4 財務データの取得と可視化
4.1 ディスクロージャー制度の概要とデータの入手先
4.1.1 法定開示と適時開示
| 年次開示 | 四半期開示 | 重要事実 | |
|---|---|---|---|
| 法定開示 | 有価証券報告書 | 四半期報告書 | 臨時報告書 |
| 適時開示 | 決算短信 | 四半期決算短信 | 適時開示 |
4.1.2 財務データの入手先
- EDINET:全上場企業の法定開示資料データベース,XBRL形式も提供
- TDnet:上場企業の決算短信データベース, XBRL形式も提供
XBRL(eXtensible Business Reporting Language)形式で財務諸表などの主要情報を公開しています。 XBRL形式を学習しておくと,EDINETやTDnetから直接データを取得してRで分析することもできるので便利ですが,なかなか面倒なことが多いので,大学生なら大学が契約してくれているデータベースを活用しましょう。
4.2 Rを利用した財務データの分析
4.2.1 tidyverseパッケージの概要
tidyverseとは,R神Wickham氏が基本コンセプトを設定し,整然データ(tidy data)に対して一貫した記法でデータを扱えるパッケージ群です。 インストールと読み込みは以下の通りです。
tidyverseパッケージを読み込むことで,次の代表的なパッケージが読み出されます。
-
dplyrデータハンドリング めっちゃ使う -
tidyrtidyデータにもっていく 使う -
readrデータを読み込む めっちゃ使う -
forcatsファクター型変数の操作 めっちゃ使う -
ggplot2データの可視化 めっちゃ使う -
purrr関数型プログラミングで使う 慣れてくると使う -
tibbledata.frameではなくtibbleにする あまり使わない -
stringr文字列の加工・操作 ちょいちょい使う
4.2.2 財務データの読み込み
準備として,サポートサイトにある練習用のデータセットch04_financial_data.csvをダウンロードして,作業ディレクトリに置いておきましょう。
readrパッケージのread_csv()関数を使って,CSVファイルを読み込みます。 read_csv()関数は,
- データの読み込みが高速かつ型の推論が柔軟
- 基本の
data.frameではなく,その拡張版であるtibbleで返す - 列名を勝手に変換しない。
- 文字列を勝手にファクター型にしない(
read.csv()だと勝手にファクターになる)。
という利点があります。
[1] 7920[1] 11# A tibble: 5 × 11
year firm_ID industry_ID sales OX NFE X OA FA OL FO
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2015 1 1 5261. 437. NA 287. 13006. 3543. 4373. 2481.
2 2016 1 1 5949. 564. 50.7 513. 13866. 4642. 4534. 3960.
3 2017 1 1 6505. 691. 29.5 662. 13953. 7744. 5111. 6159.
4 2018 1 1 6846. 751. 86.5 665. 18818. 7285. 5137. 10124.
5 2019 1 1 7572. 959. 298. 660. 18190 9735. 5488. 11362.このfinancial_dataには、11個の変数に観測値が7920個あることがわかります。
-
year: 年度 -
firm_ID: 企業ID -
industry_ID: 産業ID -
sales: 売上高 -
OX: 事業利益(operating income) -
NFE: 純金融費用(net financial expenses) -
X: 当期純利益(net income) -
OA: 事業資産(operating assets) -
OL: 事業負債(operating liabilities) -
FE: 金融資産(financial assets) -
FO: 金融負債(financial obligations)
このデータフレームの構造をdplyrパッケージのglimpse()を使って確認します。
Rows: 7,920
Columns: 11
$ year <dbl> 2015, 2016, 2017, 2018, 2019, 2020, 2015, 2016, 2017, 2018…
$ firm_ID <dbl> 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 4, 4…
$ industry_ID <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ sales <dbl> 5261.40, 5948.96, 6505.06, 6846.38, 7572.24, 7537.63, 3505…
$ OX <dbl> 437.49, 564.14, 691.18, 751.29, 958.53, 778.37, 45.82, 51.…
$ NFE <dbl> NA, 50.667498, 29.543157, 86.486500, 298.049774, -65.45877…
$ X <dbl> 286.64, 513.48, 661.64, 664.80, 660.48, 843.83, 40.07, 49.…
$ OA <dbl> 13005.55, 13865.58, 13952.58, 18818.48, 18190.00, 20462.86…
$ FA <dbl> 3543.43, 4642.16, 7743.99, 7284.72, 9735.13, 10274.25, 225…
$ OL <dbl> 4372.96, 4534.22, 5111.22, 5137.28, 5487.96, 5371.38, 1840…
$ FO <dbl> 2480.72, 3959.70, 6159.02, 10123.91, 11362.22, 13772.15, 2…変数はすべて数値型doubleになっていますが、firm_IDとindustry_IDはカテゴリーを表す変数ですので、数値型ではなくファクター型に変換します。ついでにyearは年度という時間を尺度なので、数値型ではなくfactor型に変換します。 ここで重要なのは、yearはただのファクター型ではなく、順序のあるファクター型とすることです。 ここではforcatsパッケージのas_factor()を使います。
4.3 探索的データ分析
4.3.1 データセットの概要確認
