## R言語入門
```{r setup, filename = "いろいろな設定"}
#| code-fold: true
pacman::p_load(
tidyverse, # 便利なパッケージ群
ggthemes, # ggplot2のテーマ集
microbenchmark, # ベンチマーク測定
Rcpp # RとC++の連携
)
mystyle <- list(
theme_economist_white(
# gray_bg = FALSE,
base_family = "HiraKakuProN-W3"
),
scale_colour_economist(),
theme(
text = element_text(size = 12), # フォントファミリーは上で指定済みなので省略可
axis.title = element_text(size = 12)
)
)
knitr::opts_chunk$set(
class.source = "numberLines lineAnchors"
# class.output = "numberLines lineAnchors chunkout"
)
```
プログラミング言語にはいろんな種類があるけれど、今回学習する**R言語**は、インタプリタ型とよばれるもので、コンパイルという作業の必要が無く、書いたらすぐ実行できる仕様となっています。たとえば、教科書にあるように
```{r}
100 / (1 + 0.1)
```
を実行すれば、結果がすぐ表示されます。 RstudioとかVisual Studio CodeとかAntigravityを使って、上のようなRソースコードを一気に書いてまとめて実行するための**スクリプト・ファイル**を作成します。
ソースコードを書くにあたり注意する点が4つあります。
1. **大文字と小文字は区別される**ので、`x`と`X`は別の変数として扱われます。
2. **半角スペース**は、**区切り文字**として扱われるので、`x <- 100`と`x<-100`は同じ意味になります。
3. **改行**も、**区切り文字**として扱われます。長いソースコードは改行して読みやすくしましょう。
4. **コメント**は、`#`から行末までの文字列がコメントとして扱われ、実行されません。プログラムの内容を説明するためにたくさん書いて残しておきましょう。
## Rの基本的な機能
### スカラー変数の定義
この学習を通じて**変数**(variable)とは、**数値や文字といったデータを格納するための箱**を表し、中に何が入っているのかにより、スカラー変数、ベクトル、行列、データフレームなどに分類されます。まずは、スカラー変数の定義を学びます。
スカラー(scalar)とは、大きさだけで決まる量のことで、つまり、**1つの数値**を指します。 R言語ではスカラー変数を定義するには、`<-`を使います。たとえば、`x <- 100`と書けば、xというスカラー変数に100という数値を格納できます。このとき、`<-`は代入演算子と呼ばれ、右辺の値を左辺の変数に代入するという意味です。また、`x`という変数を**左辺値**(left-hand side)、`100`という数値を**右辺値**(right-hand side)と呼びます。
```{r}
x <- 100 # 代入演算子<- の前後に半角スペースを入れるのがお作法
```
この中身を表示されるには、`print()`関数を使います。
```{r}
print(x) # xの中身を表示
```
あるいは
```{r}
x
```
でも表示されます。
<aside>Rでは`#`の後ろの文章はコメントとして扱われ、実行されません。コメントはプログラムの内容を説明するためにたくさん書いて残しておきましょう。</aside>
