ここではRの得意とするデータの可視化 (data visualization)について学びます。 いままで利用してきたtidyverseにはグラフ作成のためのパッケージとしてggplot2があります。 本章では,ggplot2の使い方を学習し,読者にもデータの特徴を伝えやすく,シンプルで,美しいグラフの作成を目指します。 ビッグデータを容易に扱えるようになった昨今において、データの可視化スキルの重要性は高まってきており、以下のような書籍が出版されています。いずれも非常に良い書籍ですので、興味のある方は読んでみてください。
1冊目はアメリカで絶賛された可視化本が翻訳されたものです。ソースコードとともに、データの可視化の基本や実例を学べます。 2冊目は、統計学を可視化という視点で学習する本です。 3冊目は前の2冊とは若干毛色が異なっており、ShinyというPosit社が開発したパッケージを使って、インタラクティブなグラフを作成する方法を学べます。
可視化のパッケージ
いままで利用してきたtidyverseにはグラフ作成のためのパッケージとしてggplot2が含まれています。 本章では,このggplot2パッケージの使い方を学習し,読者にもデータの特徴を伝えやすく,シンプルで,美しいグラフの作成を目指します。 またggplot2の機能を拡張するためのggthemesとpatchworkも一緒に読み込んでおきます。 まだインストールできていなければ,始めにインストールしておいてください。
# install.packages("ggthemes") # fist time only # install.packages("patchwork") # first time only library ( tidyverse ) # とりあえずこれ
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
また、Macだとggplot2で作図したグラフで日本語が表示されないことがあります。 以下の設定をすることで文字化けを回避することができます。
# グラフ内の日本語文字化け対策のおまじない knitr :: opts_chunk $ set ( dev = "ragg_png" )
あるいは,ggplotのグラフ作成時に,base_family = "フォント名"として,作図で用いるフォントを指定することでも文字化けを回避できます。 たとえば次のように,list() mystyleというオブジェクトに入れておけば,作図時に+ mystyleを付けるだけで, フォントやグラフの見た目を指定できます。
mystyle <- list ( # mystyleとして設定を保存 theme_few ( ) , # ggthemesのテーマ
theme (
text = element_text (
size= 16 , # フォントサイズ
family = "HiraKakuProN-W3" # ヒラギノフォント
) ) )
以下の作図で使うデータを読み込んでおきましょう。
df <- read_csv ( "data/presemi_part_two.csv" )
Rows: 44527 Columns: 12
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (3): 会社コード, 企業名, 決算期
dbl (9): 決算種別, 連結基準, 決算月数, 上場コード, 日経業種コード, 売上高, 親会社株主に帰属する当期純利益, 資産合計, 株主資本...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
# df <- read_csv("https://so-ichi.com/presemi_part_two.csv") names ( df )
[1] "会社コード" "企業名"
[3] "決算期" "決算種別"
[5] "連結基準" "決算月数"
[7] "上場コード" "日経業種コード"
[9] "売上高" "親会社株主に帰属する当期純利益"
[11] "資産合計" "株主資本"
練習用の財務データを読み込み,オブジェクトdfに代入しました。 dfのクラスはspec_tbl_df, tbl_df, tbl, data.frameです。
ggplotパッケージの基礎
前節で、カテゴリー変数のファクター化,with() table() group_by() summarize() ggplot2パッケージを使います。
ggplot()関数の基本的な使い方と変数の特徴把握
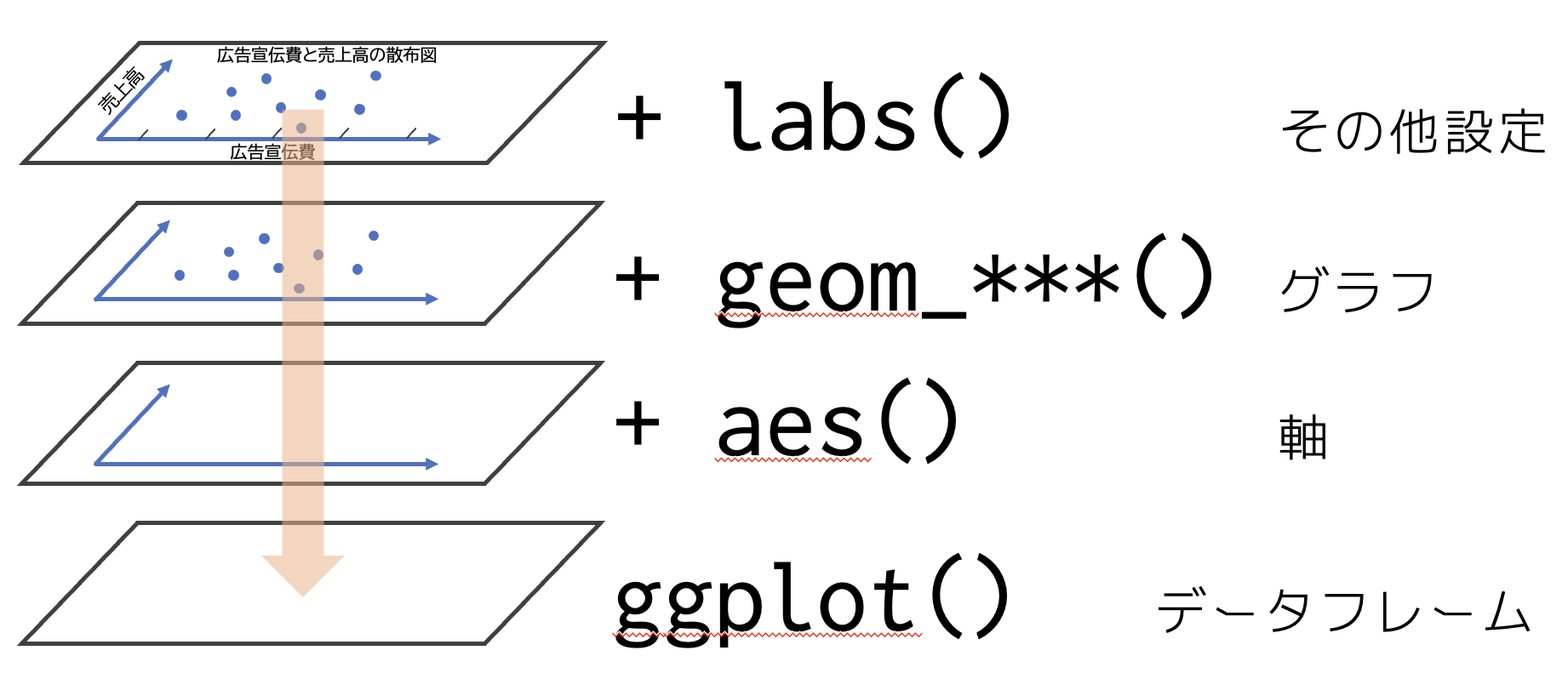
ggplot2パッケージのggplot()
data = : データフレーム
mapping = aes() : グラフの構成要素を指定する関数
geom_*** : グラフの種類を指定する関数
各種オプション
最初の注意点として,ggplot() data =でtibbleかdata.frameを指定する必要があります。 データの型に気をつけましょう。
では,年度ごとに平均ROEを示した折れ線グラフを作図していきます。 ROEの定義は,
ROE_{t} = \frac{\text{親会社株主に帰属する当期純利益}_t}{株主資本_{t-1}}
となります。 計算してみましょう。 決算期の最初の4ケタを取り出し年度という変数も同時に作成しておきます。
ROEの記述統計量を確認してみましょう。
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
-Inf 0.026 0.068 NaN 0.119 Inf 3321
Min.やMax.がInfとなっており, 欠損値NA'sが3321個もあることが分かります。 Infとは無限大を表す特殊な値で,ROEの計算プロセスで分母がゼロとなっている値があることが分かります。 分数を計算するときは,分母がゼロとなっている値がないかどうか,チェックするようにしましょう。 ついでに、総資産回転率も計算しておきます。
Min. 1st Qu. Median Mean 3rd Qu. Max.