データセットを操作するまえに,データの概要を大まかにつかむ必要があり,この作業を探索的データ分析(exploratory data analysis)といいます。 仮説などを持たず,とりあえず特徴や構造を理解するための方法です。 データセットの概要を確認するために,skimrパッケージのskim()関数を用います。
引数の型に応じて自動的に最適な結果を返す機能を多態性 (polymorphism)といい,多態性をもつ関数を総称関数(generic function)という。
| Name | financial_data |
| Number of rows | 7920 |
| Number of columns | 11 |
| _______________________ | |
| Column type frequency: | |
| factor | 3 |
| numeric | 8 |
| ________________________ | |
| Group variables | None |
Variable type: factor
| skim_variable | n_missing | complete_rate | ordered | n_unique | top_counts |
|---|---|---|---|---|---|
| year | 0 | 1 | FALSE | 6 | 202: 1363, 201: 1356, 201: 1323, 201: 1319 |
| firm_ID | 0 | 1 | FALSE | 1515 | 1: 6, 2: 6, 3: 6, 4: 6 |
| industry_ID | 0 | 1 | FALSE | 10 | 3: 1760, 10: 1702, 7: 1334, 1: 1143 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| sales | 0 | 1 | 166007.00 | 381980.29 | 205.34 | 16103.33 | 40430.74 | 118313.82 | 3496433.0 | ▇▁▁▁▁ |
| OX | 0 | 1 | 7968.91 | 25951.56 | -353606.72 | 399.28 | 1602.88 | 5260.46 | 398034.5 | ▁▁▇▁▁ |
| NFE | 1 | 1 | 64.02 | 5941.34 | -285383.87 | -66.43 | -1.19 | 41.36 | 331035.2 | ▁▁▇▁▁ |
| X | 0 | 1 | 7904.88 | 26910.18 | -357624.83 | 383.27 | 1586.10 | 5204.60 | 572588.7 | ▁▇▁▁▁ |
| OA | 0 | 1 | 152272.76 | 453879.24 | 216.51 | 12559.91 | 30799.24 | 93469.20 | 7987936.2 | ▇▁▁▁▁ |
| FA | 0 | 1 | 80185.35 | 422852.06 | 288.43 | 6835.07 | 19095.33 | 52117.92 | 29250611.1 | ▇▁▁▁▁ |
| OL | 0 | 1 | 50260.88 | 148602.43 | 35.04 | 3964.84 | 10868.31 | 33110.89 | 2817974.8 | ▇▁▁▁▁ |
| FO | 0 | 1 | 70680.61 | 290625.71 | 43.64 | 3757.44 | 11125.20 | 35446.03 | 7026923.6 | ▇▁▁▁▁ |
さらに,データセットのある変数に含まれる固有な要素を抽出するには,unique()関数を用います。
[1] 2015 2016 2017 2018 2019 2020
Levels: 2015 2016 2017 2018 2019 2020固有要素の数を確認するには,unique()関数で取り出した要素の数をlength()関数で返します。 企業-年の企業数と年度数を確認するには次のようにします。
[1] 2015 2016 2017 2018 2019 2020
Levels: 2015 2016 2017 2018 2019 2020[1] 1515[1] 10よってこのデータには10の産業、1515の企業があることが分かります。
4.4 4.3.2 欠損データの処理
ほとんどのデータセットには,欠損値(NA)が含まれているため,この欠損値の処理は非常に重要になります。 欠損値の有無を確認するためには,complete.cases()関数を用いるのが便利です。 欠損値が含まれているとFALSEを返し,欠損値がないとTRUEを返します。
sum()関数で,TRUEの個数を数え上げることもできます。
欠損値の出現に何らかの傾向がある場合,欠損値の削除が生存者バイアス(survivorship bias)をもたらす可能性があります。 たとえば,過去20年間にわたって連結財務諸表データに欠損値が含まれていない上場企業ばかりを分析すると,途中で倒産したり上場したりした企業は削除され,20年間経営し続けている優良企業しかデータに残らない生存者バイアスが発生します。
このようなバイアスを考慮しなくても良いなら,欠損値をもつ個体(unit)のデータ(行)を削除するのが単純な処理となります。 このとき,tidyrパッケージに含まれるdrop_na()関数を用いると簡単に欠損値を含む行を削除できます。 基本関数のna.omit()でもよいですが,tidyr::drop_na()の方がオプションが豊富なのでおすすめです。
[1] 7920[1] 7919欠損値を含む行を削除するのではなく,欠損値に適切な推定値を代入することでサンプルサイズを減らさない方法も開発されていますが,欠損値の出現を説明する確率モデルを仮定し,その推定値を求める必要があります。
詳しくは髙橋・渡辺 (2019) 欠損データ処理:Rによる単一代入法と多重代入法 を参照してください。
さらに欠損値についての議論では,星野・岡田 (2016)「欠測データの統計科学―医学と社会科学への応用」岩波書店がめちゃめちゃ有用です。
4.5 データの抽出とヒストグラムによる可視化
4.5.1 条件にあうデータの抽出方法
教科書では複数の方法が紹介されているが,このメモではtidyverseパッケージを用いた方法だけ取り上げます。具体的には,データベース操作のパッケージであるdplyrの中のfilter()関数について説明します。 さらにmagrittrを用いたパイプ演算子|>を用いたデータの受け渡しの記法を活用して,可読性の高いソースコードを書くことも紹介します。 ここではdplyrパッケージのfilter()関数であることを明示的に示すため、dplyr::filter()と書いていますが、dplyrパッケージを読み込んでいる場合はfilter()と書いても同じです。
filter()で条件を満たすデータのみを取り出し,それをfinancial_data_2015に代入している。