### ベクトル変数の定義
**ベクトル**(vector)とは、大きさと向きで決まる量のことで、つまり、**複数の数値**を指します。R言語ではベクトル変数を定義するには、`c()`を使います。たとえば、`x <- c(1, 2, 3)`と書けば、xというベクトル変数に1, 2, 3という数値を格納できます。このとき、`c()`はベクトルを作る関数と呼ばれ、`1, 2, 3`という数値を引数として与えています。
```{r}
x <- c(1, 5, 9) # xに1と5と9を要素とするベクトルを代入
print(x)
```
等差数列を作る関数に`seq()`関数があります。`seq()`は3つの引数をとり、
- `from` : 始点
- `to` : 終点
- `by` : 差分
を指定します。たとえば、2000年から2020年を表す年度の変数を`year`として定義するには、
```{r}
year <- seq(from = 2000, to = 2020, by = 1)
print(year)
```
と書けば、2000から2020までの公差1の等差数列を作ります。 `seq()`変数の引数には、`from`と`to`と`by`の3つの引数を指定することができますが、`from`と`to`のみを指定することもできます。このとき、`by`の値は1となります。次のように書いても、上と同じ結果を得ることができます。
```{r}
seq(2000,2020)
```
ベクトルの要素数を知るには、`length()`関数を使います。
```{r}
length(year) # yearの要素数を表示
```
ベクトル変数`year`の中には21個の要素があることがわかります。
#### ベクトルの要素の取り出し
複数の要素をもつベクトルから、一部の要素を取り出すには、`[]`を使います。たとえば、`x`の2番目の要素を取り出すには、`x[2]`と書きます。このとき、`[]`は添字演算子と呼ばれ、`2`という添字を引数として与えています。添字は1から始まります。
上の`year`から2000を取り出すには、`year[1]`、2020を取り出すには`year[20]`と書きます。 次のような書き方で、好きな要素を指定して取り出すことができます。
```{r}
year[1] # 1番目のデータを取り出す
year[20] # 20番目のデータを取り出す
year[2:5] # 2番目から5番目のデータを取り出す
year[c(5,10)] # 1番目と20番目のデータを取り出す
year[6:length(year)] # 6番目から最後のデータを取り出す
```
#### 現在価値の計算
今の時点を$t=0$として、$T$年後に確実に得られるキャッシュ・フロー$CF_T$の現在価値$PV_0$は、
$$
PV_0 = \frac{CF_T}{(1+r)^T}
$$
と書けます。たとえば1年後に確実に受け取れる100万円の現在価値$PV_0$を計算してみます。
いま、無リスク利子率$r$は10%とします。
```{r}
100 / (1 + 0.1)^1
```
次に、この無リスク利子率$r$が変化した場合の現在価値の計算を考えます。まず、無リスク利子率のベクトルを定義します。
```{r}
# 下の2つは同じ結果
R <- seq(from = 0.1, to = 0.2, by = 0.01) # 省略せずに書いた場合
R <- seq(0.1, 0.2, 0.01) # 略した場合
```
次に、無リスク利子率が変化した場合の現在価値を計算します。
```{r}
PV <- 100 / (1 + R)^1
print(PV)
```
無リスク利子率が0.1から0.2まで0.01ずつ変化した場合の現在価値が計算されました。この結果をグラフにしてみます。
