ID <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,…
$ firm_ID <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ stock_price <dbl> 954, 960, 1113, 1081, 1317, 1366, 1353, 1209, 1291, 1407, …
$ DPS <dbl> 0, 0, 0, 0, 0, 29, 0, 0, 0, 0, 0, 29, 0, 0, 0, 0, 0, 40, 0…
$ n_shares <dbl> 2422000, 2422000, 2422000, 2422000, 2422000, 2422000, 2422…
$ adj_coef <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ R_F <dbl> 6.506826e-04, 5.834099e-04, 6.114423e-04, 6.848180e-04, 7.…