パイプ演算子|>は左のオブジェクトを右の関数の第1引数に代入する,という処理を行います。 つまり,x |> filter(year == 2015)は,filter(x, year == 2015)と同じ意味になります。 パイプ演算子を使うことで,データが次の処理に受け渡されていくプロセスが読みやすくなります。たとえば、
- 欠損値を除去して,
- 2015年のデータを抽出し,
- ROEを計算して,
- 産業ごとに平均値を出す
というよく使いそうな処理を行いたい場合,tidyverseなら次のように書きます。
基本関数の場合は、
financial_data <- na.omit(financial_data)
financial_data_2015 <- financial_data[financial_data$year == 2015, ]
financial_data_2015$ROE <- financial_data_2015$earnings / financial_data_2015$equity
mean_ROE_by_industry <- aggregate(financial_data_2015$ROE,
by = list(financial_data_2015$industry),
FUN = mean)となりますので、上の方が読みやすいことがわかります。
4.6 4.4.2 ヒストグラムによる売上高の可視化
4.6.1 ヒストグラム
ヒストグラム(histogram)は,データの分布を可視化するためのグラフです。 ヒストグラムは,連続データを区間に分けて,区間ごとのデータの個数を棒グラフで表現したものです。したがってヒストグラムの棒の高さは、その区間に含まれるデータの個数を表します。
たとえば、例として生徒100人の身長データがあるとします。 この身長データをRで生成するには,rnorm()関数を使います。
[1] 178.4065 169.3747 172.8323 165.1019 163.0505 170.8189 171.1842 171.4337
[9] 173.3815 167.0513 174.2004 170.3484 166.4049 173.9655 167.7656 172.0565
[17] 179.1289 164.9742 181.2361 170.6859 181.2653 175.2366 176.4297 168.7542
[25] 167.4855 178.9095 173.9411 159.3116 164.0196 169.0665 164.1006 166.7217
[33] 174.3263 157.5980 174.4226 176.9461 165.3805 172.3348 176.9741 164.6956
[41] 174.4786 175.1558 175.8099 169.9111 171.6083 173.7775 161.7053 180.2021
[49] 164.6172 176.2878 164.8292 174.9085 167.8020 165.0033 171.0823 171.8507
[57] 168.7531 179.6715 172.4624 172.6359 170.4693 167.7794 159.7243 172.6310
[65] 166.6284 172.2334 170.2458 165.9444 171.2900 169.8674 170.5213 166.6858
[73] 168.1182 168.4997 163.2053 168.0974 172.6321 164.6079 171.4338 173.9216
[81] 175.5060 168.8628 176.2906 171.2065 170.7491 174.0878 166.6361 170.2087
[89] 179.6689 174.1938 179.8220 159.8830 182.7523 171.7818 178.3772 163.6710
[97] 171.0713 179.3818 171.9733 166.6188100個のデータを眺めていても、なかなか特徴をつかめませんよね。そこでこの身長という連続データを5センチごとの区間に分けます。たとえば、165cm以上、170cm未満の区間には何人の生徒がいるのか、170cm以上、175cm未満の区間には何人の生徒がいるのか、というように区間ごとのデータの個数を数えます。 このとき、区間の幅を5cmにするか、10cmにするか、20cmにするか、ということは、データの特徴をつかむ上で重要なことです。区間の幅を大きくすると、データの特徴がざっくりとしかつかめません。一方、区間の幅を小さくすると、データの特徴が細かくつかめますが、データの個数が少ない区間が多くなり、データの特徴をつかむのに時間がかかります。 やってみましょう。
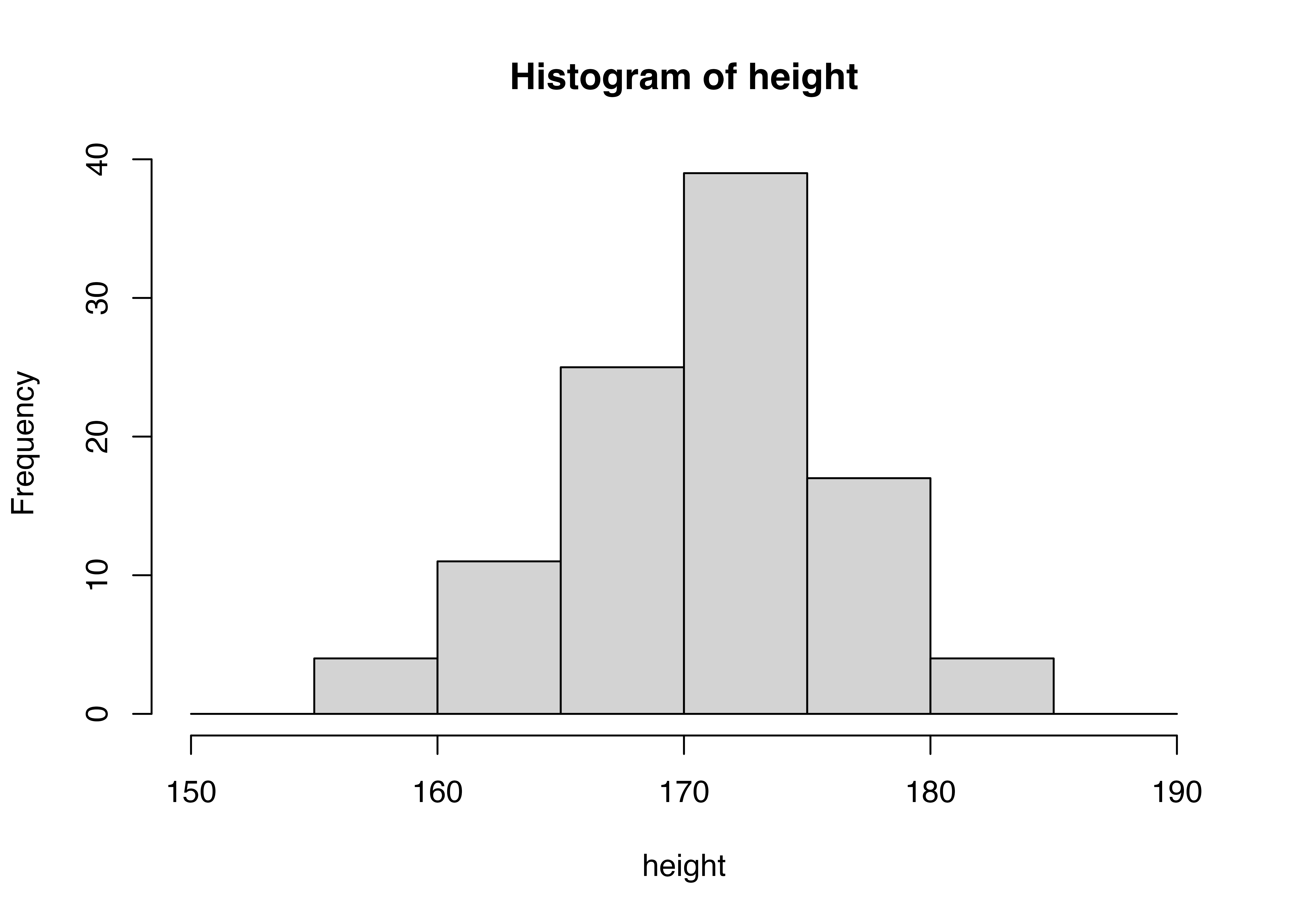
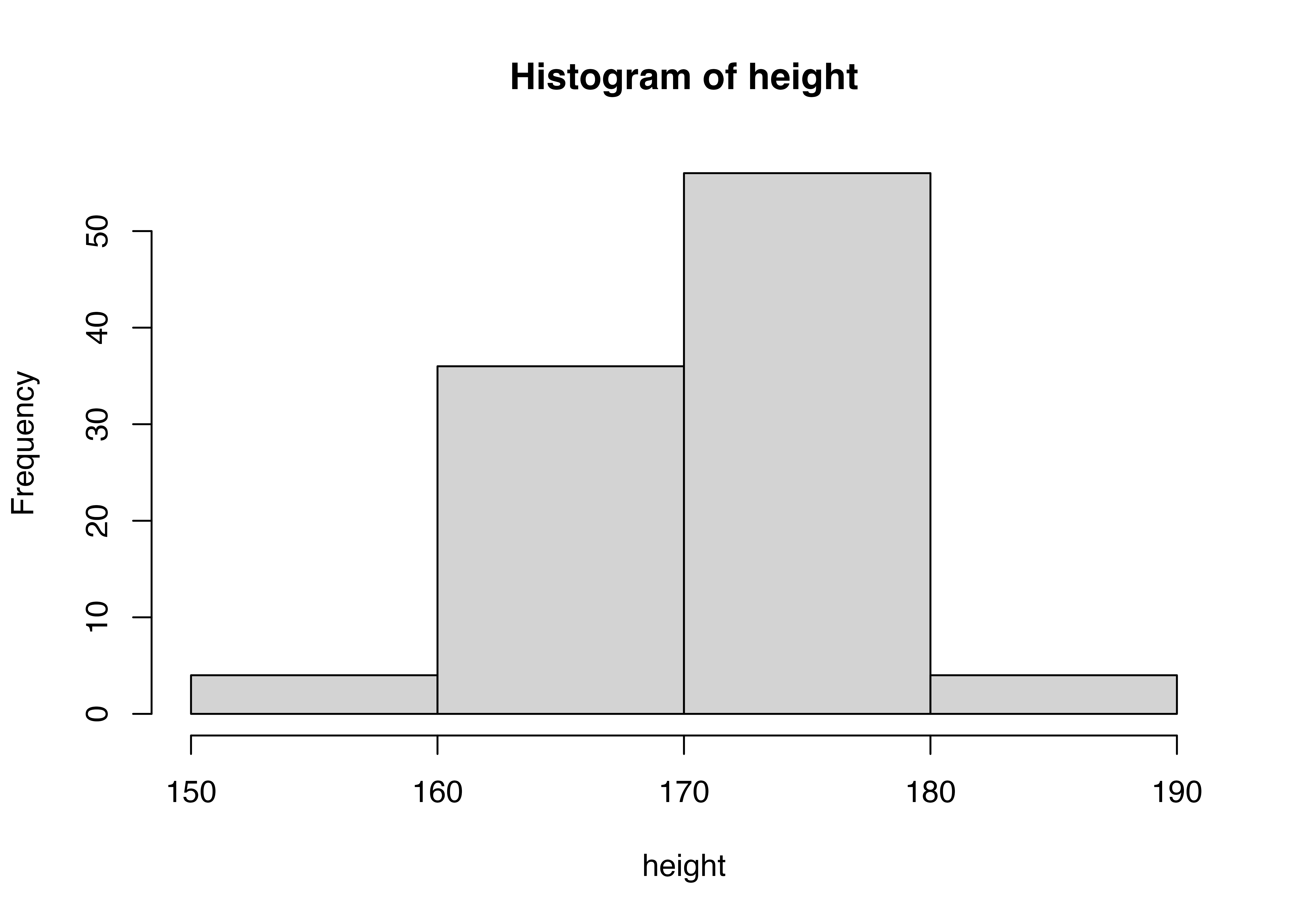
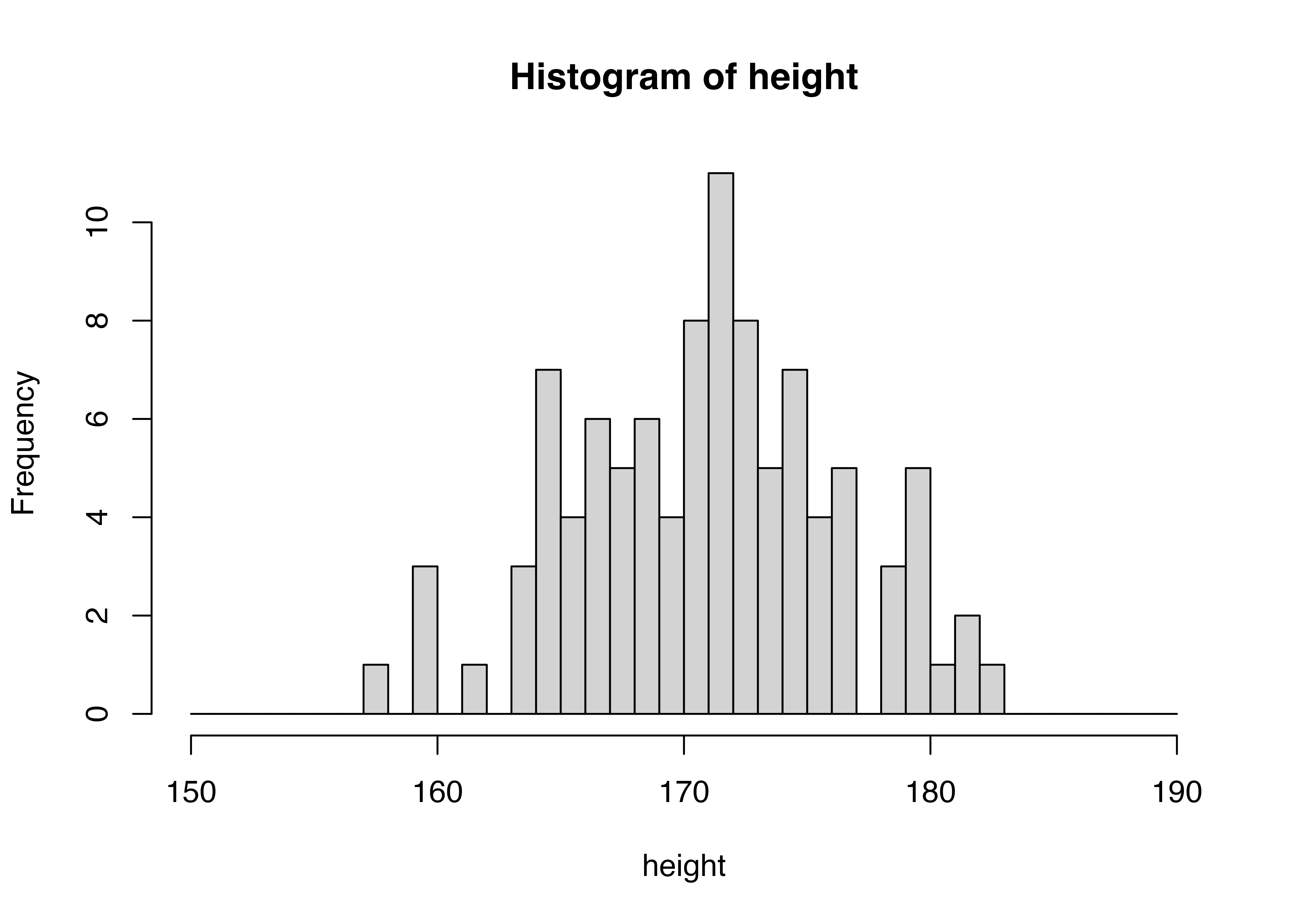
どのヒストグラムがデータの特徴を最も良く表しているのか、を考えて区間幅を設定しましょう。
4.6.2 ggplotでヒストグラム
ヒストグラムを書くためには,基本関数のhist()が最も簡単ですが,より高性能なggplot2を用いたヒストグラムの書き方を説明します。 ここでは、上で作成した2015年のデータfinancial_data_2015を使って、売上高のヒストグラムを書きます。
ggplot2の書き方は少し特殊ですが、慣れてくると非常に便利です。 ggplot2ではレイヤー(階層)を上から重ねていくようにグラフを作っていきます。 まずggplot()関数でグラフの土台を作ります。ggplot()に入れるデータの型はdata.frameでなければならないので注意しましょう。

真っ白で何も出力されていませんが、financial_data_2015というデータフレームを指定して、グラフの土台を作りました。
次に軸の設定をします。ヒストグラムは1変数のグラフなのでx軸のみを設定します。aes()関数で変数を指定します。
横軸が表示されました。 この上に、ヒストグラムを書くためにgeom_histogram()関数を追加します。 ggplot2パッケージでは、geom_***の形でグラフを指定します。例えば、
-
geom_bar棒グラフ -
geom_point散布図 -
geom_line折れ線グラフ -
geom_boxplot箱ひげ図 -
geom_histogramヒストグラム
あたりがよく使われるグラフです。
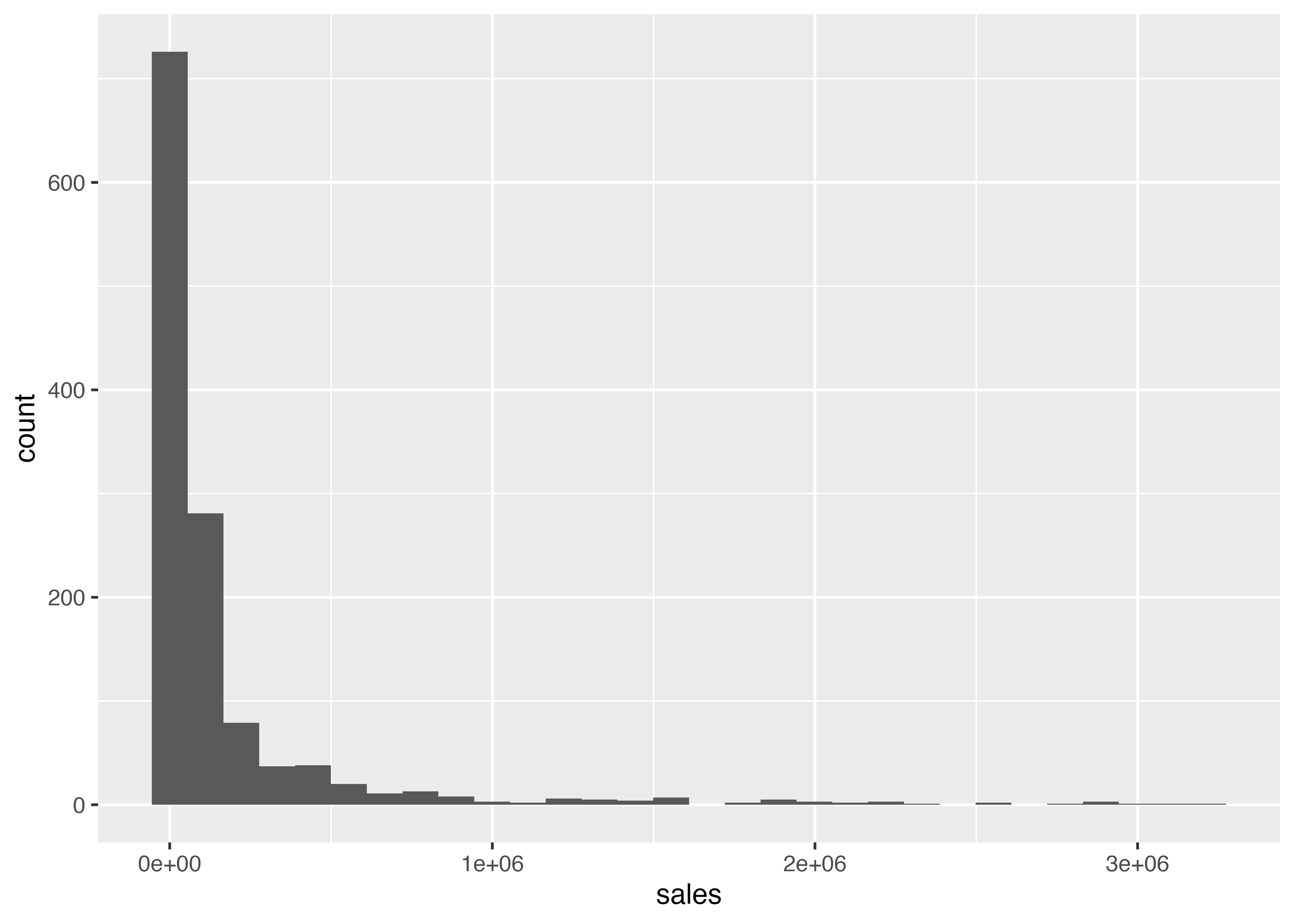
ここでコンソールに,
stat_bin()usingbins = 30. Pick better value withbinwidth.