### 基本パッケージ`plot`による作図
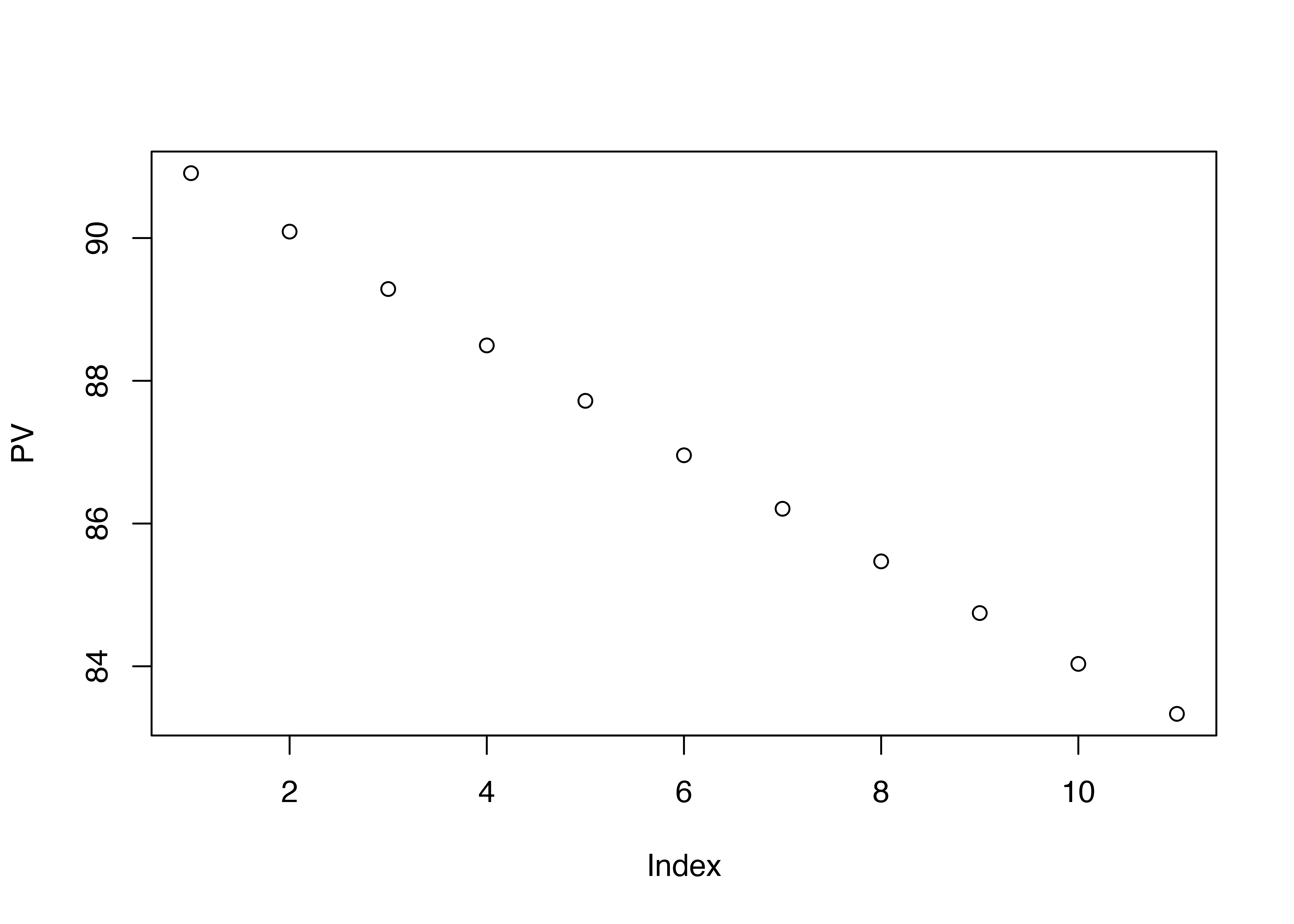
とりあえずサクッと作図してデータをチェックしたいとき、もとからR言語に組み込まれている基本関数`plot()`が便利です。先ほど作成したベクトル変数`PV`をグラフにしてみます。
```{r}
plot(PV)
```
いま、`PV`は11個の要素をもつベクトル変数なので、データを左から順番に並べた散布図(scatter diagram)が作成されています。これだと何のグラフか分かりづらいので、いろいろとオプションを指定してみます。
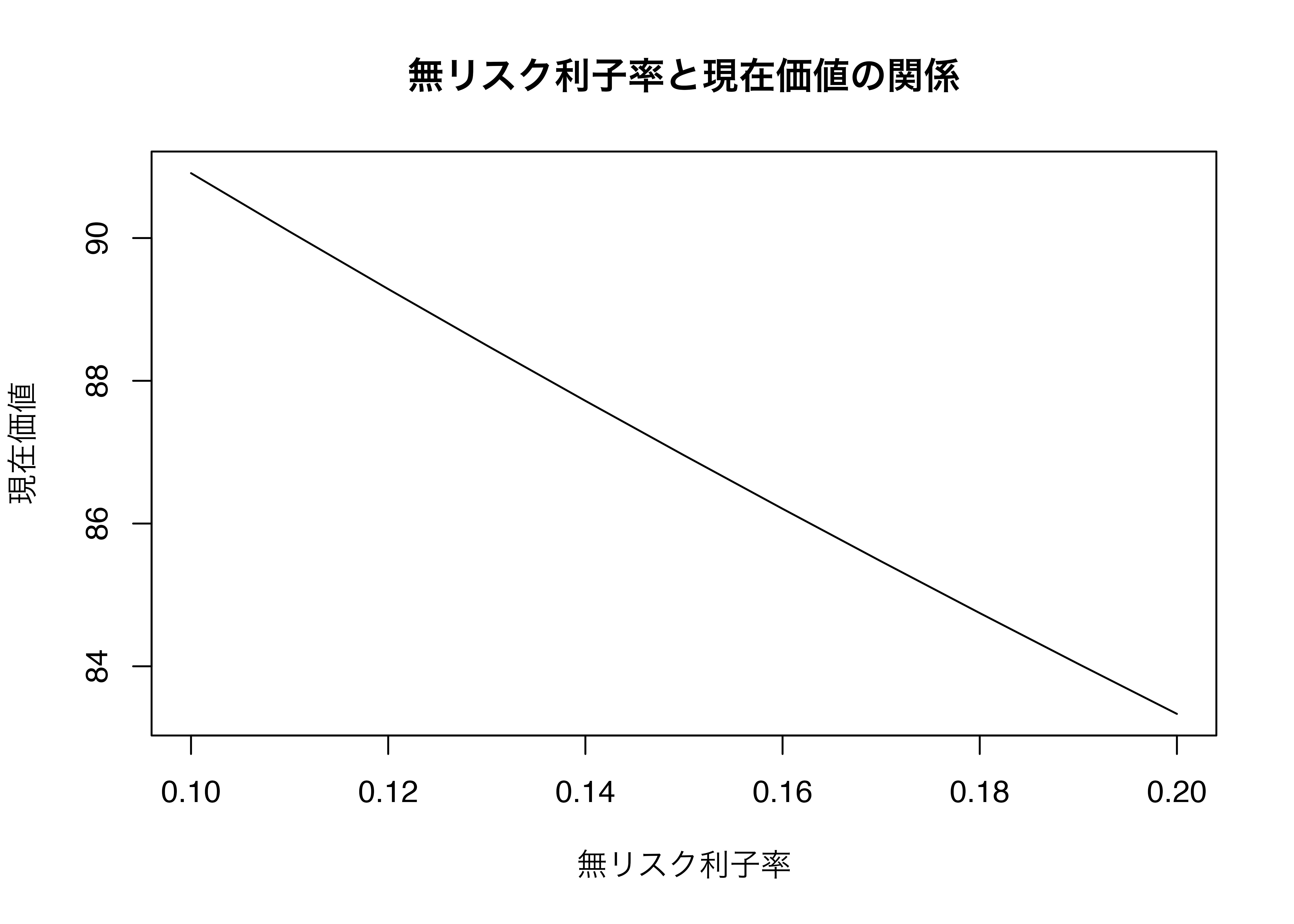
```{r}
plot(
x = R, # x軸のデータ
y = PV, # y軸のデータ
xlab = "無リスク利子率",
ylab = "現在価値",
main = "無リスク利子率と現在価値の関係",
type = "l" # 線グラフ
)
```
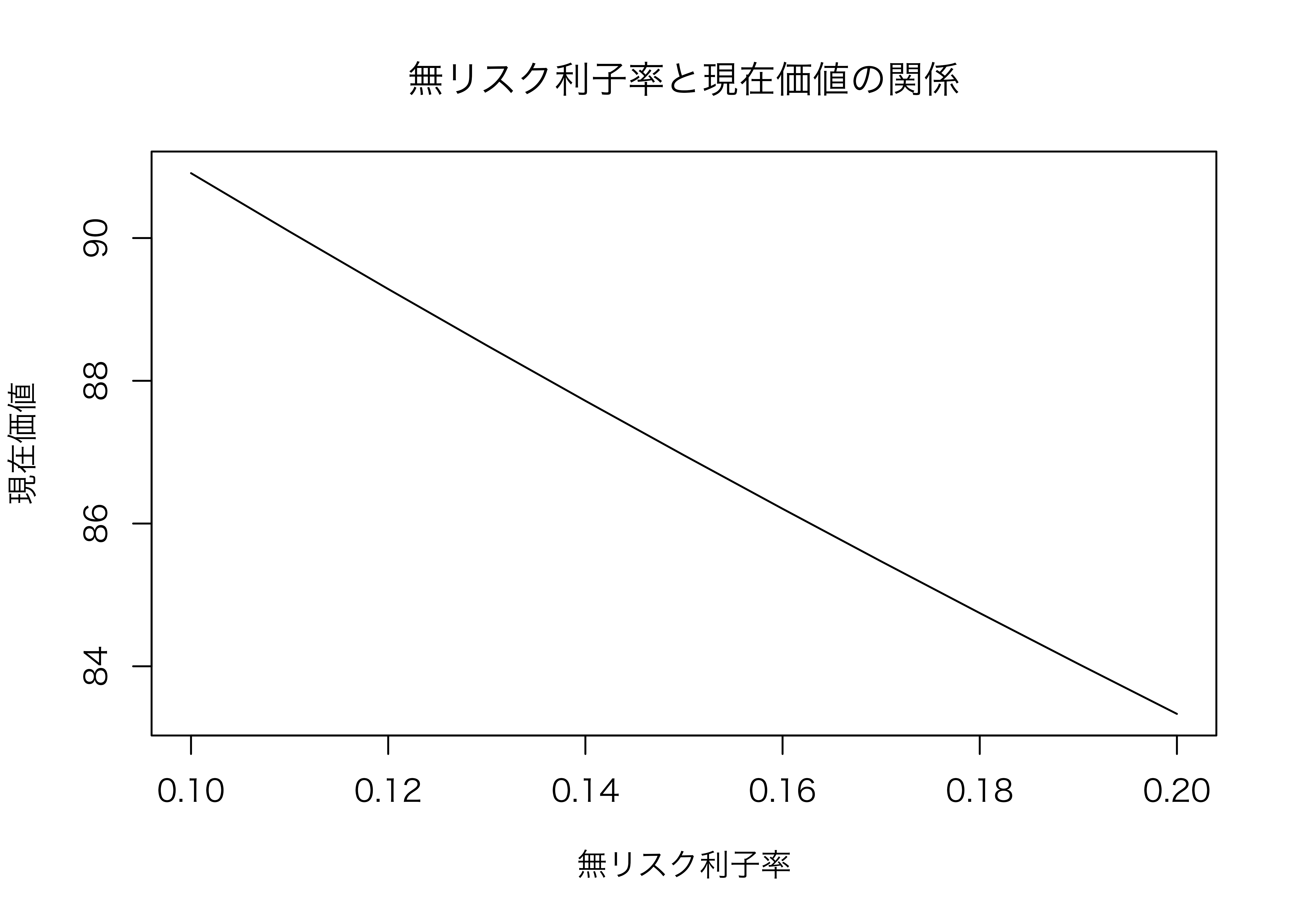
Macだと文字化けしてしまいました。そこで文字コードを指定します。Windowsだとこの作業は不要です。
```{r}
par(family = "HiraKakuProN-W3") # Macの場合のみ
plot(
x = R, # x軸のデータ
y = PV, # y軸のデータ
xlab = "無リスク利子率", # x軸のラベル
ylab = "現在価値", # y軸のラベル
main = "無リスク利子率と現在価値の関係", # グラフのタイトル
type = "l" # 折れ線グラフ
)
```
## `for`文の使い方
プログラミングの基本要素である
- 繰り返し
- 分岐
- 関数
の最初の要素である「繰り返し」を行うための文法が`for`文です。`for`文は、ある処理を繰り返し行うための文法です。たとえば、1から10までの整数を順番に表示するには、次のように書きます。
```{r}
for (i in 1:10) { # iは1から10まで
print(i) # iを表示
}
```
この文の構造は、基本的には
```{r eval=FALSE}
for (好きな変数 in 繰り返す範囲) {
繰り返したい処理
}
```
となっています。
たとえば、教科書のように、
- 初期投資100万円
- 1年後に50万円のキャッシュ・フロー
- 2年後に50万円のキャッシュ・フロー
- 3年後に50万円のキャッシュ・フロー
という投資プロジェクトの現在価値を計算する場合、愚直に書くと次のようになります。
```{r}
NPV1 <- -100 +
50 / (1 + 0.1)^1 +
50 / (1 + 0.1)^2 +
50 / (1 + 0.1)^3
print(NPV1)
```
この上のコードの2行目から4行目はほぼ同じ内容なので、数字が変化しているところに注目し、`for`文を使って書き換えてみます。ここでは`^1`のところが1ずつ大きくなってます。この部分を`i`という変数に置き換えてみます。 ついでに、後で変化させることがあるかもしれない部分をすべて変数として定義しておきます。
```{r}
R <- 0.1 # 無リスク利子率
NPV <- -100 # 初期投資
CF <- 50 # キャッシュ・フロー
for (i in 1:3) { # iは1から3まで
NPV <- NPV + CF / (1 + R)^i # 現在価値の計算
}
print(NPV)
```
愚直に計算した場合の同じ結果となりました。 これを10年間の現在価値を計算する場合だとすると、
```{r}
R <- 0.1 # 無リスク利子率
NPV <- -100 # 初期投資
NPV1 <- NPV +
50 / (1 + R)^1 +
50 / (1 + R)^2 +