-32.16667 0.02692 0.06837 0.06600 0.11938 136.14286
これで最小値と最大値が計算されるようになりました。 次に,年度ごとの平均ROEを計算して、df_yearというオブジェクトに代入しておきます。
これで準備が整ったので、ggplot()
1変数の可視化
まずは,1変数の可視化から始めていきましょう。 1変数の可視化とは,1つの変数の分布を可視化することです。 1変数のグラフの代表的なものとして、ヒストグラム (histogram)があります。 ggplot2パッケージでは、
で作図します。
まず土台となるデータフレームを指定します。 ここでは、年度別に集計する前のdfを使います。
土台ができましたが,まだ何も表示されていません。 次に,グラフの構成要素を指定するために,mapping = aes()で,軸を指定します。 1変数のグラフの場合、aes(x = 変数名)とすることで、変数を指定します。
作図する変数としてROEが指定されました。
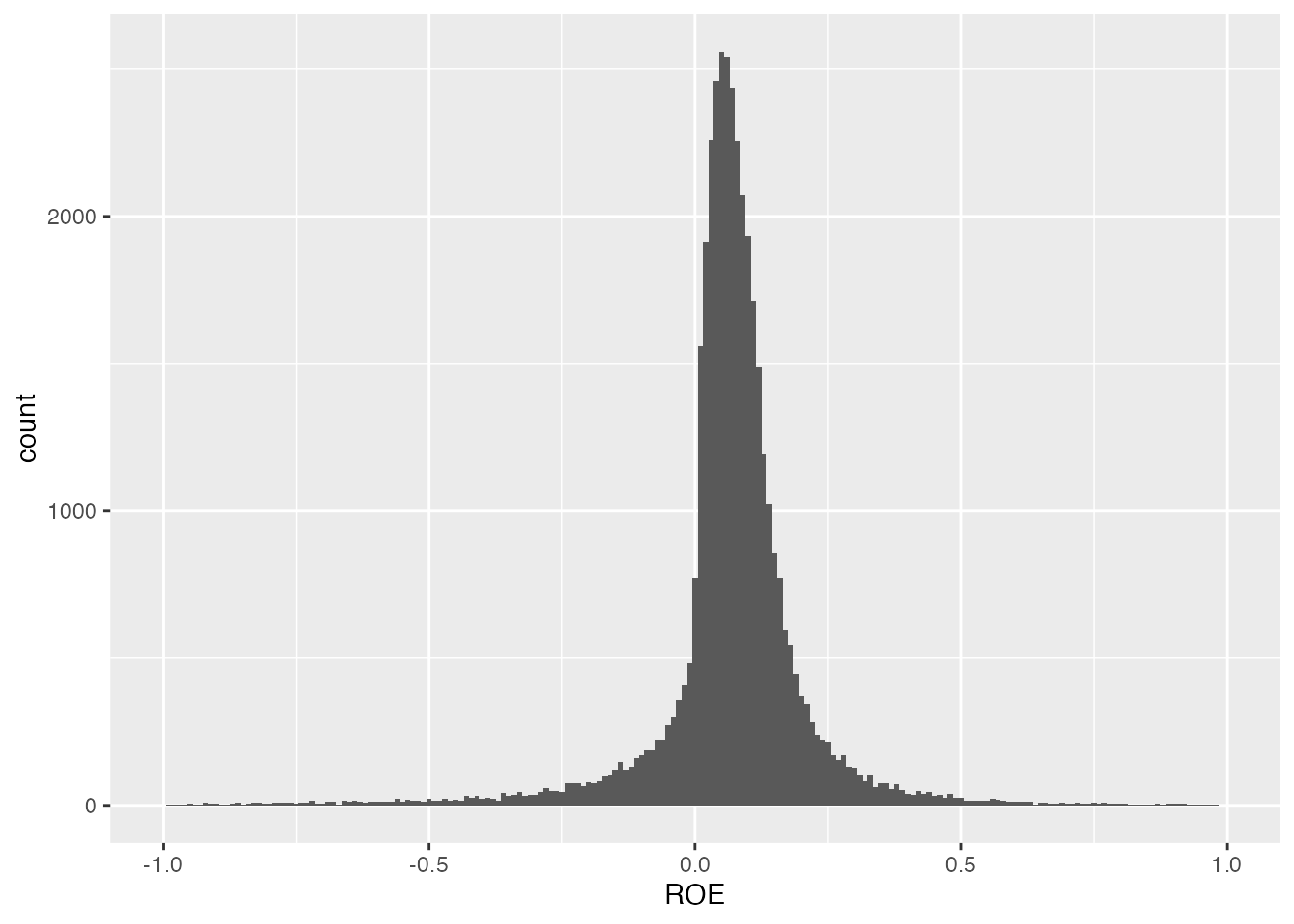
ヒストグラム
ヒストグラムは、横軸に連続変数の区間をとり、その区間ごとの度数を縦軸にとったグラフで、連続変数の分布を可視化するのに適しています。 分布の偏りや外れ値の有無を確認するのに有用で、重要な変数に対して必ず作図するものと言えます。
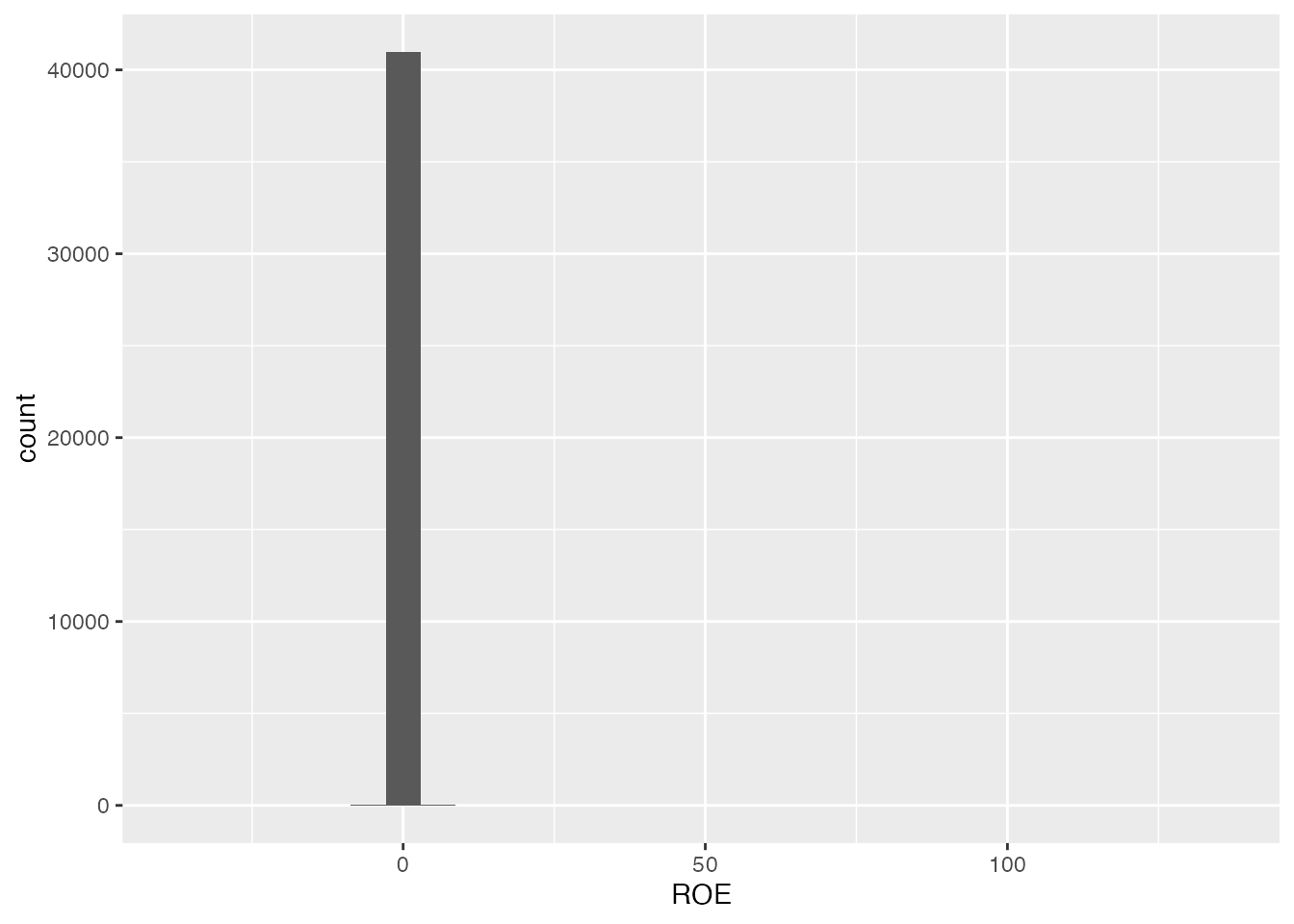
ヒストグラムを作成するには、geom_histogram() ggplot() data =とかmapping =は省略します。 ついでに、関数の入れ子構造を回避するため、aes()