というメッセージが出ますが、これは「何も指定されなかったので,ヒストグラムのビンの数を30にして作図したけど,オプションのstat_bin()で適切な区間幅をbinwidthで設定してね」ということです。無視しても大丈夫です。
x軸が指数表記となっていて見づらいので,scales()関数を使って表記を変更します。
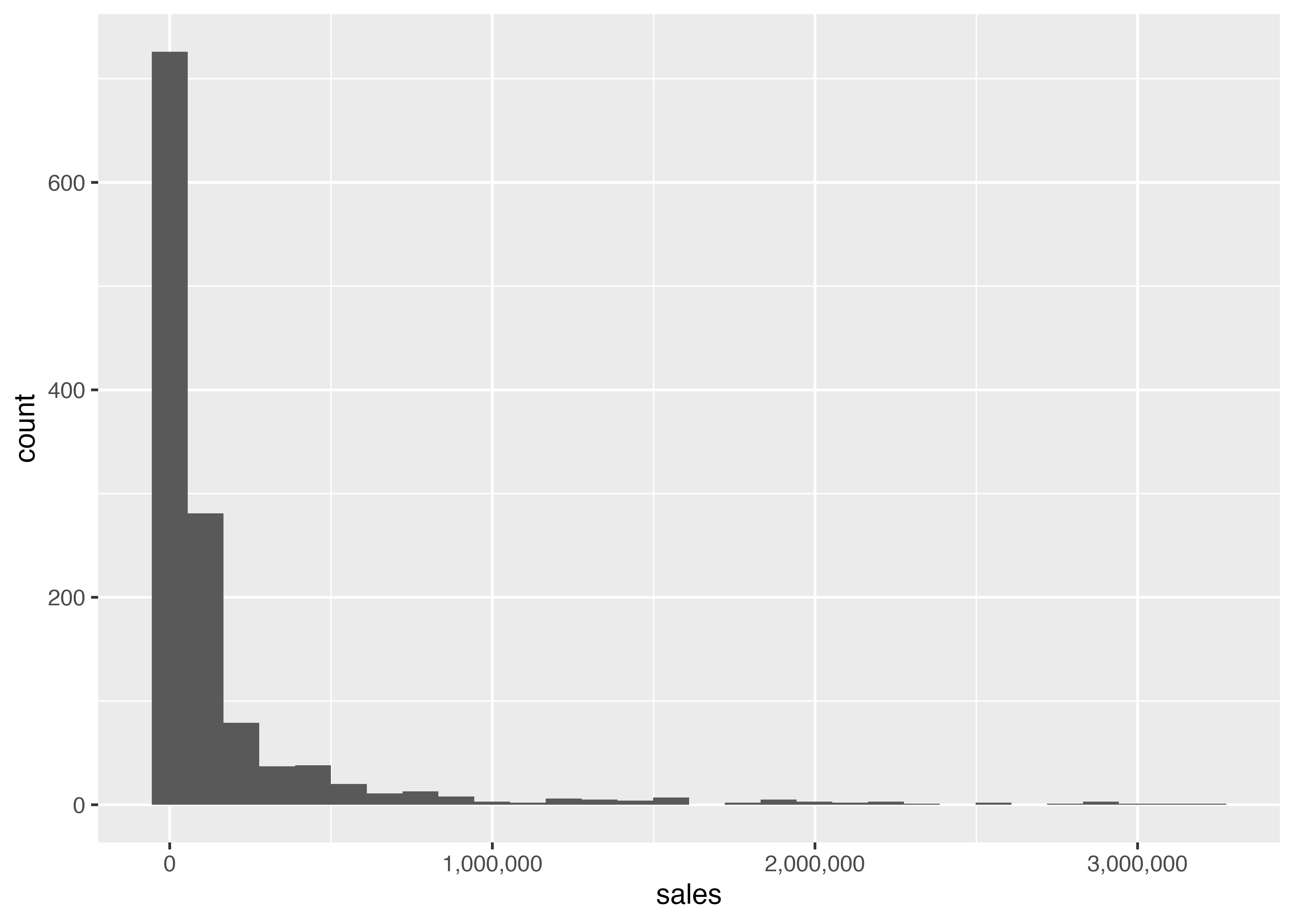
横軸の数値が変化したことが分かります。
また、小数ながら非常に大きな売上高をもつ企業があるため,ヒストグラムの形が左側に集まるように歪んでいます。 そこで売上高を自然対数に変換して,分布の歪みを修整したヒストグラムを書いてみます。 データを変更するので、最初から全部書きます。
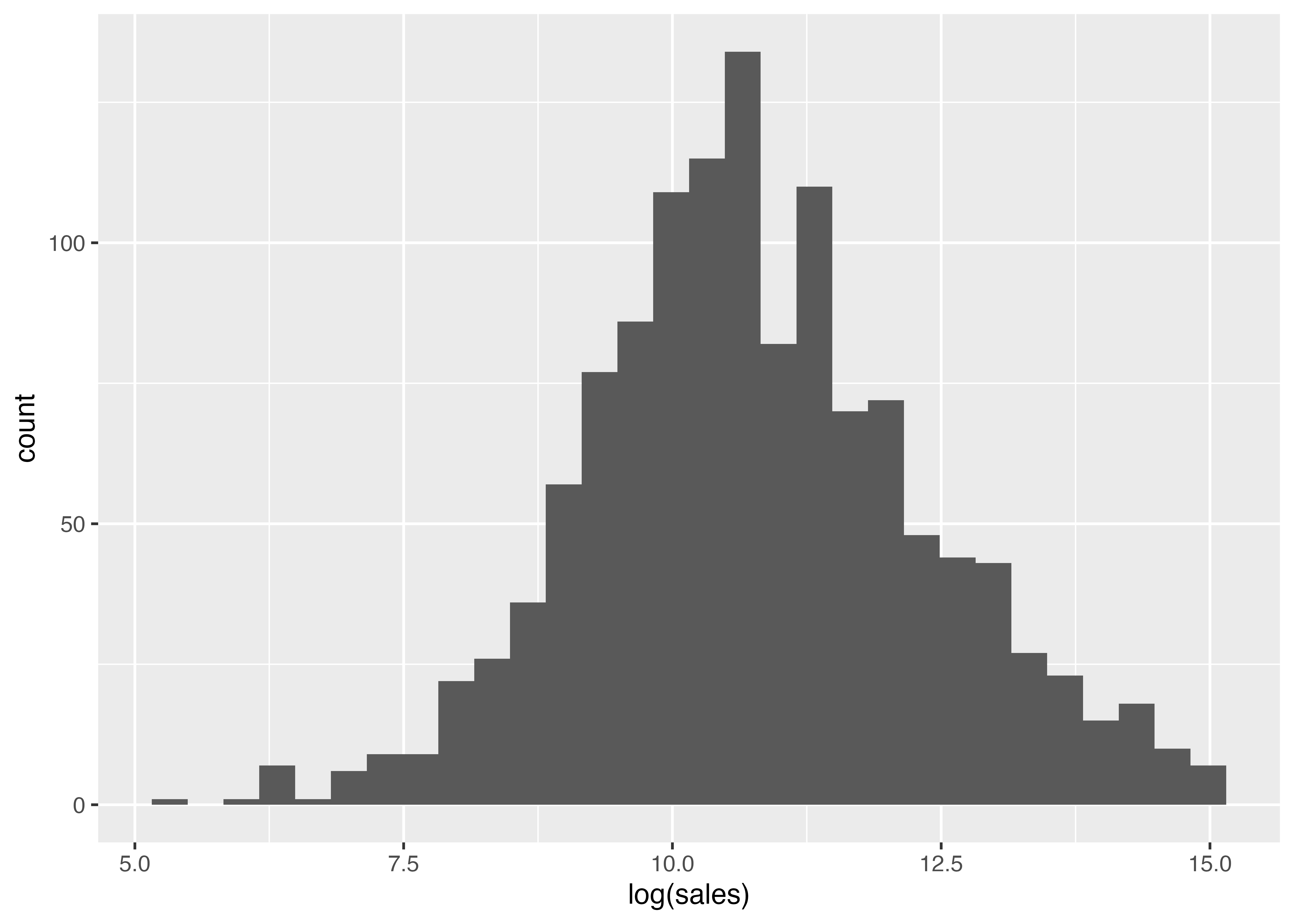
うまくいきました。
4.7 データの集計と折れ線グラフによる可視化
4.7.1 dplyrを用いた集計
もっとデータを加工して、データの特徴をつかむグラフを作成してみます。 データを加工するために、非常に便利なパッケージであるtidyverseのdplyrを用いたデータ加工を説明します。dplyrでよく使う関数に、
summarise()mutate()filter()
があります。これらの関数を組み合わせることで、データの加工が非常に簡単にできます。 特定の変数ごとにデータをグループ化するには,mutate()関数やsummarise()関数の中で、.by = c(vars)という引数を用います。
以前は、dplyrパッケージのgroup_by()関数を用いてグループ化を行っていましたが、複数の変数でグループ化を行ったとき、ungroup()関数でグループ化を解除する必要があり、また全てのグループ化を解除するにも手間でした。 dplyrの新しいバージョンでは、group_byを用いずに、summarise()やmutate()関数の中で.by引数を用いることで、グループ化と集計を一度に行うことができ、また処理後はグループ化が完全に解除されるので、コードがシンプルになります。
たとえば、financial_dataに含まれる売上高を年度ごとに集計してみましょう。
これでN_firms_by_yearというオブジェクトに、financial_dataを年度ごとにグループ化して、年度ごとの企業数N_firmsと平均売上高mean_saleを計算したデータが入っています。 2015年から2020年の6年間のデータがあるので、6行のデータが入っているはずです。 中身を確認しておきましょう。
Rows: 6
Columns: 3
$ year <fct> 2016, 2017, 2018, 2019, 2020, 2015
$ N_firms <int> 1293, 1319, 1323, 1356, 1363, 1265
$ mean_sales <dbl> 173359.5, 170010.9, 157995.4, 160928.2, 161043.7, 173614.9以下の変数について6個のデータが入っていることがわかります。
-
year: 年度 (ord) -
N_firms: 企業数 (int) -
mean_sales: 平均売上高 (dbl)
関数型プログラミング(functional programming)は,現代的なプログラミング・パラダイムの1種であり,定義された関数を用いて各データに対して行いたい処理を切り分ける。Rではapply系関数として,様々な関数が用意されている。tidyverse群では,purrrがある。ちょっと難しいですがpurrr超便利
4.7.2 折れ線グラフによる上場企業数の可視化
データの成形が終わったので,折れ線グラフを作っていきます。 ここではx軸(横軸)を年度year,y軸(縦軸)を上場企業数N_firmsとする折れ線グラフを作ってみます。 折れ線グラフを作るにはgeom_line()関数を使います。