50 / (1 + R)^3 +
50 / (1 + R)^4 +
50 / (1 + R)^5 +
50 / (1 + R)^6 +
50 / (1 + R)^7 +
50 / (1 + R)^8 +
50 / (1 + R)^9 +
50 / (1 + R)^10
print(NPV1)
```
と面倒くさいことこの上ないですが、`for`文を使えば、
```{r}
R <- 0.1 # 無リスク利子率
NPV <- -100 # 初期投資
for (i in 1:10) { # iは1から10まで
NPV <- NPV + 50 / (1 + R)^i
}
print(NPV)
```
と短く書くことができます。
使いこなせるように練習しておきましょう。
次のように、`print()`関数の位置を変えた場合、どうなるか考えてみてください。
```{r}
R <- 0.1 # 無リスク利子率
NPV <- -100 # 初期投資
for (i in 1:3) { # iは1から10まで
print(NPV)
NPV <- NPV + 50 / (1 + R)^i
}
print(NPV)
```
この場合、最初にNPVの中を表示し、次に1期目の現在価値を計算し、またその結果を表示し、2期目の現在価値を計算し・・・という順番で繰り返しが行われるので、計算の途中経過が表示されることになります。
### `if`文
次に、プログラミングの基本要素である
- 繰り返し
- **分岐**
- 関数
のうち分岐を行うための文法が`if`文です。`if`文は、ある条件を満たす場合にのみ処理を行うための文法です。たとえば、ある変数`x`が0より大きい場合にのみ、その変数を表示するには、次のように書きます。
```{r}
x <- -1
if (x > 0) { # xが0より大きい場合
print(x) # xを表示
}
```
この文の構造は、基本的には
```{r eval=FALSE}
if (条件) {
条件を満たす場合に実行する処理
}
```
のようになっています。 この`if`文を使って、NPVが0より大きい場合にのみ、「プロジェクトを実行!」と表示されるようにしてみます。
```{r}
R <- 0.1 # 無リスク利子率
NPV <- -100 # 初期投資
for (i in 1:10) { # iは1から10まで
NPV <- NPV + 50 / (1 + R)^i
}
if (NPV > 0) { # NPVが0より大きい場合
print("プロジェクトを実行!") # 文字列を表示
}
```
ここではNPVの値が`207.2284`となりプラスになっているので、「プロジェクトを実行!」と表示されます。
## NPVと割引率の関係の可視化
無リスク利子率が0.1から0.2まで0.01ずつ変化した場合の現在価値NPVの値を計算してみます。
```{r}
R <- seq(0.1, 0.2, 0.01) # 無リスク利子率
N <- length(R) # 無リスク利子率の要素数 11個
NPV <- rep(NA, N) # ベクトル変数にN個のNAを代入
for (i in 1:N) { # iは1からNまで
NPV[i] <- -100 # 初期投資
for (j in 1:3) { # jは1から3まで
NPV[i] <- NPV[i] + 50 / (1 + R[i])^j # 現在価値
}
}
print(NPV) # 11個の現在価値を表示
```
少し複雑な構造しているので、順番に説明します。
- 1行目は、無リスク利子率のベクトル変数`R`を定義しています。ここでは、0.1から0.2まで0.01刻みのデータを作成しています。
- 2行目は、ベクトル変数`R`の要素数を`N`として定義しています。ここでは、`N`は11となります。