`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
「stat_bin() bins = 30. Pick better value with binwidth.」というメッセージが出ました。 ヒストグラムを作成する際に区間幅やビンの数(棒の数)を指定しないと、ggplot2が自動的に30本の棒になるように区間幅を指定していますよ,というメッセージです。 無視しても問題ないです。 好みの区間幅や棒の数を指定したい場合は,binwidth = 0.1のように指定してみてください。
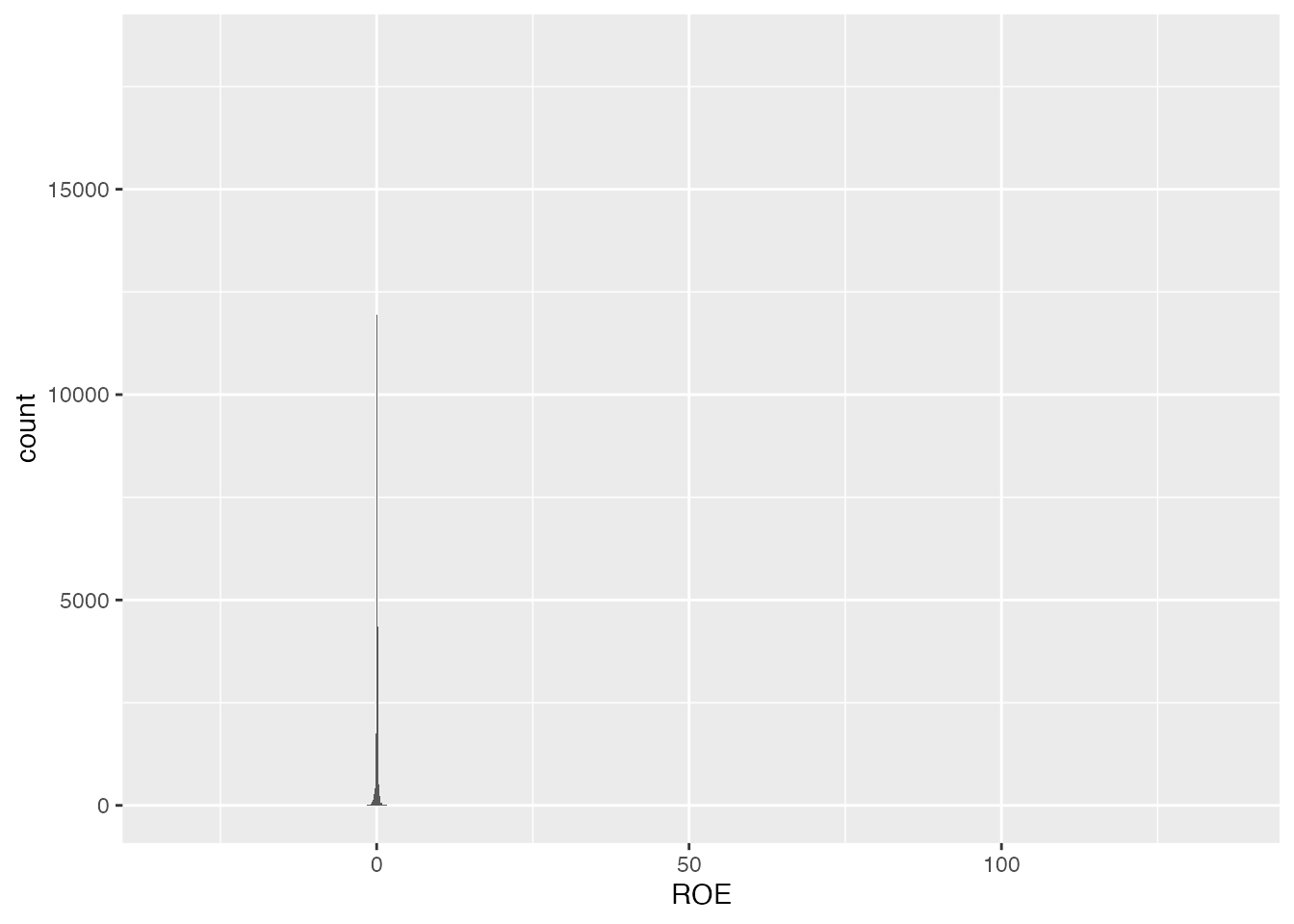
ヒストグラムがただの棒になっています。これは大部分のROEがゼロ付近の値を取っているけれど、異常値があるせいで、ROEの範囲が広くなってしまっているためです。 区間幅を0.1に狭めて、もう少し分布の形状が分かるようにしてみます。
ヒストグラムが細い棒になりました。
先ほど計算したROEの記述統計量でも、最小値は-32.167 、最大値は136.143 となっています。 当期純利益が株主資本の136倍というのは、異常な値ですね。 そこで、棒の周辺の様子を確認するために、x軸の範囲を[-1,1] に限定してみましょう。 ggplot() xlim() x軸の範囲を指定します。
Warning: Removed 319 rows containing non-finite outside the scale range
(`stat_bin()`).
Warning: Removed 2 rows containing missing values or values outside the scale range
(`geom_bar()`).