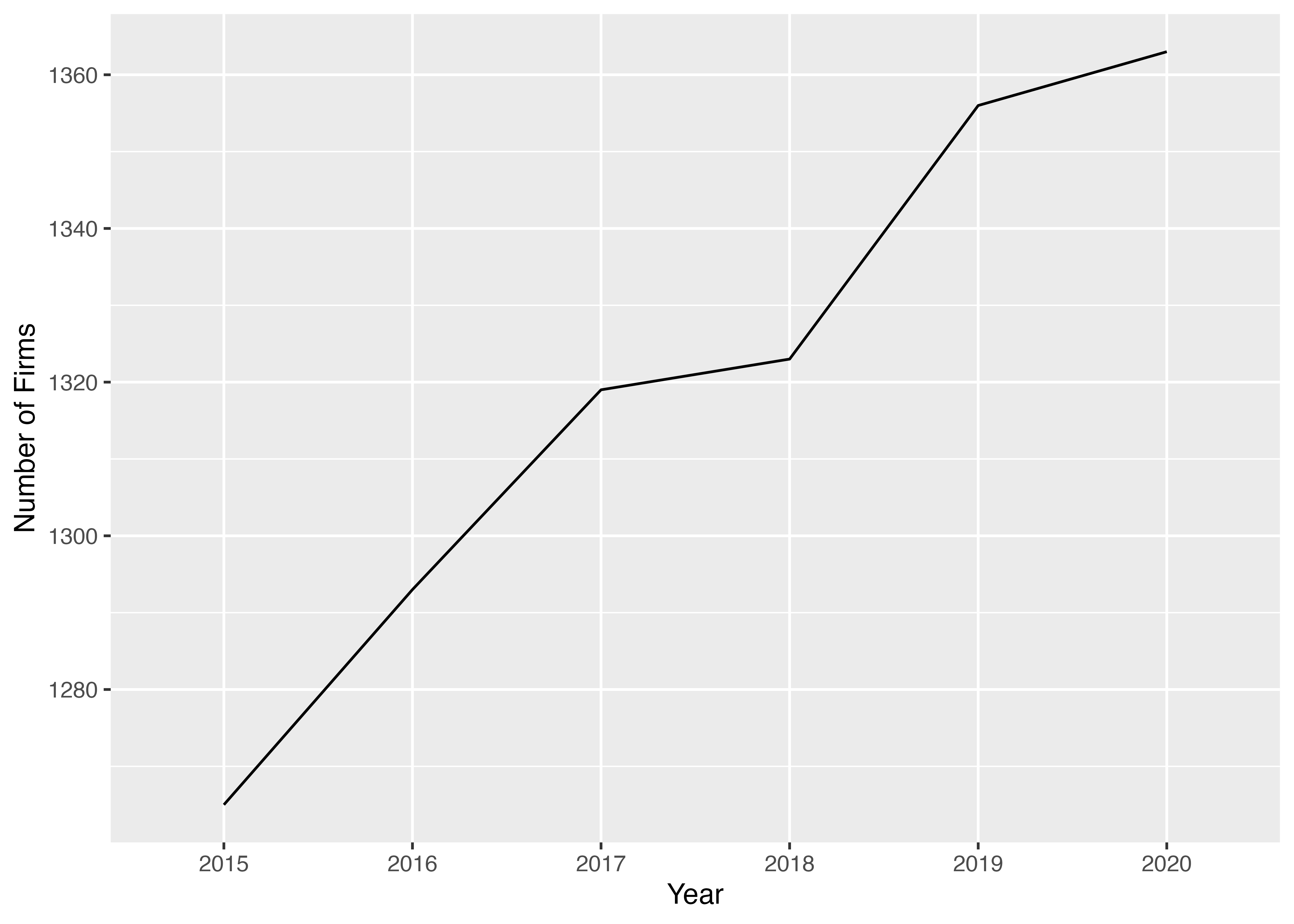
ここで突然現れたgroup = 1というaes()のオプションですが、これはすべてのデータが同じグループに属していることを指定しています。 x軸にファクター型を指定する場合、group = 1を指定しないと、x軸の値ごとに別のグループとして認識されてしまい、折れ線グラフがうまく描けません。
4.8 変数の作成とヒストグラムによる可視化
tidyverseのdplyrパッケージのmutate()関数を用いれば,パイプ演算子|>を用いて可読性の高いシンプルな書き方で、新しい変数を作成することができます。
4.9 キーボードショートカット
Macならcommand + shift + mでパイプ演算子が入力できます。 Windowsならctrl + shift + mです。
ここでは,ROE(Return on Equity)を計算してみます。 ROEの定義は,
ROE_t = \frac{X_t}{BE_{t-1}}
となります。 分子のX_tはt期の当期純利益,分母のBE_{t-1}はt期首の株主資本です。 練習用データであるfinancial_date.csvには,当期純利益はXという列名で収録されていますが、株主資本の列はありません。 よってデータから株主資本は次のように計算します。
BE_t = \underbrace{(OA_t - OL_t)}_{NOA_t} - \underbrace{(FO_t - FA_t)}_{NFO_t}
この計算を行い,新しい変数BEをデータフレームに加えるには,dplyr::mutate()を使います。
分母の株主資本は期首,つまり前期末の数値を用いる必要があります。 1期前の値を参照するには,lab()関数を用います。 ただ,クロスセクションのデータで普通にlag()関数を用いると,次のように別の企業のデータを参照してしまいます。
# A tibble: 10 × 5
firm_ID year BE lag_BE ROE
<fct> <fct> <dbl> <dbl> <dbl>
1 1 2016 10014. NA NA
2 1 2017 10426. 10014. 0.0661
3 1 2018 10842. 10426. 0.0638
4 1 2019 11075. 10842. 0.0609
5 1 2020 11594. 11075. 0.0762
6 2 2015 1055. 11594. 0.00346
7 2 2016 1082. 1055. 0.0468
8 2 2017 1135. 1082. 0.0702
9 2 2018 1184. 1135. 0.0763
10 2 2019 1237. 1184. 0.0770 結果のfirm_IDが2の企業の2015年のROEを計算するには,1期前の企業1の2014年の株主資本を参照する必要があるけれど,2014年のデータは存在しないため、企業2の2015年度のROEは欠損値NAになっている必要があるのに、lag()関数が1つ前の企業1の2020年の株主資本を参照してしまっています。 ROEを企業ごとに計算するために,mutate()関数の引数として、.by = firm_IDを指定します。
# A tibble: 10 × 5
firm_ID year BE lagged_BE ROE
<fct> <fct> <dbl> <dbl> <dbl>
1 1 2016 10014. NA NA
2 1 2017 10426. 10014. 0.0661
3 1 2018 10842. 10426. 0.0638
4 1 2019 11075. 10842. 0.0609
5 1 2020 11594. 11075. 0.0762
6 2 2015 1055. NA NA
7 2 2016 1082. 1055. 0.0468
8 2 2017 1135. 1082. 0.0702
9 2 2018 1184. 1135. 0.0763