- 3行目は、ベクトル変数`NPV`に`N`個の`NA`を代入しています。`NA`はNot Availableの略で、欠損値を表します。`NA`を代入することで、空っぽの箱が11個入ったベクトル変数`NPV`を用意します。
- 4行目から9行目は、`for`文を使って、`NPV`の中身を計算しています。 `for`が2回出てきているので、二重に繰り返しの処理を行っています。これを**ネスト**と呼びます。 1つのめ`for`は`i`が1からN(ここでは11)まで変化し、2つめの`for`は`j`が1から3まで変化します。1つめの`for`文のiが1のとき、次の`for`文の`j`が1から3までの処理を繰り返し、次に1つめの`for`文の`i`が2のとき、次の`for`文の`j`が1から3までの処理を繰り返し・・・という順番で処理が行われます。
- 10行目は、`NPV`の中身を表示しています。
<aside>TABキーを使って、インデントを行い、ソースコードのまとまりをわかりやすくしています。インデントは、プログラムの構造をわかりやすくするために行います。インデントを行うときは、半角スペース2つか4つを使います。どちらを使っても構いませんが、どちらかに統一することが大切です。</aside>
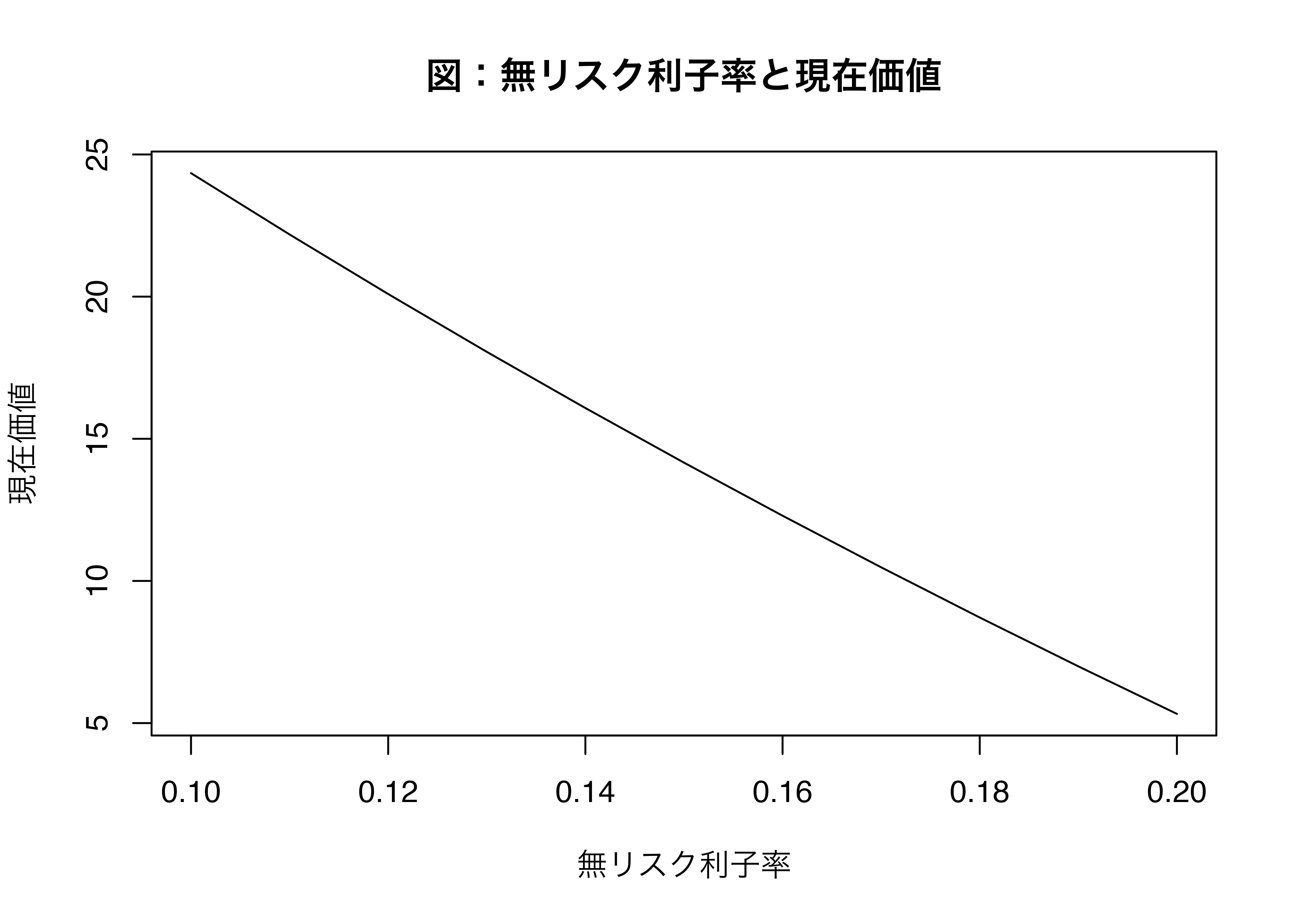
この結果をグラフにしてみます。
```{r}
plot(
x = R, # x軸のデータ
y = NPV, # y軸のデータ
xlab = "無リスク利子率", # x軸のラベル
ylab = "現在価値", # y軸のラベル
main = "図:無リスク利子率と現在価値", # グラフのタイトル
type = "l" # 線グラフ
)
```
#### ベクトル化
上のコードは、`for`文を使って、`NPV`の中身を計算しています。しかし、R言語では、`for`文を使わずに、ベクトルを使って、同じことを行うことができます。このように、`for`文を使わずに、ベクトルを使って処理を行うことを**ベクトル化**と呼びます。ベクトル化を行うと、処理が高速化されることがあります。
```{r}
R <- 0.1 # 無リスク利子率 10%
CF <- c(-100, 50, 50, 50) # キャッシュ・フローのベクトル
year <- 0:3 # 年度のベクトル
PV_CF <- CF / (1 + R)^year # 各期の現在価値を計算
NPV <- sum(PV_CF) # 現在価値の合計
print(NPV)
```
## 独自関数の定義の仕方
プログラミングの基本要素である
- 繰り返し
- 分岐
- **関数**
の作り方について説明します。 Rでは自分で関数を定義することができます。関数を定義することで、同じ処理を何度も書く必要がなくなり、プログラムの見通しがよくなります。 例えば、足し算をする関数`my_add()`を定義してみます。
```{r}
my_add <- function(x, y){
x + y
}
```
この関数の構造は、
```{r eval=FALSE}
好きな関数名 <- function(引数1, 引数2){
処理内容
}
```
となっています。つまり、この独自関数`my_add()`は、`x`と`y`という2つの引数(ひきすう)を足し合わせる関数です。数学的に書くなら、
$$
f(x, y) = x + y
$$
となります。これは$f$という関数は2つの引数を足す関数であるという意味になっています。 作成した独自関数`my_add()`を使ってみます。
```{r}
my_add(1, 2)
```
3が出力されました。
このように、独自関数を作成する場合には、
1. どのような引数を与えるのか?
2. それに対してどのような処理を行うのか?
3. 最終的にどの値を返す(出力させる)のか?