なにやらWarningが出ていますが、区間を区切ったことでグラフに入らなかったデータがあることを教えてくれているだけなので,無視します。
まともなヒストグラムが描けました。 分布の形や異常値を確認するためにも,分析する重要な変数に対してヒストグラムを作成するように心がけましょう。
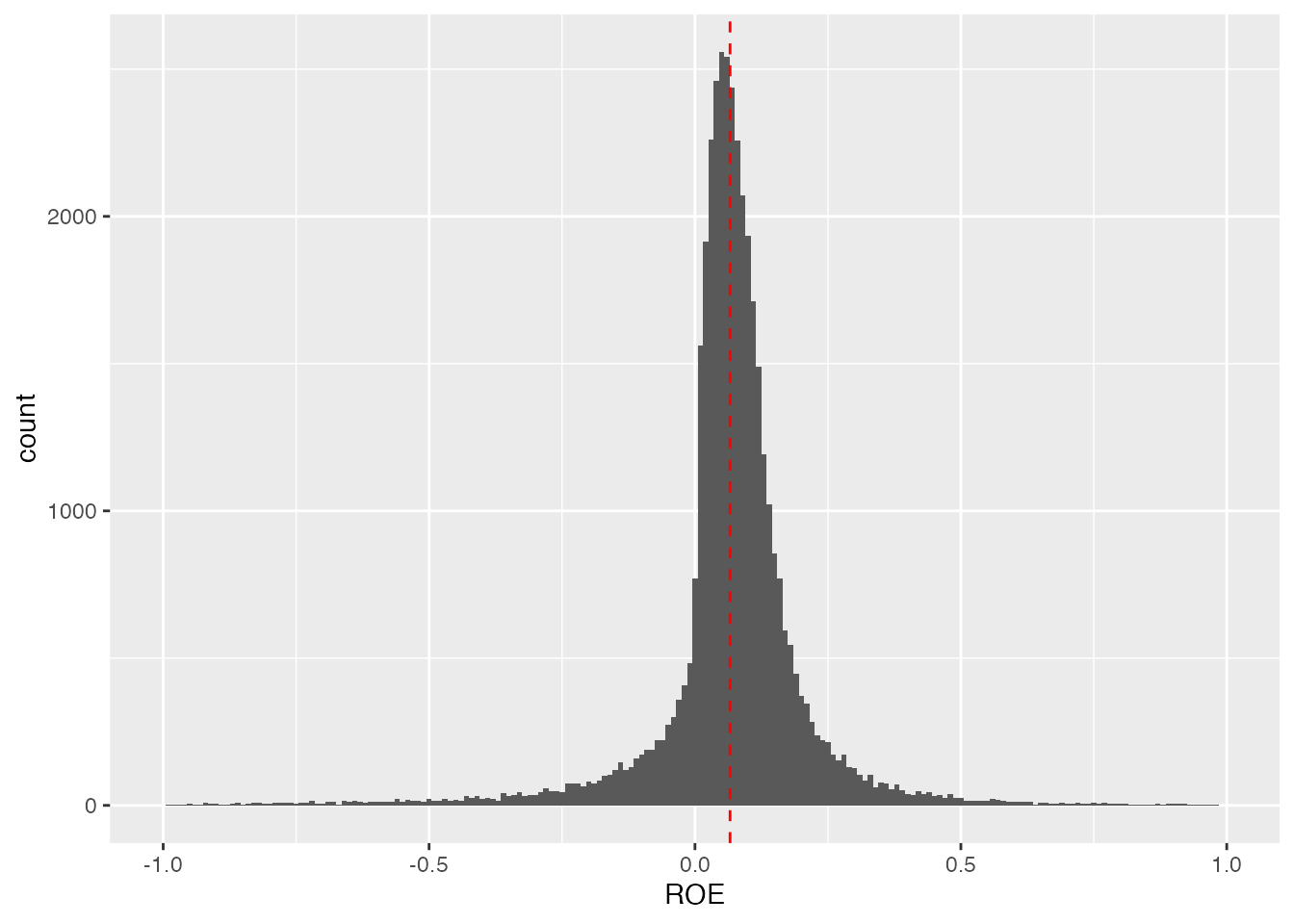
次にROEの平均値を計算し、ヒストグラムに書き込んでみましょう。
mean_ROE <- mean ( df $ ROE , na.rm = TRUE )
ROEの平均値は、0.0660036でした。 この値をヒストグラムに書き込むには、垂直線を引くgeom_vline()
Warning: Removed 319 rows containing non-finite outside the scale range
(`stat_bin()`).
Warning: Removed 2 rows containing missing values or values outside the scale range
(`geom_bar()`).
2変数の可視化
次に,2変数の可視化を行っていきましょう。 2変数の可視化では、横軸と縦軸にそれぞれ1つの変数をとるグラフを作成します。 また、横軸に割り当てられる変数が連続変数かカテゴリー変数かによって、作成するグラフが異なります。
横軸が連続・縦軸も連続の場合
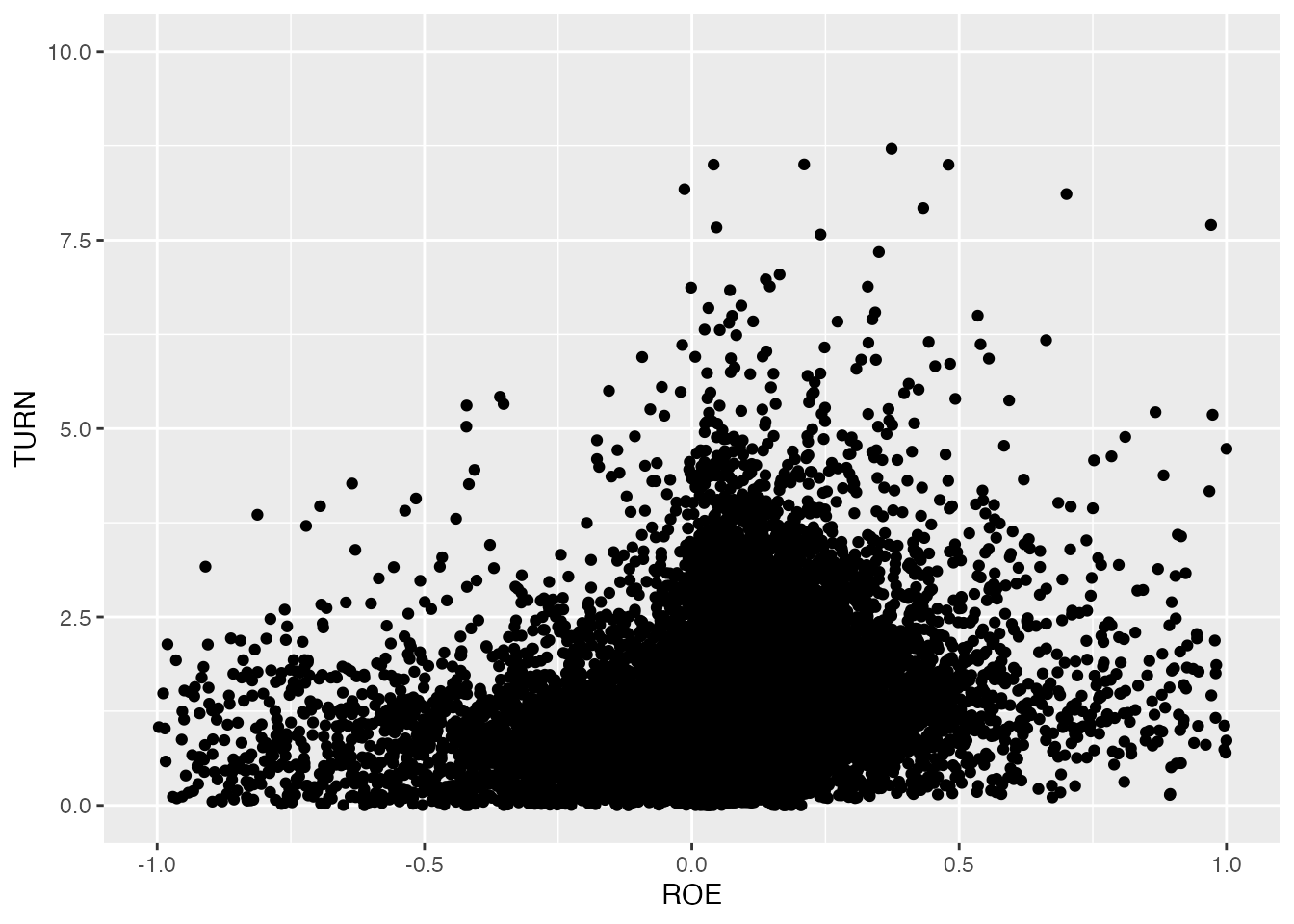
横軸と縦軸の両方が連続変数の場合、2つの変数の関係性を表すグラフとして散布図 (scatter plot)を作成します。 散布図は、横軸の値と対応する縦軸の値の組み合わせを点で表したグラフです。 散布図は、geom_point()
先ほど作成したdfのROEとTURNの関係を散布図で表してみましょう。 先と同様に、x軸とy軸の範囲をしておきます。
Warning: Removed 322 rows containing missing values or values outside the scale range
(`geom_point()`).
