株価データの特徴
株式データの集め方
株式データの使い方
株式市場の仕組み
金融商品取引市場とは,有価証券の売買や市場デリバティブ取引が行われる市場をいい(金商法2条14項),そこで有価証券が金融商品取引所である東京証券取引所などが開設する市場での取引対象になることを,有価証券の上場 とよんでいます。 発行する株式が上場されている場合,その株式会社を上場会社(163条1項),一般には上場企業とよびます。
株式を新たに上場しようとする会社は金融証券取引所の審査を受け,一定の基準に適合しており,また企業内容の開示を適切に行うことができる状況にあるのかどうか,などが確認され,上場が適当と認められた株式が上場を許されるのです。
株価データ
金融商品取引所は,投資家が株式を売買する場を設けており,またそこで生み出される取引データなどを収集しています。
株式取引やファイナンス・金融論文で用いられる用語について,笠原・村宮 (2022)に基づいて示しておきます。
成行注文 値段を指定せず,最良気配値で取引を希望すること
指値注文 特定の値段を指定して取引を希望すること
板 その時点で有効な指し値注文を売りと買いで分けて価格ごとにまとめた一覧表のこと
板寄せ方式 取引開始時に板情報(それまでに提出された売りと買いの注文)に基づいて取引価格を決定する方法のこと