を考えておく必要があります。
では今までの流れで、現在価値を計算する関数を作成してみます。変化させたい値は、キャッシュフロー`CF`と無リスク利子率`R`なので、その2つを引数とする独自関数を作成します。 少し注意する必要がある点として、以下の計算例では`CF`の1番目の要素は初期投資額となることに注意しましょう。
```{r}
calc_PV <- function(CF, R) {
PV <- CF[1] # 初期投資額なのでマイナスの値
for (i in 2:length(CF)) { # iは2からCFの要素数まで
PV <- PV + CF[i] / (1 + R)^(i - 1) # 現在価値
}
return(PV) # 現在価値を返す
}
```
この関数`calc_PV()`を使って、現在価値を計算してみます。
```{r}
calc_PV(c(-100, 50, 50, 50), 0.1)
```
ちゃんと計算されました。この関数を使って、無リスク利子率が0.1から0.2まで0.01ずつ変化した場合の現在価値を計算してみます。
```{r}
CF <- c(-100, 50, 50, 50) # キャッシュ・フローのベクトル
R <- seq(0.1, 0.2, 0.01) # 無リスク利子率のベクトル
calc_PV(CF,R)
```
計算されました。 関数の引数にデフォルトで値を設定することで、入力を楽にすることができます。例えば、無リスク利子率のデフォルト値を0.1に設定してみます。
```{r}
calc_PV <- function(CF, R = 0.1) {
PV <- CF[1] # 初期投資額なのでマイナスの値
for (i in 2:length(CF)) { # iは2からCFの要素数まで
PV <- PV + CF[i] / (1 + R)^(i - 1) # 現在価値
}
return(PV) # 現在価値を返す
}
```
すると、無リスク利子率を指定しなくても、デフォルト値が使われるようになります。
```{r}
CF <- c(-100, 50, 50, 50) # キャッシュ・フローのベクトル
calc_PV(CF)
```
ただ計算を間違えるもとにもなるので、なるべく省略せずに、しっかり書くことが大事です。
#### もっと凝った独自関数
繰り返し、分岐、関数というプログラミングの基本要素を勉強したので、もう少し複雑なプログラムを作成してみます。
まずは、引数に正の数字以外のもの、あるいは文字列を入力した場合にエラーを表示する関数を作成します。
```{r}
calc_PV_new <- function(CF, R) {
if (R <= 0) {
stop("無リスク利子率は正の値を入力してください。") # エラー処理
}
if ( !is.numeric(CF) ) {
stop("キャッシュ・フローは数値を入力してください。")
}
if ( !is.numeric(R) ) {
stop("無リスク利子率は数値を入力してください。")
}
PV <- CF[1]
for (i in 2:length(CF)) {
PV <- PV + CF[i] / (1 + R)^(i - 1)
}
return(PV)
}
```
できました。ついでに、NPVの計算結果とともに、NPVが0より大きい場合にのみ、「プロジェクトを実行!」と表示する機能も実装してみます。
```{r}
calc_PV_new <- function(CF, R = 0.1) {
if (R <= 0) {
stop("無リスク利子率は正の値を入力してください。") # エラー処理
}
if ( !is.numeric(CF) ) {
stop("キャッシュ・フローは数値を入力してください。")
}
if ( !is.numeric(R) ) {
stop("無リスク利子率は数値を入力してください。")
}
PV <- CF[1]
for (i in 2:length(CF)) {
PV <- PV + CF[i] / (1 + R)^(i - 1)
}
if (PV >= 0) { # NPVが0より大きい場合
paste0("NPVが", round(PV, digits = 2), "なので、プロジェクトを実行!") # 文字列を表示
} else {
paste0("NPVが", round(PV, digits = 2), "なのでプロジェクト中止!") # 文字列を表示
}
}
```
いろいろ駆使してより短く簡単に書くなら、
```{r}
calc_PV <- function(CF, R = 0.1) {
if (!is.numeric(CF) || !is.numeric(R) || R <= 0) {
stop("キャッシュ・フローと無リスク利子率は数値を入力し、無リスク利子率は正の値を入力してください。")
}
PV <- sum(sapply(1:length(CF), function(i) CF[i] / (1 + R)^(i - 1)))
if (PV >= 0) {
paste0("NPVが", round(PV, digits = 2), "なので、プロジェクトを実行!")
} else {
paste0("NPVが", round(PV, digits = 2), "なのでプロジェクト中止!")
}
}
```
```{r}
CF <- c(-100, 50, 50, 50)
calc_PV(CF)
```
うまくいきました。 ちょっとキャッシュフローのベクトルを変化させて、初期投資を-200にすると、
```{r}
CF <- c(-200, 50, 50, 50)
calc_PV(CF)
```
ちゃんと中止のメッセージが出ました。
このように、分岐、繰り返し、関数を駆使して、様々なプログラムを作成することができます。プログラミングの基本要素を使いこなせるように、練習を重ねてください。まずは教科書に書いてあるソースコードを自分のPC上で実行してみてください。その際は、コピペせずに自分で入力するようにしてください。
#### 付録:ベクトル化で早くなるのか?
どれほど高速化されるのかを確認するため、100万年分の現在価値を計算してみます。
最初に松浦のR環境を確認してみます。 コンピューターはMac miniで、CPUはM4 Pro、メモリは24GB、MacOS Tahoe 26.3です。
Rやパッケージのバージョンは以下の通りです。
```{r}
sessionInfo()
R.version
```
今回比較した4つの手法について、それぞれの特徴と、どのような場面で使うべきかをまとめました。
適切な手法を選択する際の参考にしてください。
1. `for`ループ:1つずつ順番に計算する、最も基本的で直感的な方法です。
プログラムの構造が分かりやすく、複雑な条件分岐を書きやすいです。
しかし、Rは繰り返し処理のたびに「解釈」を行うため、回数が増えると極端に時間がかかります。データ数が少ない場合や、計算ロジックが非常に複雑でベクトル化が難しい場合に使います。
2. **ベクトル化** : Rの得意技で、データを「まとめて」一気に計算する方法です。
`for`ループに比べて劇的に高速で、コードも短くシンプルになります。
しかし、計算のために巨大な一時データをメモリ上に作成するため、メモリ消費量が大きいです。データが巨大すぎるとメモリ不足で停止することがありますが、Rでは通常はこの方法が推奨されます。
3. **分割計算** / チャンク化 : データを一定のサイズ(例:100万件ずつ)に区切って、少しずつベクトル化計算を行う方法です。ベクトル化の速さを活かしつつ、メモリ消費量を低く抑えることができますが、コードが少し複雑になります。また、区切る処理が入る分、純粋なベクトル化よりわずかに遅くなります。億単位のデータなど、一気に計算するとメモリ不足になるような大規模データを扱う場合に有効です。
4. `Rcpp` (C++連携) : Rの中から、より高速なプログラミング言語である「C++」を呼び出して計算する方法です。圧倒的に最速です。また、メモリ管理も効率的なので、大規模データでも軽快に動作します。C++の知識が必要で、コードを書く難易度が高いですが、生成AIを活用すれば初心者でも比較的簡単に導入できます。非常に大規模なシミュレーションや、計算速度が最重要となる場合に適しています。
以下では、それぞれの手法で現在価値を計算する関数を定義します。
```{r compare_for_vec, filename="for文とベクトル化の比較"}
# for文版
calc_PV_for <- function(CF, R = 0.1) {
PV <- CF[1]
n <- length(CF)
if (n < 2) return(PV) # 要素数が1以下の場合は即リターン
for (i in 2:n) {
PV <- PV + CF[i] / (1 + R)^(i - 1)
}
return(PV)
}
# ベクトル版
calc_PV_vec <- function(CF, R = 0.1){
year <- 0:(length(CF) - 1)
PV_CF <- CF / (1 + R)^year
NPV <- sum(PV_CF)
return(NPV)
}
# ベクトル版一気に計算版
calc_PV_chunk <- function(CF, R = 0.1, chunk_size = 1e6) { # デフォルトで100万件ずつ処理
n <- length(CF)