なんとなく、総資産回転率TURNが大きいほど、ROEが大きいように見えます。 このように、散布図を作成すると、2つの変数の関係を直観的に把握することができます。
横軸がカテゴリー変数・縦軸が連続変数の場合
横軸が順序のないカテゴリー変数で、縦軸が連続変数となるグラフとして
などがあり、横軸が順序のあるカテゴリー変数であれば、
が代表的です。 また,横軸にカテゴリー変数を指定する際に,そのカテゴリー変数の型が数値型でも文字列でも因子型でも,Rが適切に解釈してくれ,作図してくれますが,可能な限りカテゴリー変数は因子型にしておくほうが望ましいです。
それぞれ作成してみましょう。
棒グラフ
棒グラフはヒストグラムに似ていますが、棒グラフは離散変数やカテゴリー変数の分布を表し 、ヒストグラムは連続変数の分布を表している、という点で違いがあります。
棒グラフを作成するには、geom_bar() geom_bar()
stat = : 棒の高さの計算方法 identityを指定すると、データの値をそのまま棒の高さにします。
position = : 棒の位置の計算方法 dodgeを指定すると、カテゴリーごとに棒を並べます。
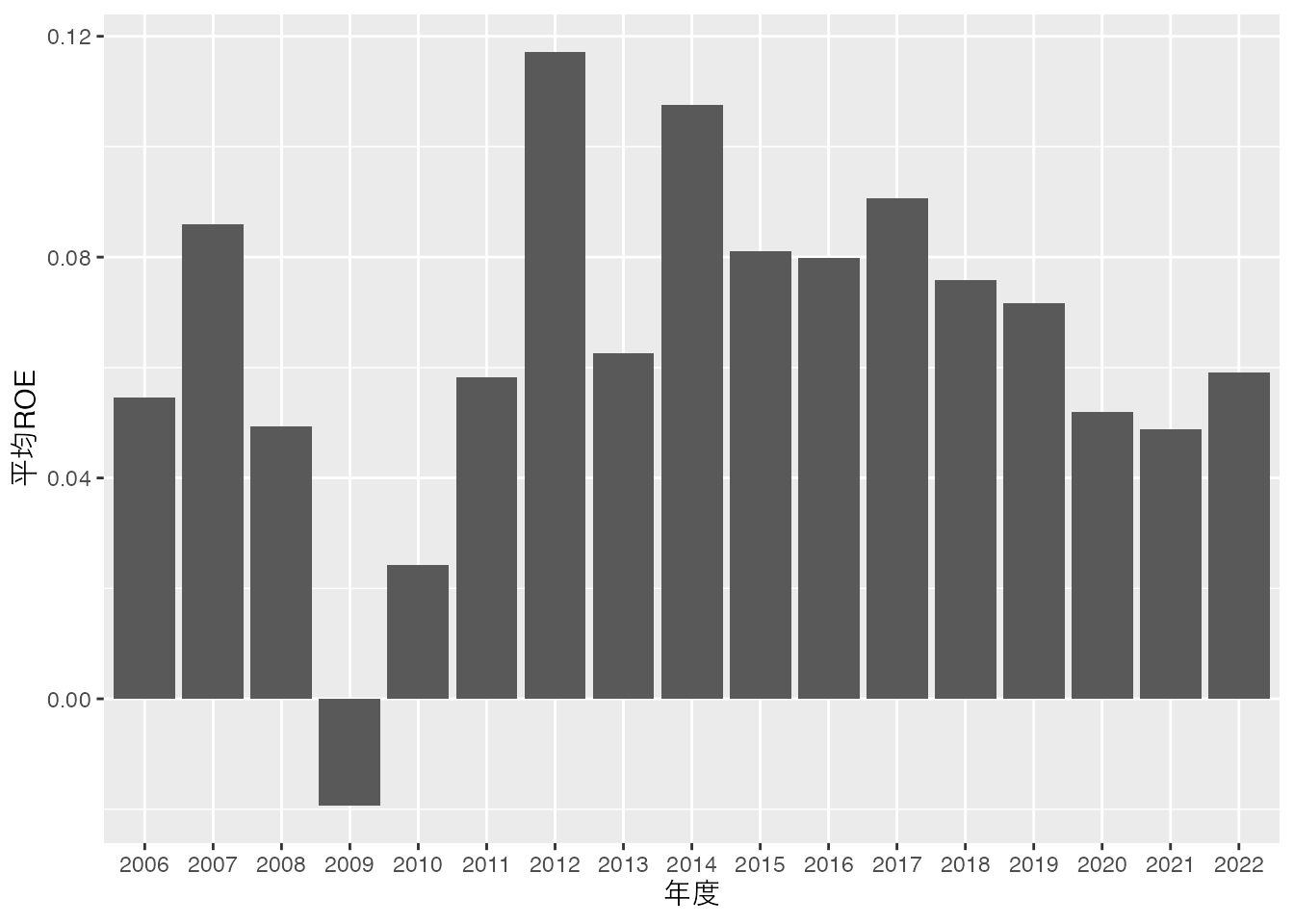