ザラ場寄せ方式 取引時間(ザラ場)中に新規注文と板情報に基づいて取引価格を決定する方法のこと
歩み値 取引時間中の売買履歴(約定価格や出来高)に関する時系列データのこと
証拠金 信用取引を行う際に資金の貸し手に差し入れる担保のこと
値洗い 保有するポートフォリオ(ポジション)の価値を時価で再評価すること
追証 値洗いの結果,追加の証拠金を求められること
逆日歩 信用売りが殺到し株不足となった銘柄でショート・セラーが追加で支払う費用のこと
踏み上げ 株価上昇で損失を抱えたショート・セラー( 2.2.3 節を参照)のロスカットが一段の株高を招くこと
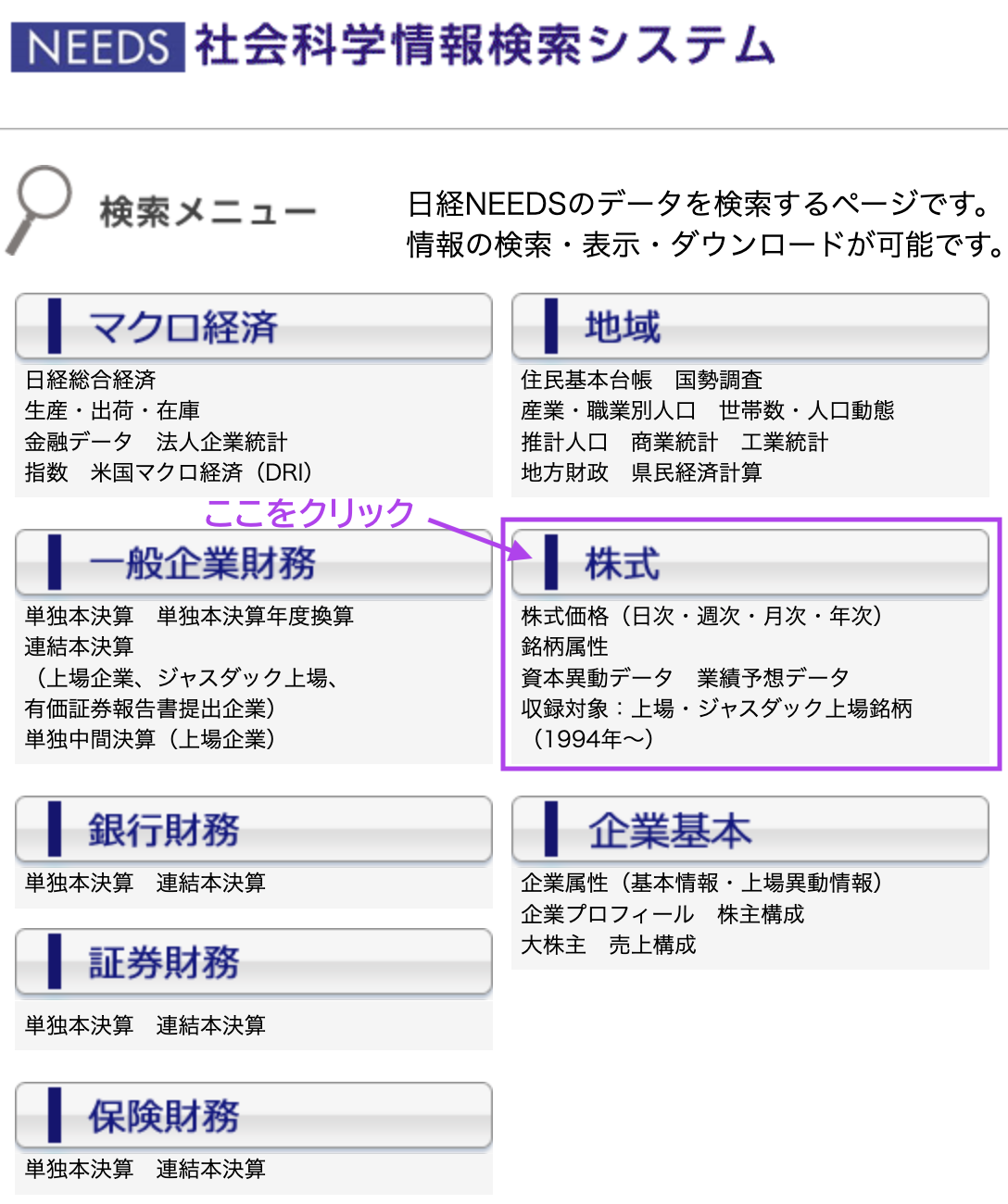
日経NEEDSはそのデータを使いやすくデータベース化してくれているので,そこから株式データを取得します。 立命館大学の図書館のウェブサイト から,日経NEEDS社会科学情報検索システムのトップページに移動し,「株式 」を選択します。
日経NEEDS社会科学情報検索システムの「株式」のトップページは,先の「一般企業財務」と同じように、上下2つのパートで構成されています。
上のパートは、株式の銘柄や株式の項目を選択する場所です。