10 2 2019 1237. 1184. 0.07702015年のROEが欠損値になっており、正しい計算ができています。 クロスセクション分析におけるlag()関数の問題点を分かりやすくするために、上のようにlagged_BE変数とROE変数を別々に作成しましたが、通常は次のように書きます。
これでROEの計算ができので、次にROEのヒストグラムを作ってみます。
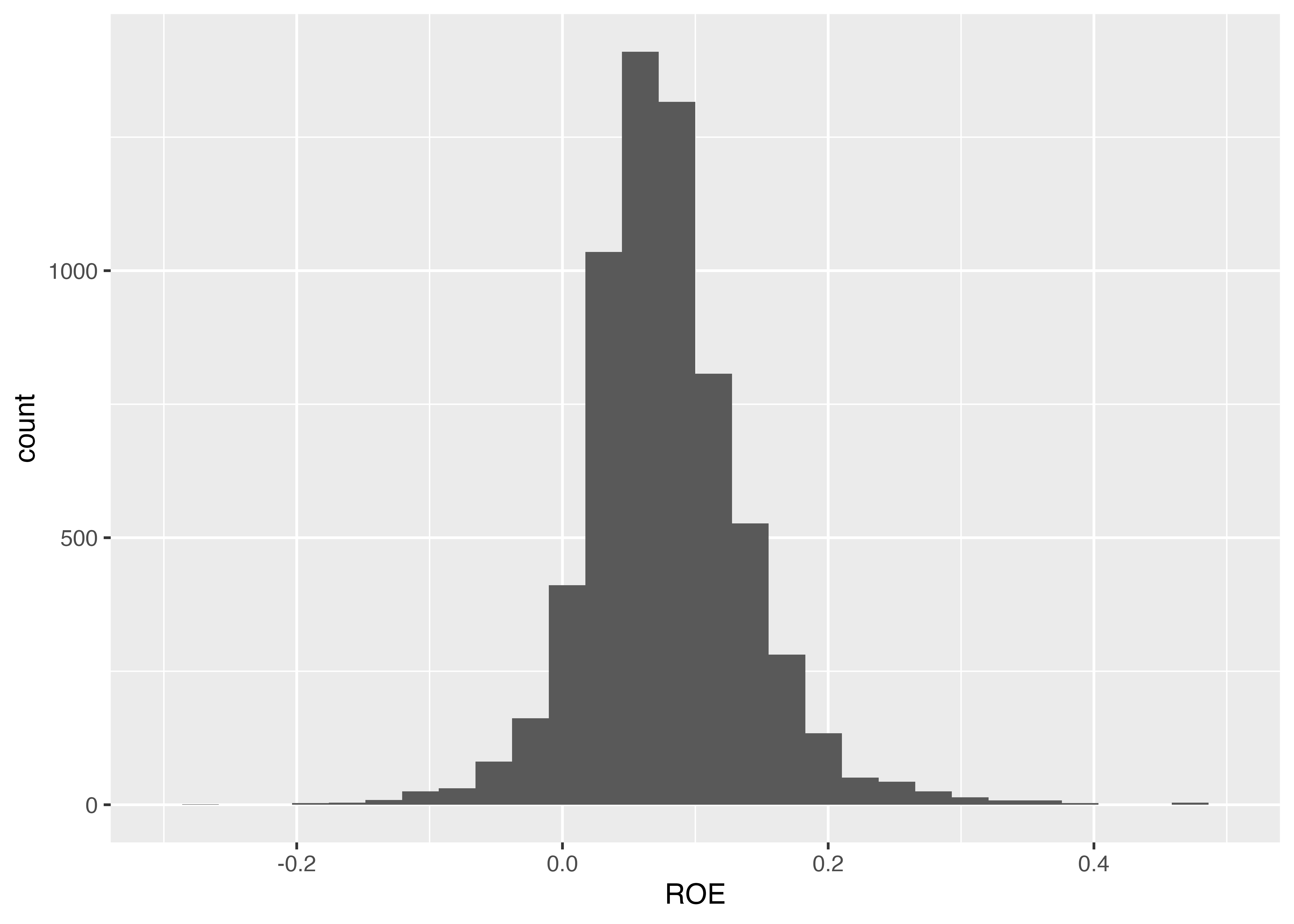
ROEの分布が分かりました。赤字企業が分かりやすいように、ROEがゼロのところに縦線を引いてみます。 縦線を引くにはgeom_vline()を使い、横線を引くにはgeom_hline()を使います。
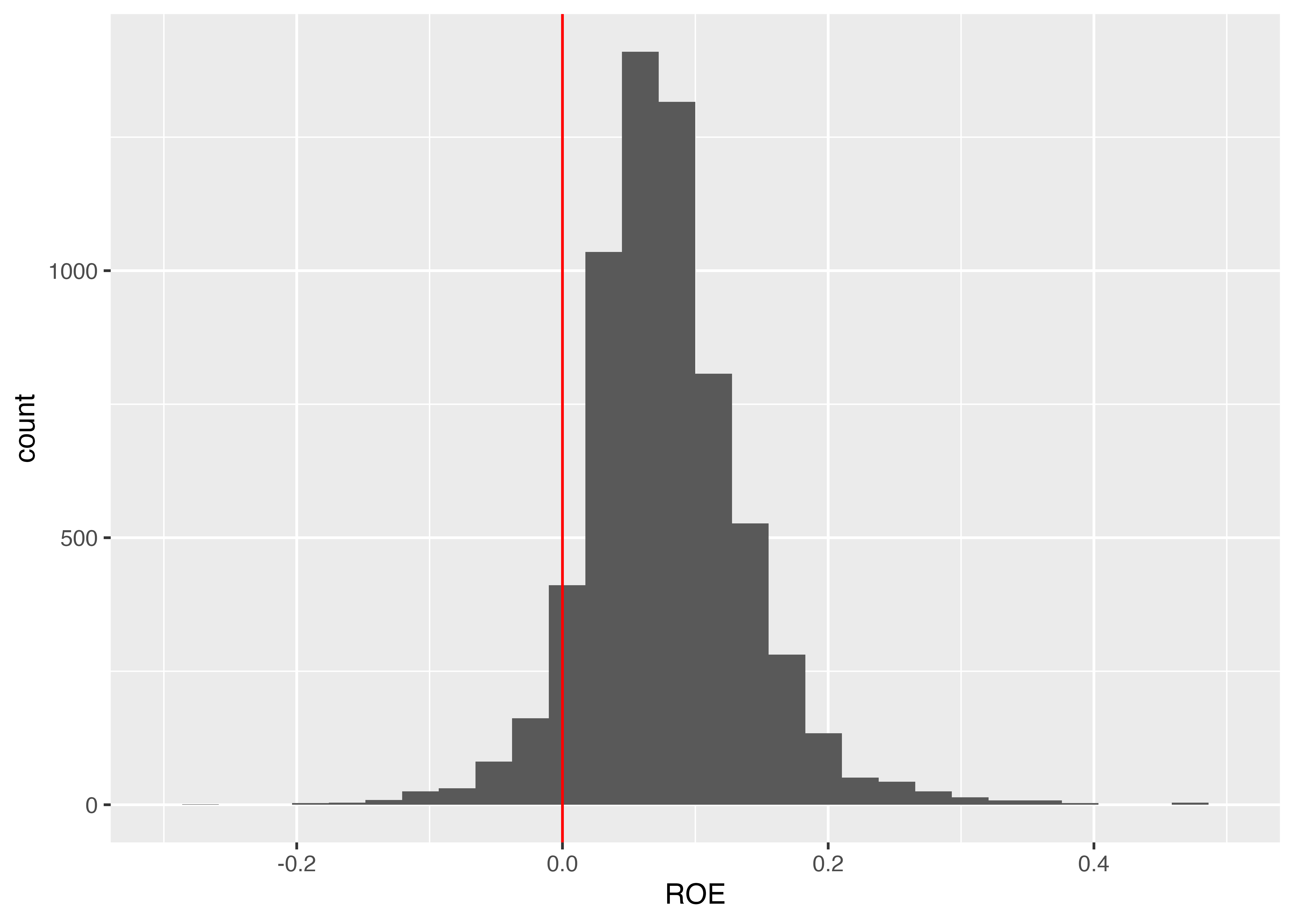
4.10 グループごとの集計とランク付け
4.10.1 産業ごとのROE平均値と棒グラフによる可視化
グループごとに平均値を出すといった処理は,dplyr::summarise()の引数で.by=varを指定すれば簡単です。 ここでは、産業ごとにROEの平均値と標準偏差を求めてみます。 ROEには欠損値が含まれているため、mean()関数を使うとNAが返ってきます。NAを無視して平均値を計算するには、mean()関数のオプションna.rm = TRUEを指定します。
Rows: 10
Columns: 3
$ industry_ID <fct> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10
$ mean_ROE <dbl> 0.07731106, 0.10761577, 0.07548896, 0.07371925, 0.08570296…
$ sd_ROE <dbl> 0.09264764, 0.09530125, 0.05569899, 0.04676826, 0.04859797…10の産業ごとに統計量を計算したので、10行のデータが返ってきました。 このデータを用いて産業ごとのROE平均の棒グラフを作成してみます。
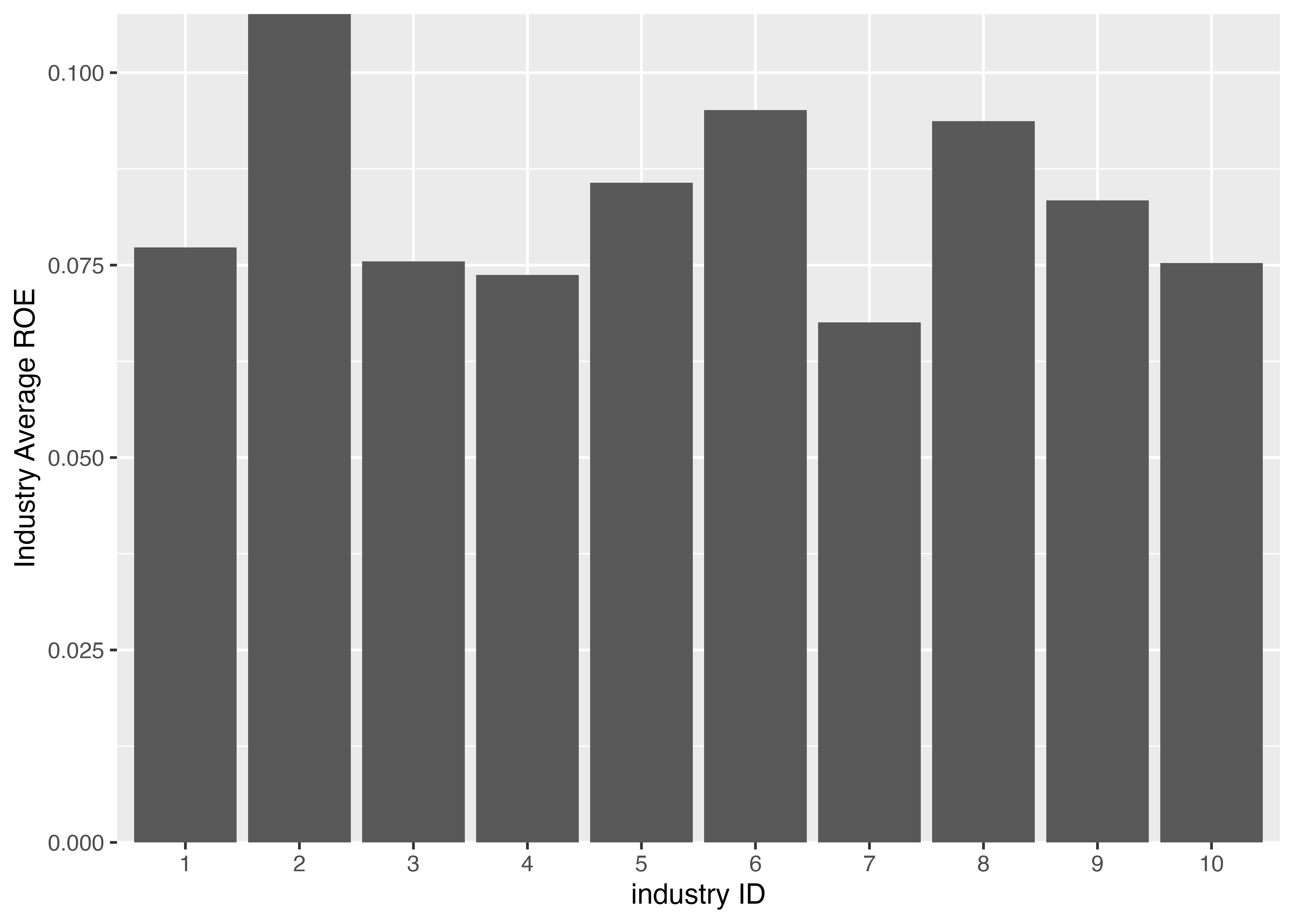
教科書では,パイプ処理で直接ggplot()にデータフレームを渡していますが,個人的に可読性が低くなりオススメできないので,上の例ではデータ操作と作図を分けて書きました。
次に、2020年度の産業別ROEランキングを作ってみます。 ROEを大きい順にならべて、一番大きい企業に1、2番目の企業に2、という風にランキングを表す変数を作成するには、rank(desc())を使います。desc()は降順に並べ替える関数です。
下のソースコードでは、前半のまとまりで、以下の処理を行ったデータを新しいデータフレームROE_rank_dataに代入しています。
-
financial_dataの中から2020年度のデータを抽出し、 - 必要な変数として
firm_ID、industry_ID、ROEの3つを選択し、 -
industry_IDごとにグループ化して、 -
mutate()関数でROE_rank変数を作成し, -
ungroup()関数でグループ化を解除しています。
後半のまとまりでは、上で作成したROE_rank_dataに対して、
- 産業ごとのROEランキング第1位の企業を抽出し、
- ROEが大きい順に並べ替えて、
- それを
knitr::kable()関数で表として出力
という処理をしています。
# 2020年度の産業内のROEランキングの変数を作成
ROE_rank_data <- financial_data |>
filter(year == 2020) |>
select(firm_ID, industry_ID, ROE) |>
mutate( # summarize を mutate に変更
ROE_rank = rank(desc(ROE)),
.by = industry_ID
)
ROE_rank_data |>