また、2変数のグラフとなるため、aes(x = 変数1, y = 変数2)と2つの変数を指定します。 ここでは年度ごとに集計したdf_yearを使って、年度ごとの平均ROEを棒グラフで表してみましょう。
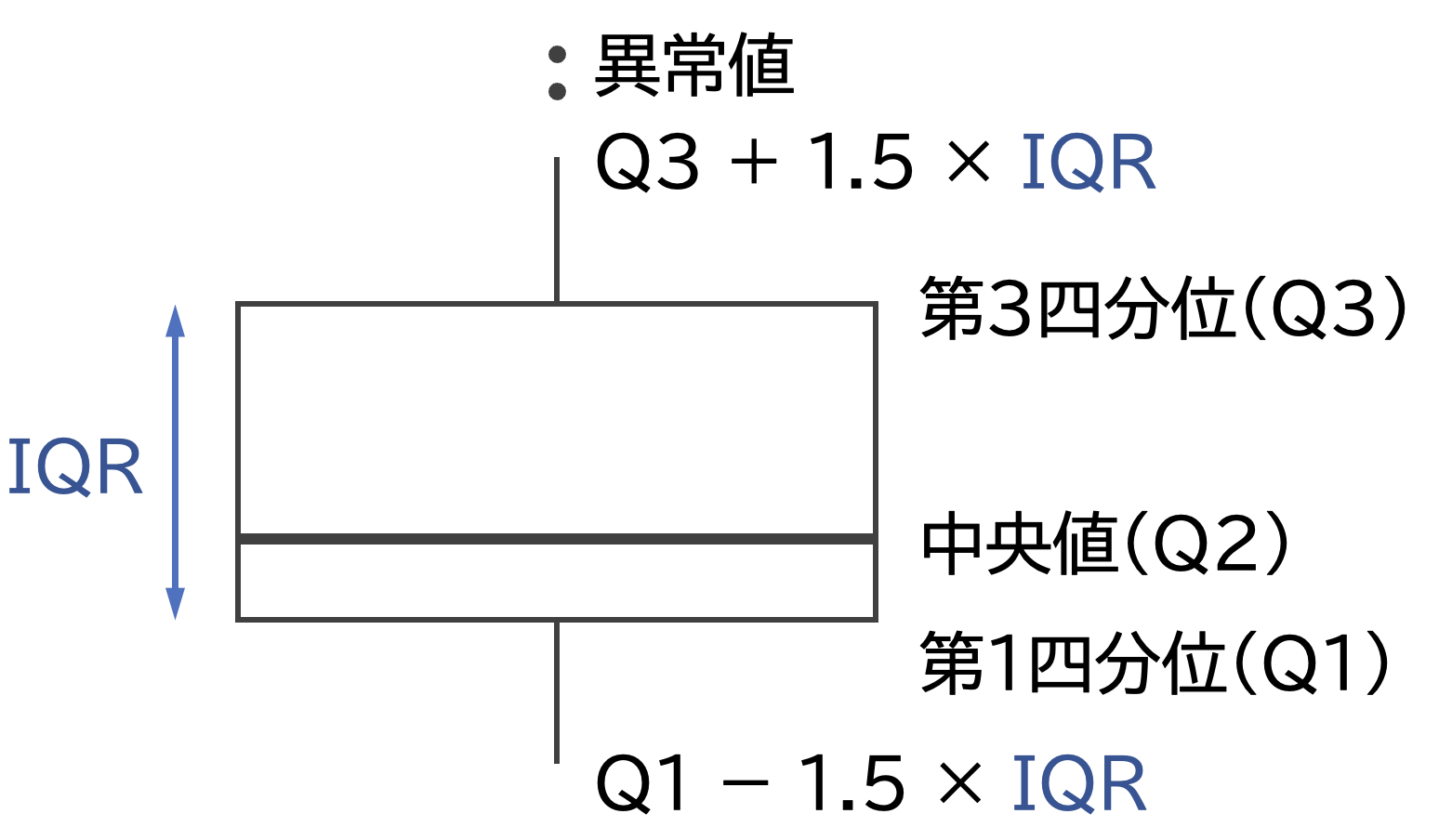
箱ひげ図
箱ひげ図(box plot)は、カテゴリーごとの連続変数の分布を表すグラフです。 棒と箱の図からなるグラフで、箱の部分から中央値(Q2),第1四分位点(Q1),第3四分位点(Q3)統計量,そしてヒゲの部分から正常値と設定される範囲が読み取れるグラフです。
年度ごとのROEの分布を箱ひげ図で表してみましょう。 横軸のカテゴリー変数ごとに作図するため,aes() x軸とy軸を設定するのと同時に,group =でカテゴリーを指示します。
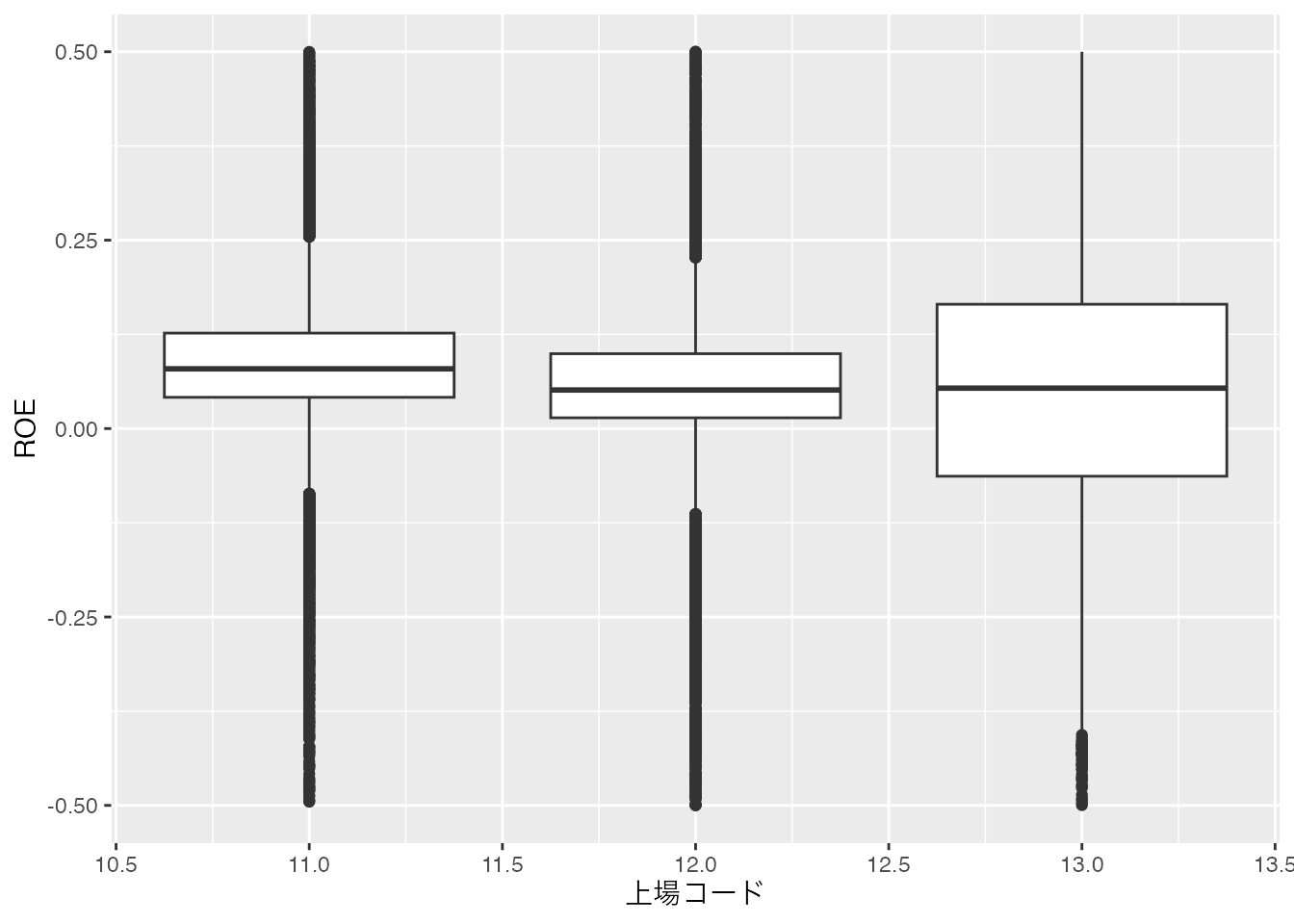
では集計前のdfを用いて,上場コードごとのROEの分布を表す箱ひげ図を作成します。 異常値のせいで箱ひげ図が潰れてしまうことが予想できるので,表示する幅をylim()
Warning: Removed 1168 rows containing non-finite outside the scale range
(`stat_boxplot()`).