total_npv <- 0
# チャンクの開始位置を作成 (例: 1, 1000001, 2000001...)
starts <- seq(1, n, by = chunk_size)
for (start in starts) {
# 終了位置を計算(データの最後を超えないようにminを使う)
end <- min(start + chunk_size - 1, n)
# 1. 必要な部分だけデータを切り出す(ここでメモリ消費を抑える)
cf_part <- CF[start:end]
# 2. 時間tのベクトルを作成(全体の位置に合わせて調整)
# CF[1]がt=0に対応するため、インデックスから1を引く
t_part <- (start:end) - 1
# 3. 部分的な現在価値を計算して合計に加算
# ベクトル化の恩恵を受けつつ、メモリ消費はchunk_size分だけで済む
total_npv <- total_npv + sum(cf_part / (1 + R)^t_part)
}
return(total_npv)
}
# Rcppを使ってC++で高速化版
# C++のコードをRの中でコンパイルして関数化
cppFunction('
double calc_PV_cpp(NumericVector CF, double R) {
double npv = 0;
double discount_factor = 1.0;
double r_plus_1 = 1.0 + R;
int n = CF.size();
for(int i = 0; i < n; ++i) {
// 毎回 pow(1+R, i) を計算すると遅いので、
// 割引率を掛け合わせて更新していく(これが最速)
npv += CF[i] / discount_factor;
discount_factor *= r_plus_1;
}
return npv;
}
')
# 使い方
# calc_PV_cpp(CF, 0.1)
```
比較してみます。
ランダムな将来キャッシュフローを1万年分用意します。
```{r prep_data}
set.seed(121)
n_years <- 10^6 # 100万年分
# 初期投資-100とランダムなキャッシュフロー
CF <- c(-100, runif(n_years - 1, min = 0, max = 100))
```
では、それぞれの方法で計算した速度を比較してみましょう。
正確に比較するため、`microbenchmark`パッケージを使って、それぞれ10回ずつ計測し、その分布を確認します。
```{r run_benchmark}
# 全ての手法をまとめて計測
res <- microbenchmark(
"For Loop" = calc_PV_for(CF),
"Vectorized" = calc_PV_vec(CF),
"Chunked" = calc_PV_chunk(CF),
"Rcpp (C++)" = calc_PV_cpp(CF, 0.1),
times = 10, # 10回繰り返して計測
unit = "ms" # 単位をミリ秒に統一
)
# 結果の数値表示
print(res)
# 結果の可視化(箱ひげ図)
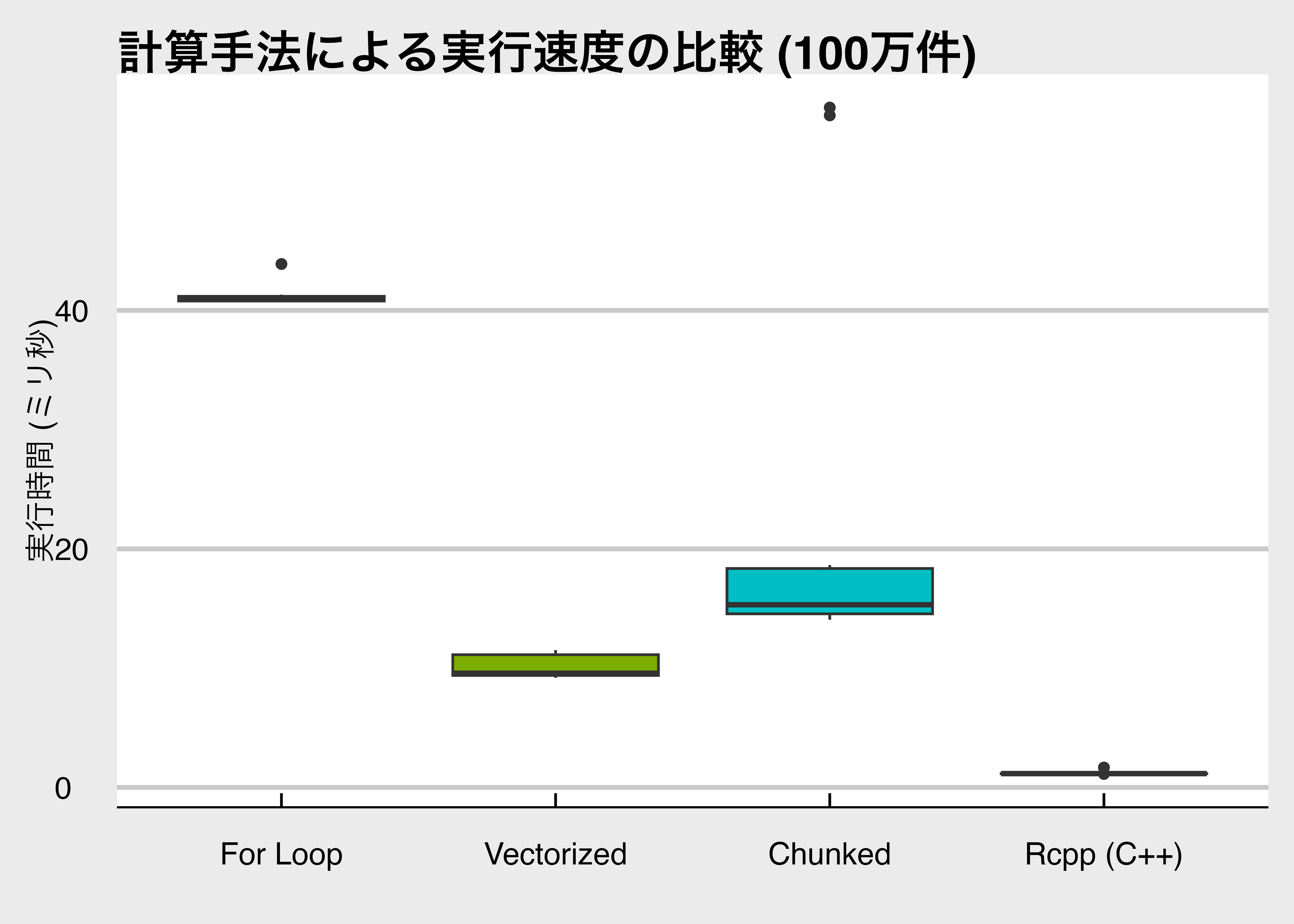
ggplot(res, aes(x = expr, y = time / 1e6, fill = expr)) + # timeを1e6(100万)で割ってミリ秒に変換
geom_boxplot() + # 箱ひげ図を指定
scale_y_continuous(labels = scales::comma) + # 軸の数値をカンマ区切りに(見やすくするため)
labs(title = "計算手法による実行速度の比較 (100万件)",
y = "実行時間 (ミリ秒)",
x = "") + # x軸ラベル(手法名)は自明なので空欄に
theme_minimal() + # ベーステーマ(mystyleがあればそちらに置き換えてください)
mystyle +
theme(legend.position = "none") # 色分けの凡例は不要なら消す
```
実行結果の解釈:
- `for`ループ: 最も遅くなります。Rでのループ処理はオーバーヘッドが大きいためです。
- ベクトル化: for文に比べて劇的に高速化します。**通常はこの方法が推奨**されます。
- Chunked: ベクトル化より少し遅くなりますが、メモリ消費を抑えられるメリットがあります。
- `Rcpp`: 圧倒的に高速です。C++のレベルで最適化されるため、大規模なシミュレーションや反復計算では威力を発揮します。
これがベクトル化による実行速度の効率化です。とはいえ、演算に時間がかかるような大規模データや複雑なシミュレーションをするようになるまで、ベクトル化の恩恵はそれほど大きくないですし、巨大な中間ベクトルをメモリ上に生成するため、計算速度は速くなるがメモリ消費量は増えるます。
ということなので今は気にせずに、読みやすく、確実に動くプログラムを書くことを心がけましょう。
## 演習
各自でやってみてください。
## データフレーム入門
### CSVファイルの読み込み
RでCSVファイルを読み込むには、`readr`パッケージの`read_csv()`関数を使うのがよいでしょう。
たとえば、`data.csv`というファイルを読み込むには、次のように書きます。
```{r}
df <- readr::read_csv("data/ch03_daily_stock_return.csv")
```
この`df`というオブジェクトの型を見てみると,
```{r}
class(df)
```
`spec_tbl_df`,`tbl_df`,`tbl`,`data.frame`という4つの型が表示されます。
`data.frame`という属性が含まれており,`df`が**データフレーム**であることを示しています。
:::{.column-margin}
`spec_tbl_df`は,`readr`パッケージが読み込んだデータフレームに付与する属性で,データの仕様情報を保持しています。