filter(ROE_rank == 1) |> # 各産業のランク1のものを抽出
arrange(desc(ROE)) |> # ROEが大きい順
knitr::kable(booktabs = TRUE, # ここから下は表の装飾
caption = "2020年度産業別ROEランキング第1位企業",
position = "h!" # 表示場所はここに
)| firm_ID | industry_ID | ROE | ROE_rank |
|---|---|---|---|
| 929 | 7 | 0.5641813 | 1 |
| 475 | 3 | 0.4975356 | 1 |
| 8 | 1 | 0.3882552 | 1 |
| 242 | 2 | 0.3749986 | 1 |
| 661 | 5 | 0.2673141 | 1 |
| 1042 | 8 | 0.2559963 | 1 |
| 1380 | 10 | 0.2497929 | 1 |
| 1167 | 9 | 0.2346232 | 1 |
| 619 | 4 | 0.1491307 | 1 |
| 719 | 6 | 0.1422026 | 1 |
4.11 上級デュポン・モデルによるROEの分析とその可視化
上級デュポン・モデルとは,次式で表されるROEの分解式です。
\begin{aligned} ROE_t := \frac{X_t}{BE_{t-1}} &= \underbrace{\frac{OX_t}{NOA_{t-1}}}_{RNOA_t} + \underbrace{\frac{NFO_{t-1}}{BE_{t-1}}}_{FLEV_{t-1}} \times \left[ \frac{OX_t}{NOA_{t-1}} - \frac{NFE_t}{NFO_{t-1}} \right] \end{aligned}
各変数の意味は以下の通りです。 - X : 当期純利益(net income) - BE : 株主資本(book of equity) - OX : 事業利益(operating income) - NOA : 純事業資産(net operating assets) - NFO : 純金融負債(net financial obligations) - NFE : 純金融費用(net financial expenses)
RNOA_tは,ATO_tとPM_tとに分割できます。
\underbrace{\frac{OX_t}{NOA_{t-1}}}_{RNOA_t} = \underbrace{\frac{sales_t}{NOA_{t-1}}}_{ATO_t} \times \underbrace{\frac{OX_t}{sales_t}}_{PM_t}
いくつかの変数は,元のデータには含まれていないので,与えられたデータから計算する必要があります。 dplyr::mutate()関数を用いて新しい変数を作成し,データフレームに追加します。
financial_data <- financial_data |>
mutate(
NOA = OA - OL, # 純事業資産 = 事業資産 - 事業負債
RNOA = OX / lag(NOA), # 会計上の事業リターン
PM = OX / sales, # 利ざや profit margin
ATO = sales / lag(NOA), # 純事業資産回転率
NFO = FO - FA, # 純金融負債 = 金融負債 - 金融資産
lagged_FLEV = lag(NFO) / lagged_BE, #期首財務レバレッジ
NBC = NFE / lag(NFO), # 債権者のリターン net borrowing cost
ROE_DuPont = RNOA + lagged_FLEV * (RNOA - NBC), # 上級デュポン・モデルによるROE
.by = firm_ID # 企業ごとにグループ化