この上場場ごとのROEの箱ひげ図から,東証プライム(東証1部)に属する企業は,ROEの中央値が他よりも高いが,東証スタンダードとグロースは中央値に差が無さそうに見える。しかし東証グロースはROEのばらつきが最も大きく,業績の格差が大きいことが分かる。
ヴァイオリンプロット
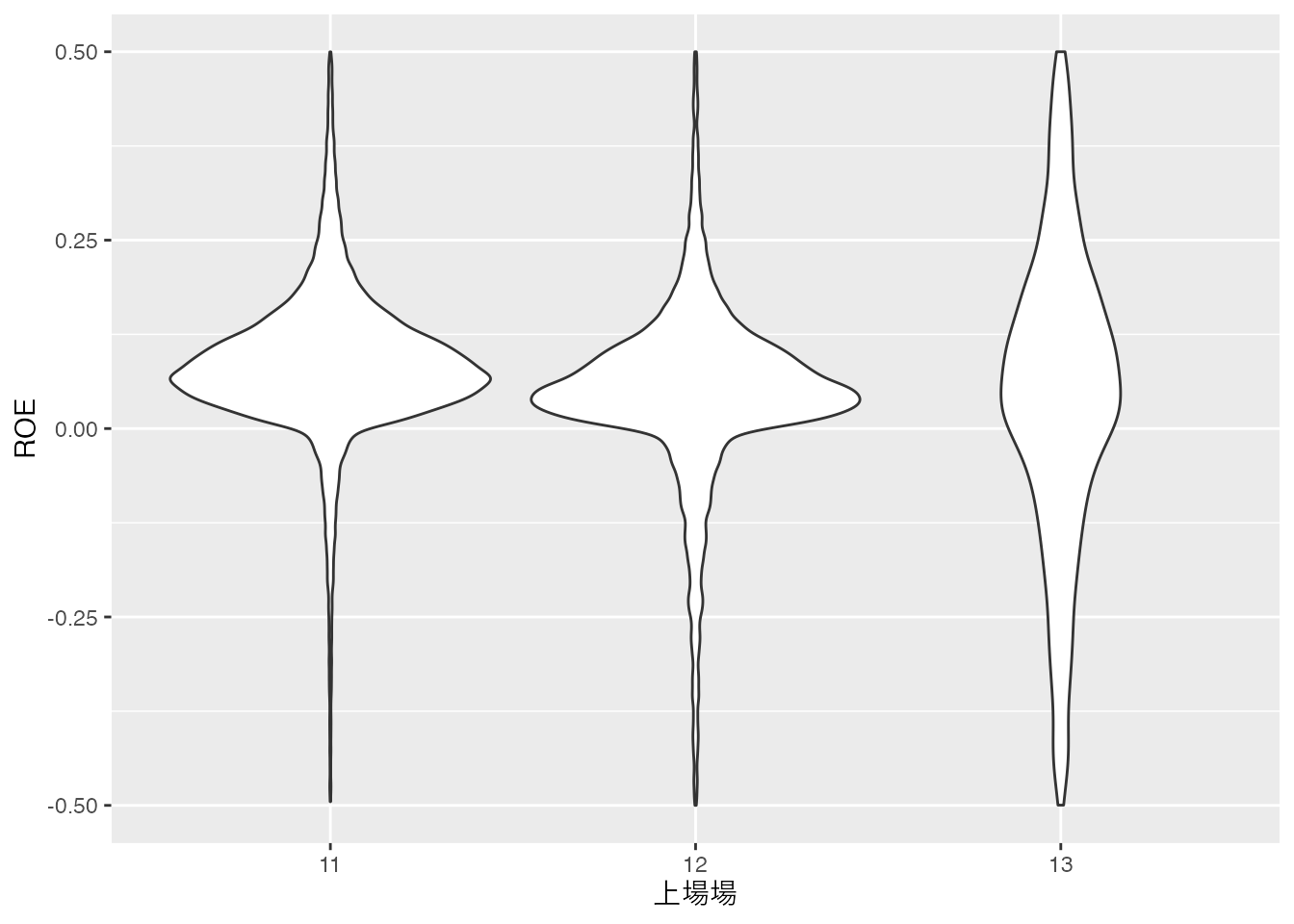
次に,バイオリンプロットを作成します。 バイオリン・プロットも箱ひげ図を同じようなグラフですが,分布の形を中央値などの代表値で表すのではなく,分布の形をそのまま表現することができます。 バイオリンプロットの作成にはgeom_violin()
Warning: Removed 1168 rows containing non-finite outside the scale range
(`stat_ydensity()`).
バイオリンプロットから,プライム・東証1部とスタンダード・東証2部の上場企業のROEは中央値に差があるものの,分布の形は似ていますが,グロース・マザーズの企業は,ROEの分布が大きく異なることがわかります。
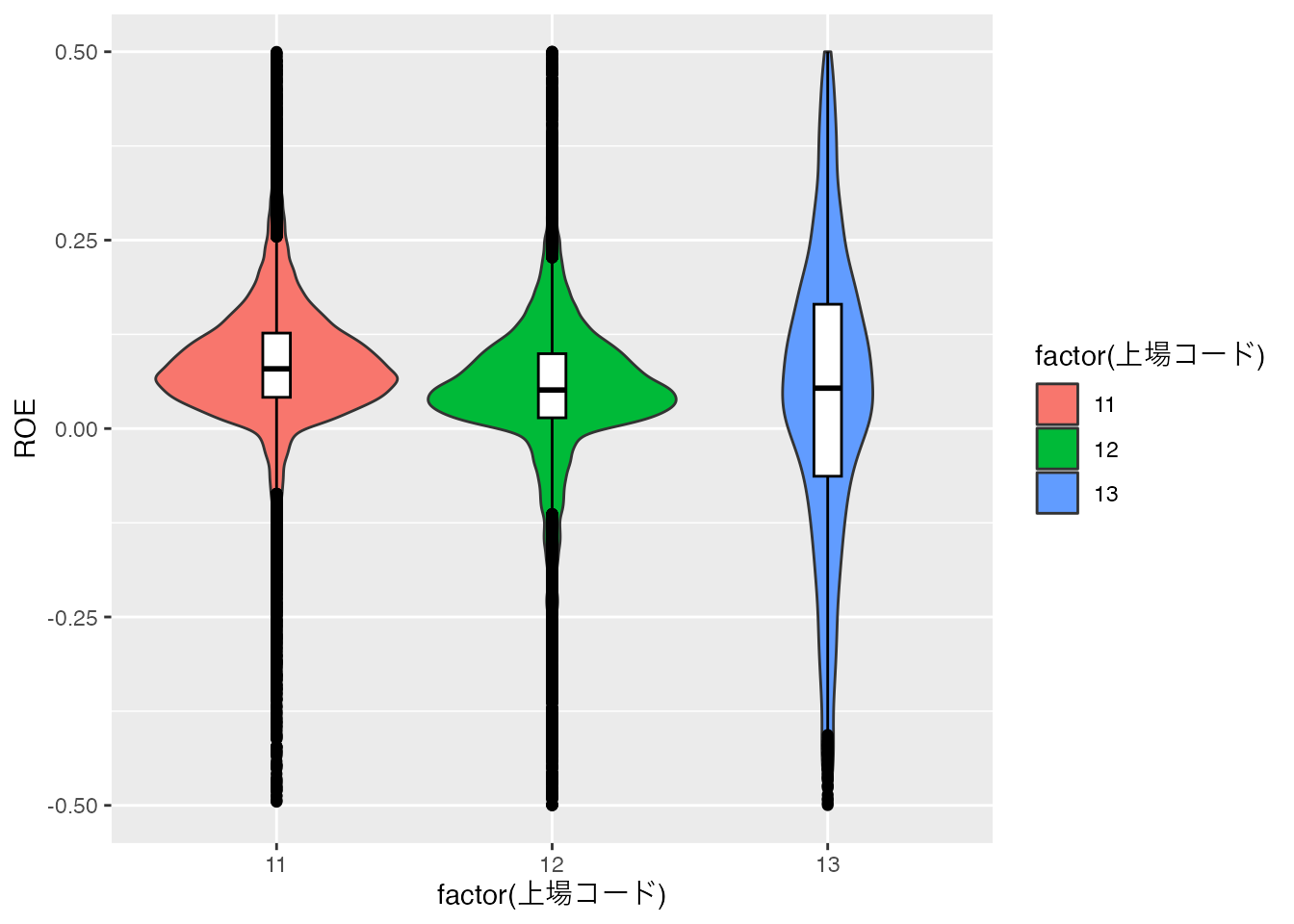
カスタマイズした箱ひげ図とバイオリンプロット
geom_violin() aes() fill =で色を指定します。 ついでに,geom_dotplot()
Warning: Removed 1168 rows containing non-finite outside the scale range
(`stat_ydensity()`).