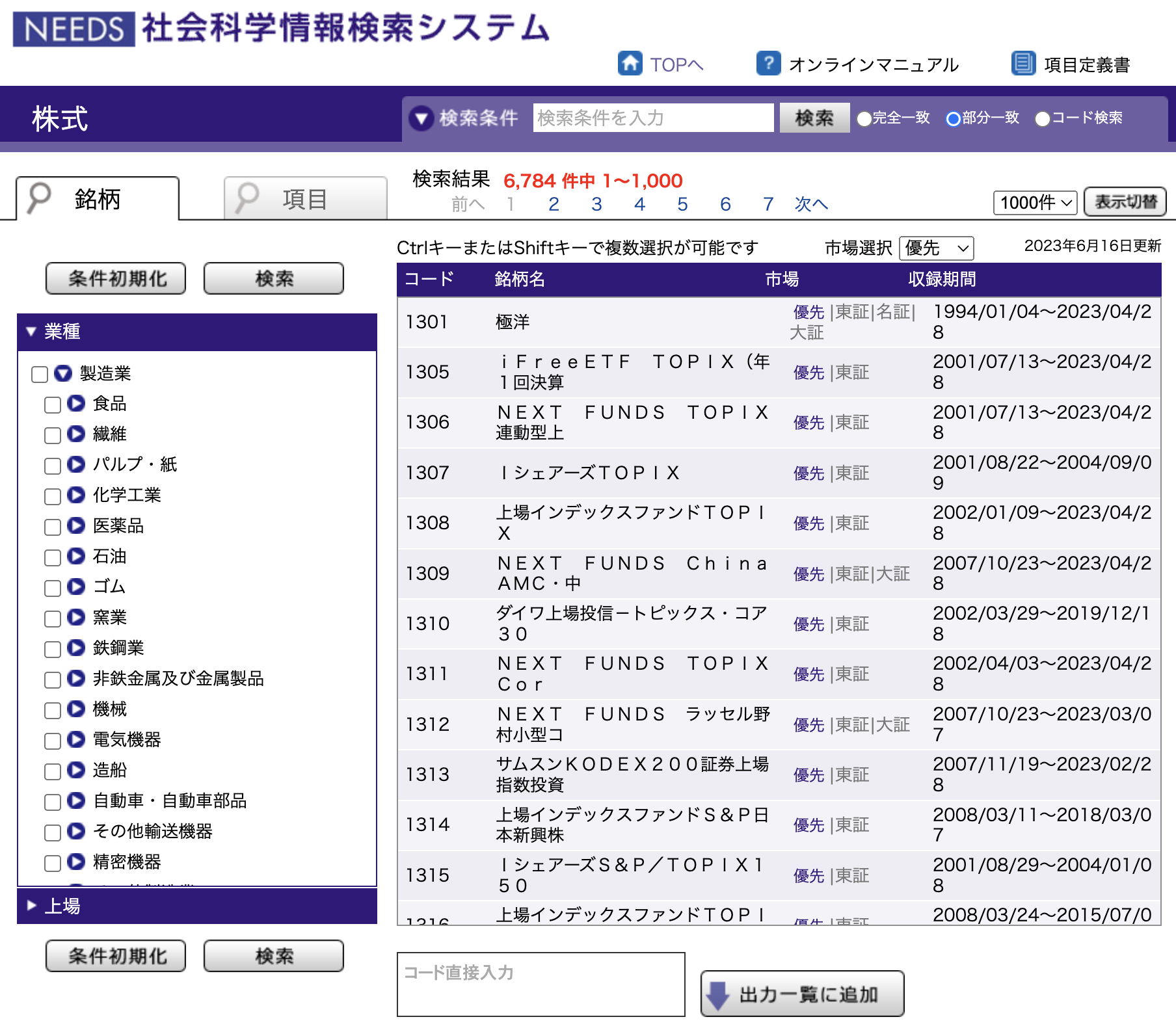
銘柄検索画面にコードを直接入力することで,データを入手することもできます。 新株・優先株のデータは”S+4桁株式コード”もしくは”N+7桁日経会社コード”の後に”株式種別コード(1桁)”をつけてコード検索が可能です。 株式種別コードは下記の通りです。 1:新株式,2:第二新株式,3:第三新株式,4:第四新株式,5:優先株式,6:優先新株式,7:後配株式,8:後配新株式,9:新株引受権証書
「銘柄」タブは財務データと同じなので銘柄を選択するものですが,財務データのときとほぼ同じなので,ここでは「項目」タブを見ていきましょう。
項目選択
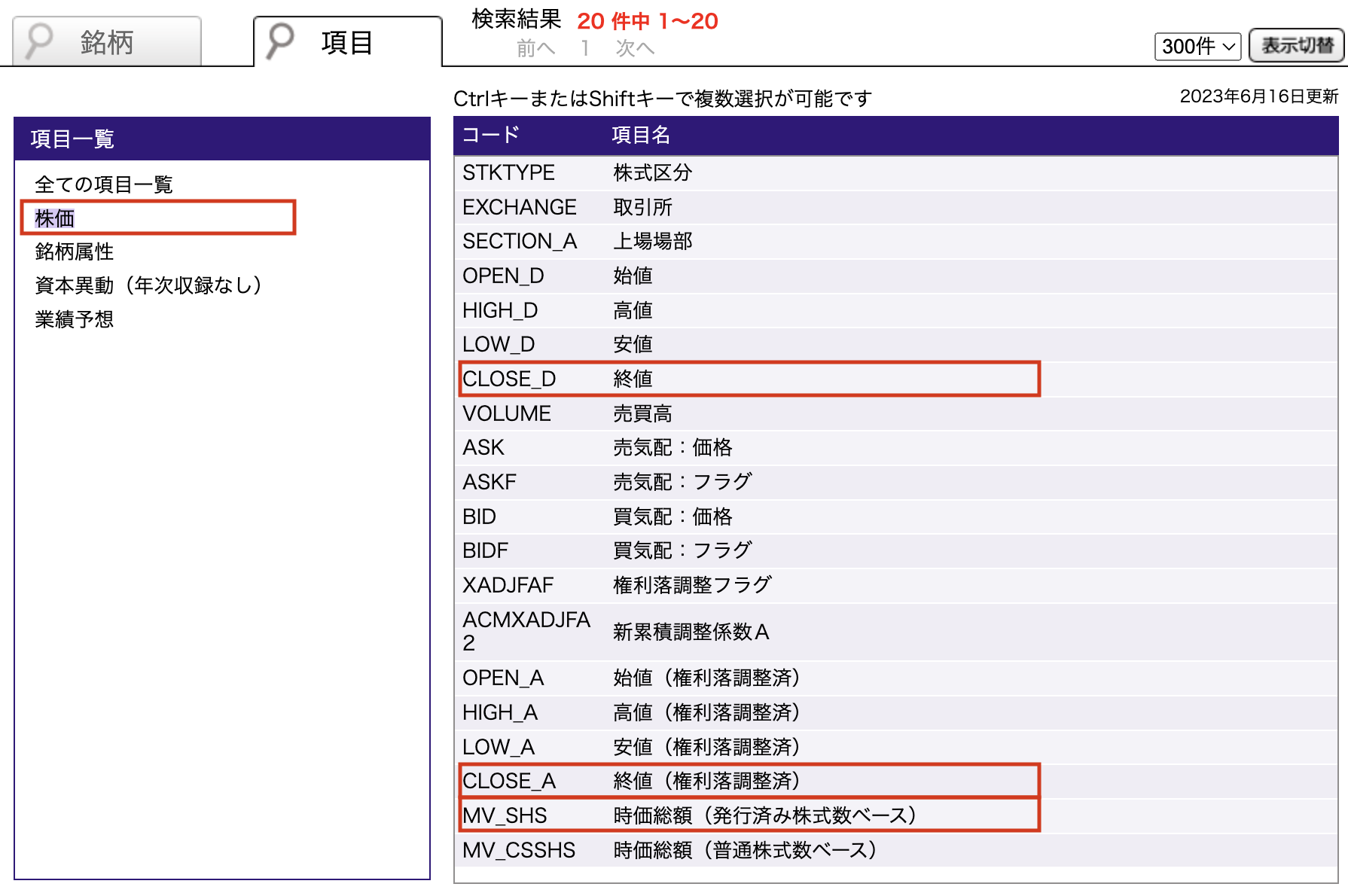
「項目一覧」から入手したいデータが含まれている項目を選択します。 たとえば、「株価」を選択すると、右側に「株価」の区分から入手可能な項目のリストが表示されます。 よく利用される項目として,「株価」項目から
STKTYPE 株式区分
EXCHANGE 取引所
SECTION_A 上場場部
CLOSE_D 終値
CLOSE_A 終値(権利落ち調整済)
MV_SHS 時価総額(発行済株式数ベース)
「銘柄属性」から