)ROEの分解式が合っているかどうかを確認するため,all.equal()関数を使って,第1引数と第2引数が等しいかどうかを判定してみます。 普通に計算したROEと上級デュポン・モデルの分解したものから計算したROE_DuPointとの比較しています。
[1] "Mean relative difference: 4.396878e-06"となり,差の平均は4.396878 \times 10^{-6}となり,ほぼ0となっていることから,上級デュポン・モデルの分解式が正しいことが確認できます。 完全にゼロにならない理由は計算の過程で生じる丸め誤差によるものです。
4.11.1 箱ひげ図による産業別比較
産業別で利ざやPMがどのように分布しているのかを調べるために,箱ひげ図(box plot)を作ってみます。 箱ひげ図は,データの分布を可視化するためのグラフで,第1四分位点,中央値,第3四分位点,(異常値をのぞく)最大値,(異常値をのぞく)最小値を表現できる,非常に情報量の多いグラフです。
ggplot2パッケージのgeom_boxplot()関数を用いることで,データフレームから箱ひげ図を作図できます。
先に作成したデータフレームfinancial_dataを用いて,PMの箱ひげ図を作成してみましょう。 あまり多くの箱ひげ図を作っても見づらくなるので,最終年度のデータ で,産業IDが2〜6までの企業に限定します。
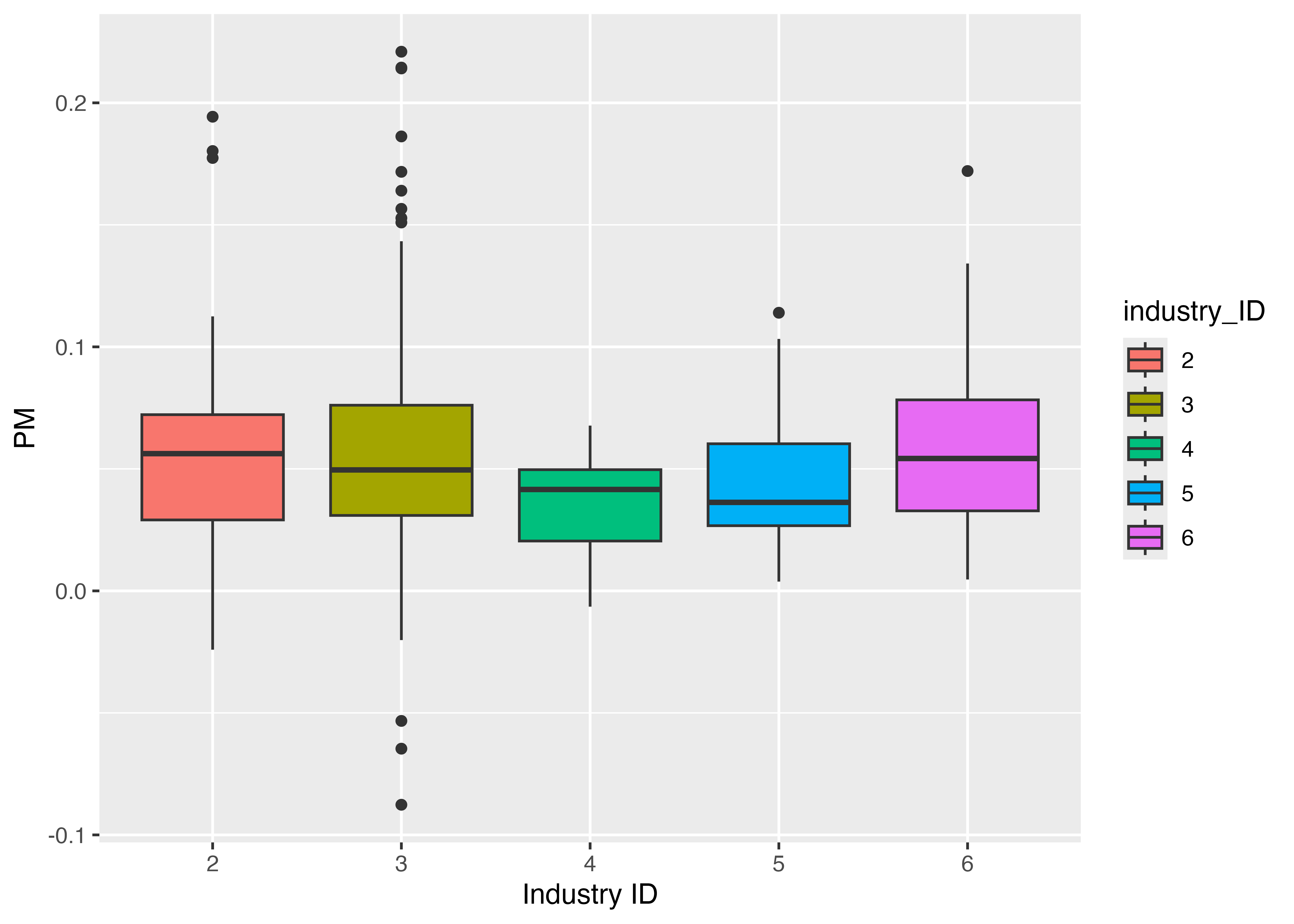
箱ひげ図から,産業ごとに利ざやの分布が異なることがわかります。とりわけ産業3は利ざやの散らばりが大きく,産業4は非常に散らばりが小さいことが分かります。
4.11.2 散布図による産業別比較
次に産業ごとに ATO(純事業資産回転率)と PM(売上高事業利益率)がどう分布しているか散布図を書いてみます。 ここでは異常値の影響を受けにくい統計量である中央値(median)を計算し,散布図を作成してみます。
df_ind_median <- financial_data |>
summarise(
median_ATO = median(ATO, na.rm = TRUE), # ATOの中央値
median_PM = median(PM, na.rm = TRUE), # PMの中央値
.by = industry_ID # 産業ごとにグループ化
)
g <- ggplot(df_ind_median) +
aes(x = median_ATO, y = median_PM, label = industry_ID) + # 散布図
geom_point() + # 散布図
geom_text(vjust=-1) # ラベル
print(g)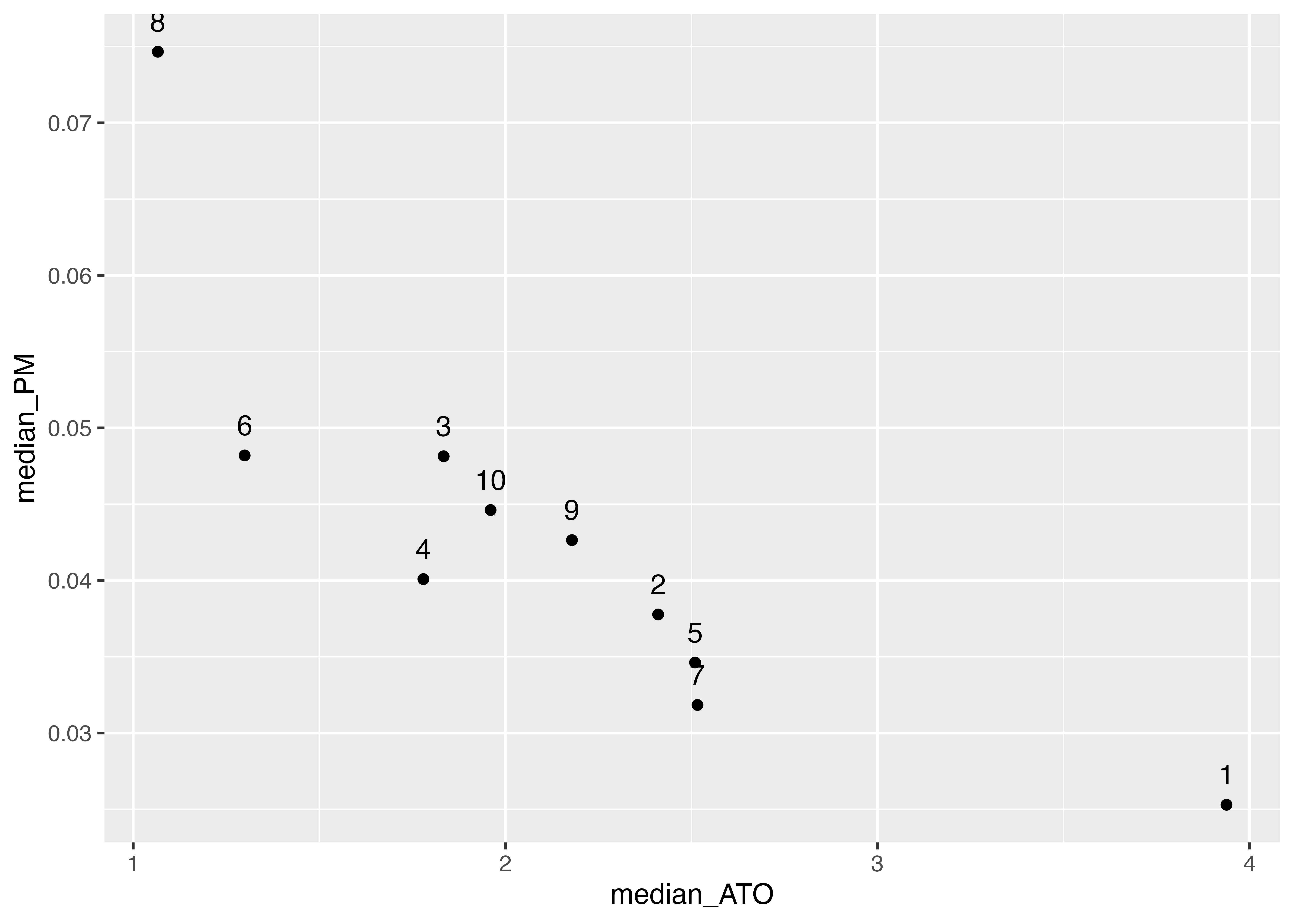
この産業ごとに計算された中央値のデータを用いて,線形回帰直線を引いて,ATOとPMの関係を見てみます。
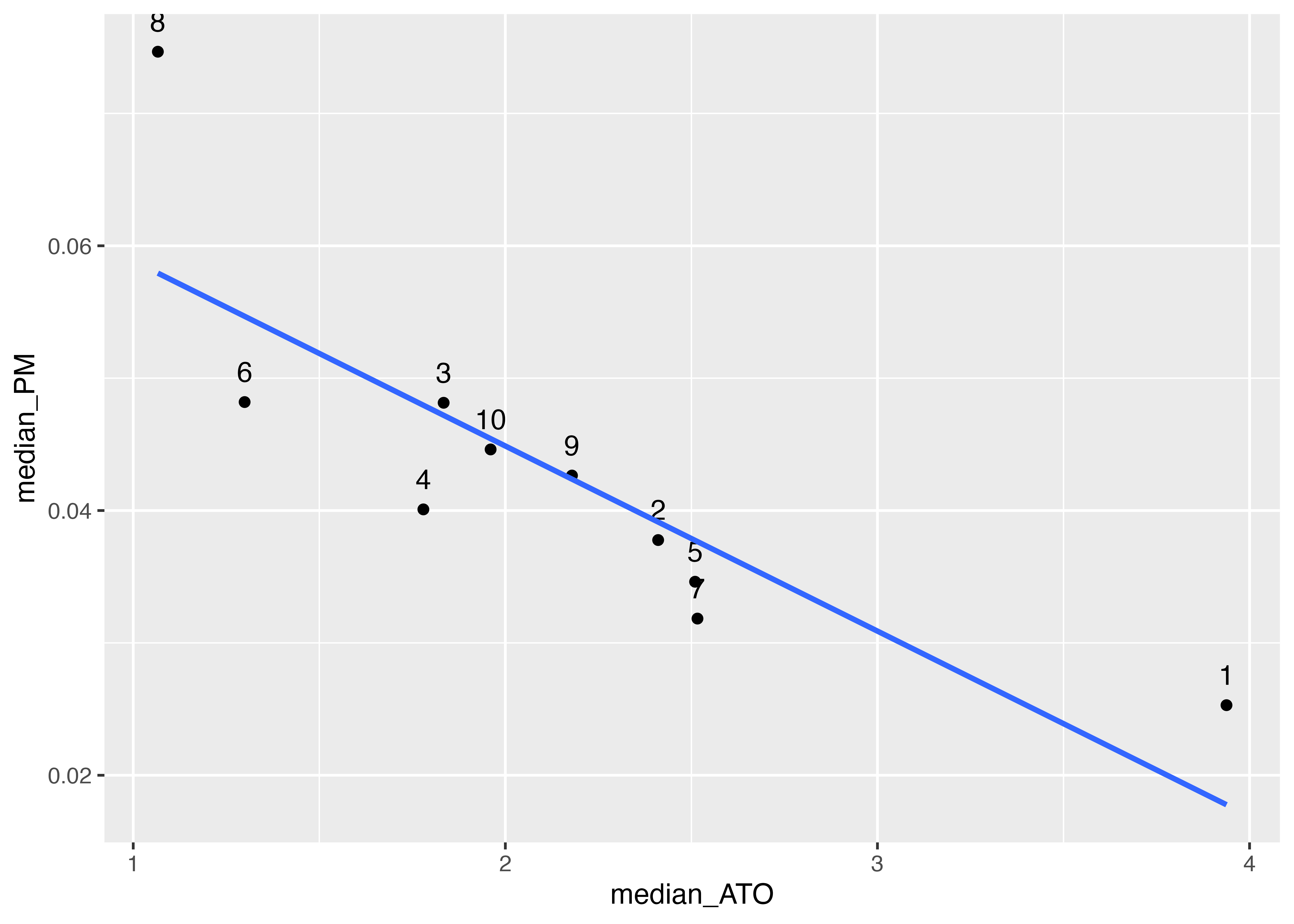
いい感じですが,会計学入門(1.3.4節)で学習したATO \times RM = RNOAという関係のとおり,データからもATOとPMとの間にトレードオフの関係があることが予想されています。 もし理論どおりの関係であればデータはATO = RNOA / PMといった反比例の関係になるはずです。これを示すため,RNOAを一定としたときのATOとPMの関係,つまりを図に書き込んでみます。 関数をグラフとして図に追加するためにstat_function()関数を用います。
stat_function()関数の引数は,fun = function(x) xの関数系, linetype = “スタイル”とします。 ここでは,function(x)でxの関数であることを指定し,median_RNOA / xとしてます。
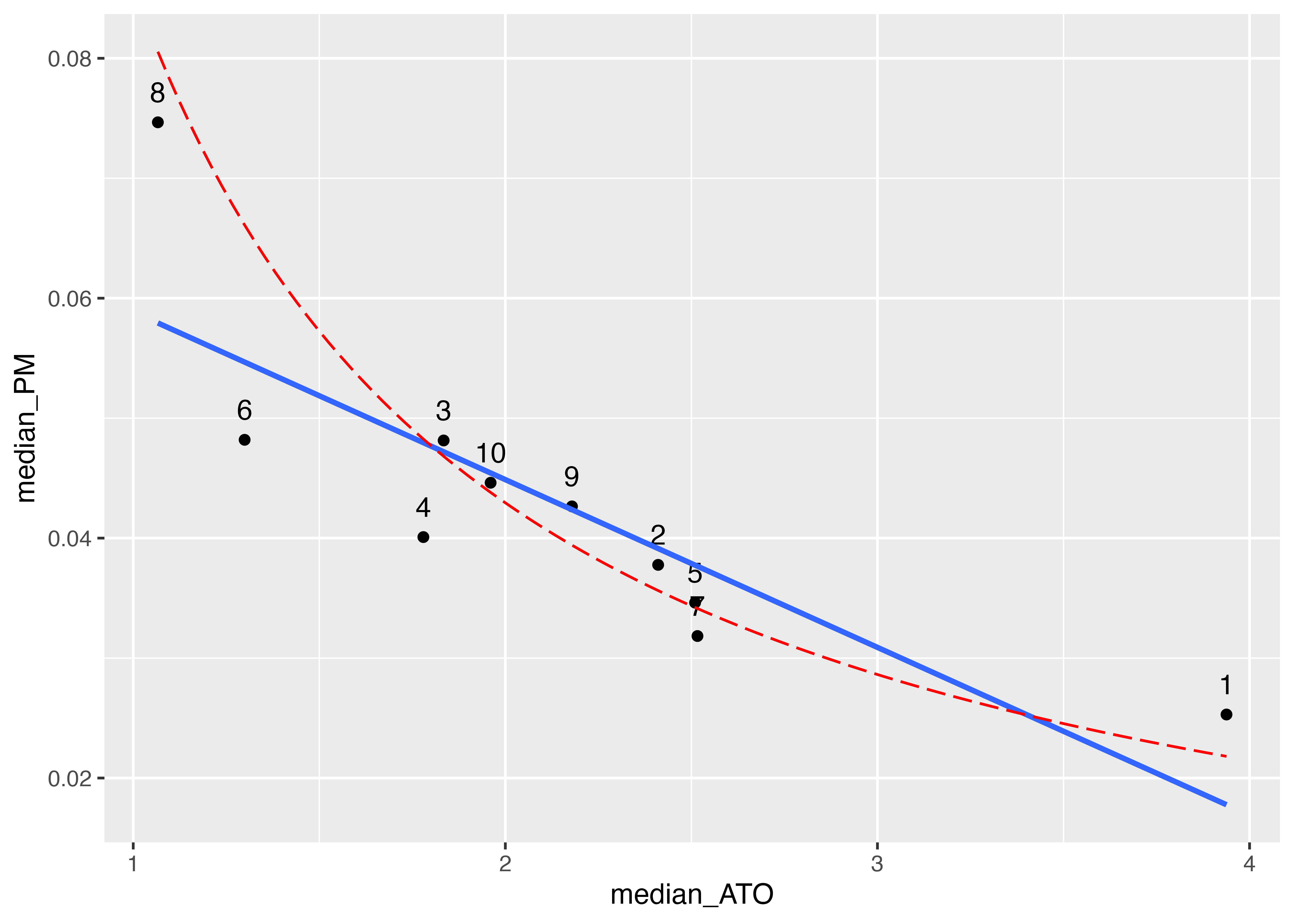
かなりあてはまりが良さそうな線が引けました。 このように,データを可視化することで,理論とデータの整合性を確認することができます。