Warning: Removed 1168 rows containing non-finite outside the scale range
(`stat_boxplot()`).
折れ線グラフ
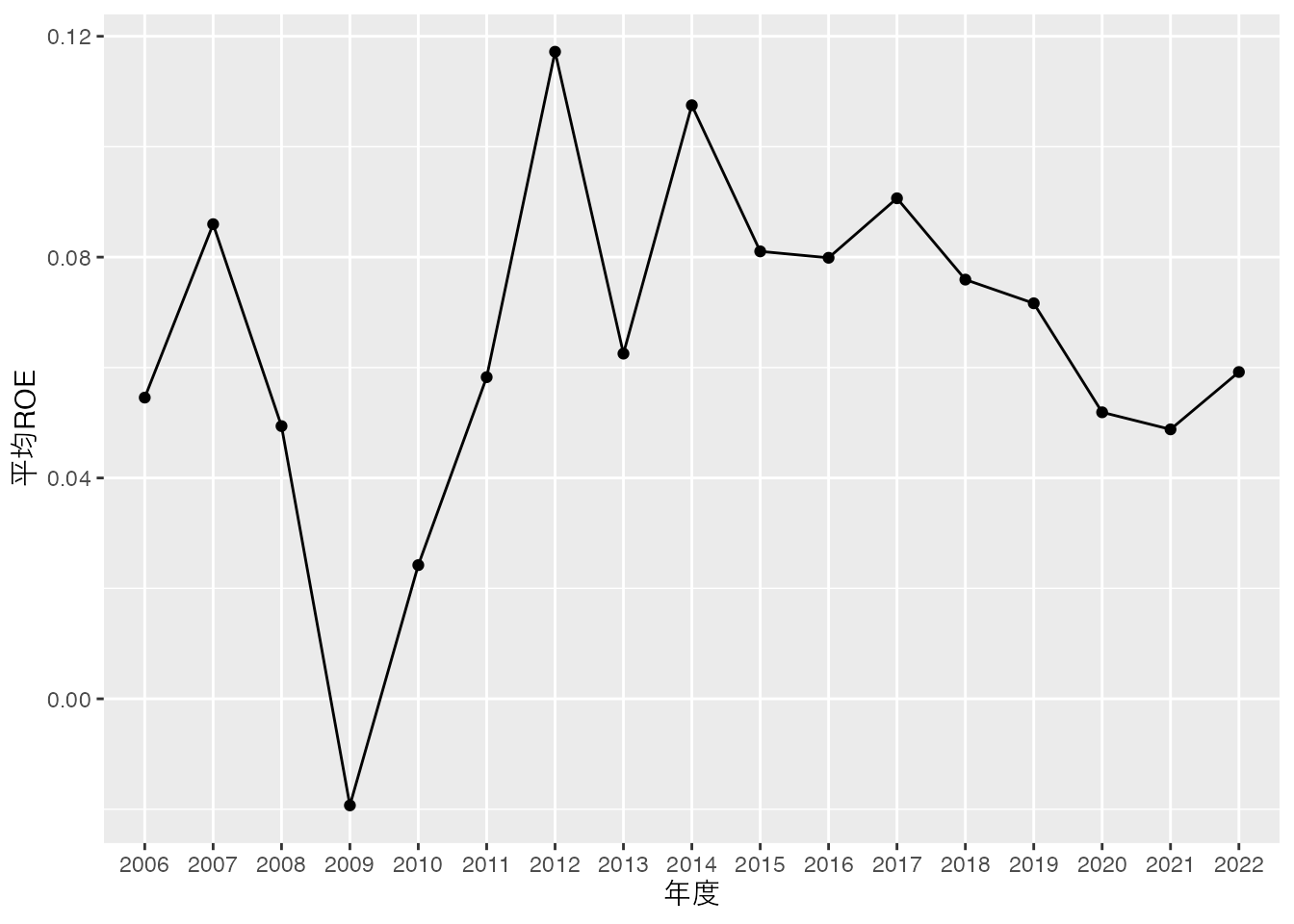
横軸が時間を表すカテゴリー変数 である場合,データの時系列的特性を表すために折れ線グラフを作成します。
折れ線グラフを作成するためにはgeom_line() df_yearを用いて,横軸が年度,縦軸が平均ROEとなる折れ線グラフを作成し,上場企業全体のROE平均が時間とともにどのように変化したのかを確認してみましょう。 ここで年度が文字列となっていますが,本来は順序に意味のあるカテゴリー変数 ですので,factor()
df_year <- df_year |> mutate (
年度 = factor ( # 因子型に変換
年度 , # 因子型にする変数
levels = c ( 1999 : 2022 ) , # カテゴリーの種類
ordered = TRUE # 順序があることを明示
)
)
`geom_line()`: Each group consists of only one observation.
ℹ Do you need to adjust the group aesthetic?
「geom_line()
これは,年度が因子型であり,ggplot2が自動的に年度ごとにグループ分けをしてくれないために出るメッセージです。 aes() group = 1として,データ全体が1つのグループであることを明示する必要があります。 横軸がファクター型であるときは,group = 1をつける,というおまじないを覚えておきましょう。
上のようにすべての要素を+でつなぐよりも,レイヤーごとにオブジェクトに代入していくほうが,コードが読みやすくなります。 以下の例では,グラフの基本要素をgというオブジェクトに代入しておき,g <- g +でどんどんレイヤーを追加していきます。
折れ線グラフだけより,散布図も同時に表示するほうがグラフが読みやすくなり,オススメです。
図の保存
最後に,作成した図を保存するには,ggsave() ggsave()
filename = : 保存するファイル名
plot = : 保存する図
width = : 図の幅
height = : 図の高さ
dpi = : 解像度
日本語を含まないグラフであったり,Windowsならこれでうまくいくのですが,Macで日本語を含むggplotのグラフを保存するには一手間必要です。
Macの場合
Macの場合,ggsave() quartz()
quartz()
filename = : 保存するファイル名
width = : 図の幅
height = : 図の高さ
pointsize = : フォントサイズ
dpi = : 解像度
family = : フォントファミリー
type = : ファイルタイプ
antialias = : アンチエイリアス
最低限の設定だと,
quartz("ファイル名.pdf", type = "pdf")とか,quartz("ファイル名.png", type = "png")と,保存するファイル名とファイルタイプを指定しておきましょう。 その上で,
quartz()
print()
dev.off()
という手順を踏むと,作業ディレクトリにグラフが保存されます。
これで作業ディレクトリにviolin_plot.pdfが保存されました。