`tbl_df`は,`tibble`パッケージが提供するデータフレームの拡張型で,表示や操作がしやすくなっています。
`tbl`は,`dplyr`パッケージが提供するデータフレームの拡張型で,データ操作が効率的に行えるようになっています。
基本的には,`data.frame`として扱うことができます。
:::
あとは,
- `nrow()`関数で行数を確認
- `str()`関数で構造を確認
- `mean()`関数で平均を計算
- `sd()`関数で標準偏差を計算
- `cor()`関数で相関係数を計算
などを使って,データの中身を確認してみましょう。
- `which.min()`関数や`which.max()`関数で最小値・最大値のインデックスを取得
例えば,最も日次リターンが高い日付を調べるには,次のようにします。
```{r}
best_day_ID <- which.max(df$firm1)
best_day_ID
```
`r best_day_ID`行目が最も日次リターンが高い日付なので,`df`からその行を取り出してみます。
```{r}
df$date[best_day_ID]
```
## ファクター型と日付型
### ファクター型入門
ファクター型あるいは因子型(factor)は,カテゴリカル変数を表現するためのデータ型で,分かりづらいものの,非常に便利かつ重要なデータの型なので,しっかり理解しておきましょう。
数値型や文字列型を因子型に変換する方法には,
1. 基本関数 `factor()`
2. `forcats`パッケージの`as_factor()`関数
3. `forcats`パッケージの`fct_relevel()`関数
先ほど読み込んだデータの`industry`変数は,文字列型ですが,これを因子型に変換してみます。
```{r}
firm_ID <- c(1,2,3)
name <- c("Firm A", "Firm B", "Firm C")
industry <- c("Machinery", "Chemicals", "Machinery")
firm_data <- data.frame(
firm_ID = firm_ID,
name = name,
industry = industry
)
```
この`industry`変数はカテゴリー変数ですが,文字列型になっているので,因子型に変換してみます。
```{r}
firm_data <- firm_data |>
mutate(
industry = forcats::fct_inorder(industry)
)
class(firm_data$industry)
```
`forcats`パッケージには非常に便利な関数がたくさんあるので,ぜひドキュメントを参照してみてください。代表的なものに
- `as_factor()` : 他の型から因子型に変換
- `fct_inorder()` : 出現順にレベルを設定
- `fct_order()` : 頻度順にレベルを設定
- `fct_relevel()` : レベルの順序を変更
- `fct_recode()` : レベルの名前を変更
- `fct_collapse()` : レベルをまとめる
- `fct_lump()` : 頻度の低いレベルをまとめる
があります。
### 日付型入門
日付データとは、年月日や時間を表すデータです。
たとえば、"2026-02-03"や"2025-01-01 00:00:01"のような形式で表されます。
日付データは、文字列として記録されていることが多いので、日付型に変換する必要があります。
日付データの操作には`tidyverse`の`lubridate`パッケージを使うと便利です。
`lubridate`パッケージには、日付データを簡単に操作するための関数がたくさんあります。
- `ymd()` : 年月日形式の文字列を日付型に変換
- `mdy()` : 月日年形式の文字列を日付型に変換
- `hms()` : 時分秒形式の文字列を時刻型に変換
- `ymd_hms()` : 年月日時分秒形式の文字列を日付型に変換
- `today()` : 今日の日付を取得
- `now()` : 現在の日付と時刻を取得
たとえば,次のように日付っぽい値になっている文字列型なら、`lubridate`パッケージが判別して日付型に変換してくれます。
今回は、`2022-01-15`のように年月日の形式なので`ymd()`関数を使います。
```{r}
date <- c("2022-01-15", "2023/01/15")
class(date)
```
<!-- `read_csv()`関数で読み込んだ`date`変数は,すでに`Date`型になっています。 -->
文字列型の日付データを`Date`型に変換したい場合は,次のようにします。
```{r}
date <- lubridate::ymd(date) # 年月日
date
class(date)
```
## 外部パッケージ
`pacman`パッケージの`p_load()`関数を使うと,CRANに登録されているパッケージのうち,必要なパッケージを一括でインストール・読み込みできます。
未インストールのパッケージなら自動でインストールして読み込み、インストール済みのパッケージならそのまま読み込みます。
たとえば,`tidyverse`パッケージと`skimr`パッケージをインストール・読み込みするには,次のようにします。
```{r}
pacman::p_load(tidyverse, skimr)
```
まれに,開発中のパッケージをGitHubからインストールしたい場合があります。その場合は,`pacman`パッケージの`p_load_gh()`関数を使います。たとえば,`username/repo`というGitHubリポジトリからパッケージをインストール・読み込みするには,次のようにします。
```{r}
#| eval: false
pacman::p_load_gh("username/repo")
```
これで,GitHubからパッケージがインストールされ,読み込まれます。
<span class="markp">GitHubリポジトリにあるパッケージはCRANに登録されていないため、自己責任で使用してください。</span>