SECCODE 銘柄コード
ISSUREK 幹事銘柄名
NKINDYCD1 日経業種区分
があります。
調整済み株価のデータを表示するために「調整係数」を使用しています。 市場ごとに以下の式にて調整済み株価のデータを算出しています。
権利落ち調整済み株価(理論値) =\frac{(V_i \times A_i)}{A_j}
ここで,
V_i : i 時点の株価 A_i : i 時点の新累積調整係数A A_j : 直近の新累積調整係数A
とりあえず,以下の図のように終値,終値(権利落調整済),時価総額(発行済み株式数ベース)の3つのデータを集めてみましょう。
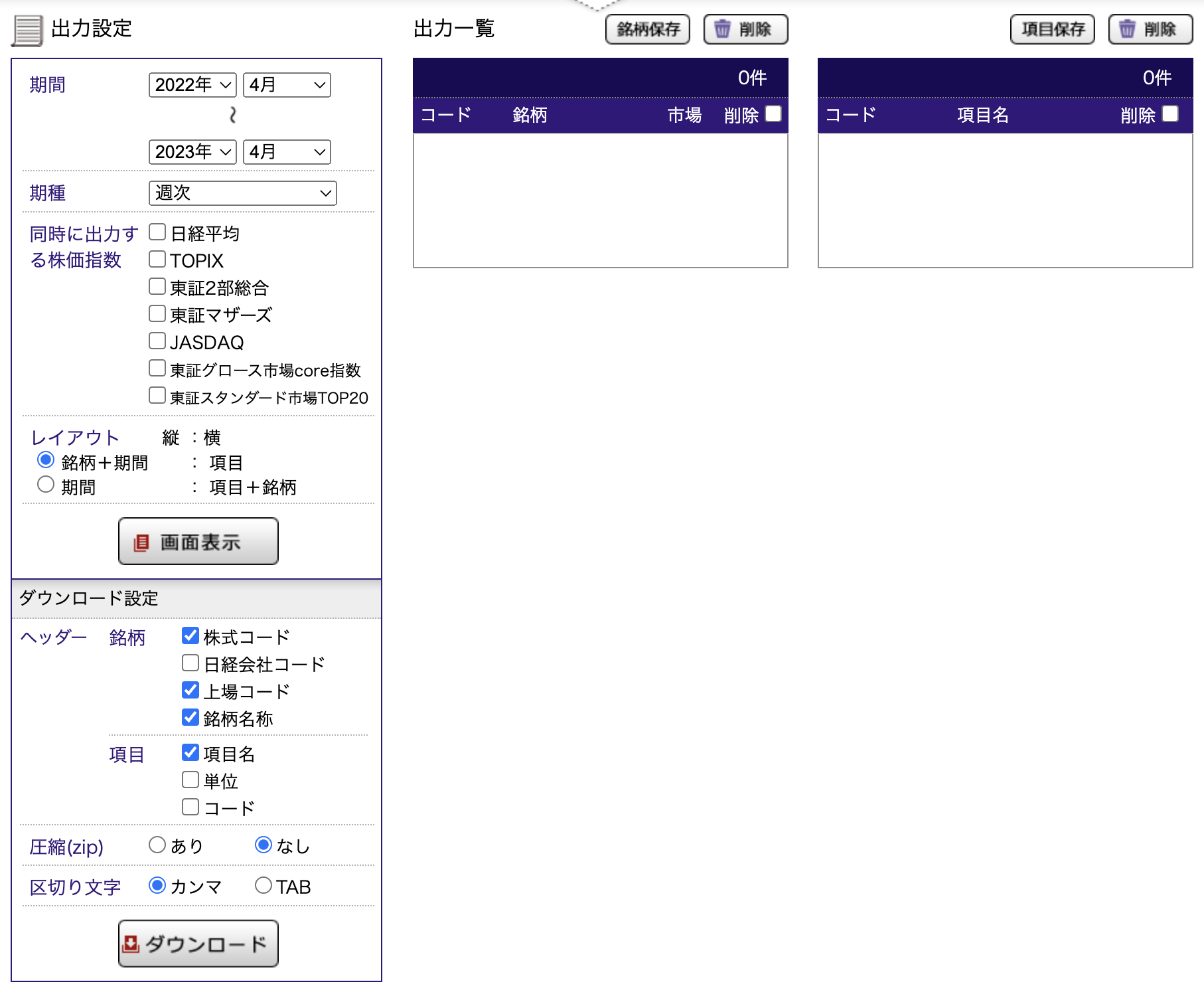
銘柄と項目を選択し,それぞれ「出力一覧に追加」をクリックして,画面下部に選択した銘柄と項目を登録すれば,次のような表示になっているでしょう。
出力設定
上のパートで銘柄と項目を選択したら、次の下パートの「出力設定」で、データの入手期間や、データの種類を選択します。 左側の項目で、サンプルの期間や同時に出力する株式指数、レイアウトを選択します。
期間
ここでは、データの入手期間を選択します。 開始期間と終了期間を指定することができます。
期種
次に,期種を選択します。 期種には,
の4つがあります。 分析でよく用いるのは,日次か月次です。 近年は大量のデータを処理することが容易になったため,日次データを用いることがほとんどです。
たとえば,東京証券取引所の売買立会は,前場と後場に分かれ,前場は午前9時から11時30分まで,午後立会は12時30分から15時までとなっています。 土日祝日,12月31日〜1月3日は休業日となります。 よって日次の終値は1銘柄1年間で245日(2022年度)になります。 これを東証上場全社で10年間分の日次終値を取得しようとすると,非常に大規模なデータとなります。必要な期間,銘柄数をよく考えてデータを取得するようにしましょう。
同時に出力する株価指数
個別銘柄のデータとともに,株価指数を入手することができます。 ここではよく利用される
の2つを選択しておきましょう。
レイアウト
レイアウトでは、データの並び順を指定します。 特に重要ではないので、そのままで大丈夫です。
ダウンロード設定
ダウンロード設定も特に変更する必要はありません。
銘柄と項目の保存
財務データと同様に,やはり株式データについても分析の再現性を確保するため,「銘柄保存」と「項目保存」のボタンをクリックし,取得する銘柄と項目のリストを残しておきましょう。
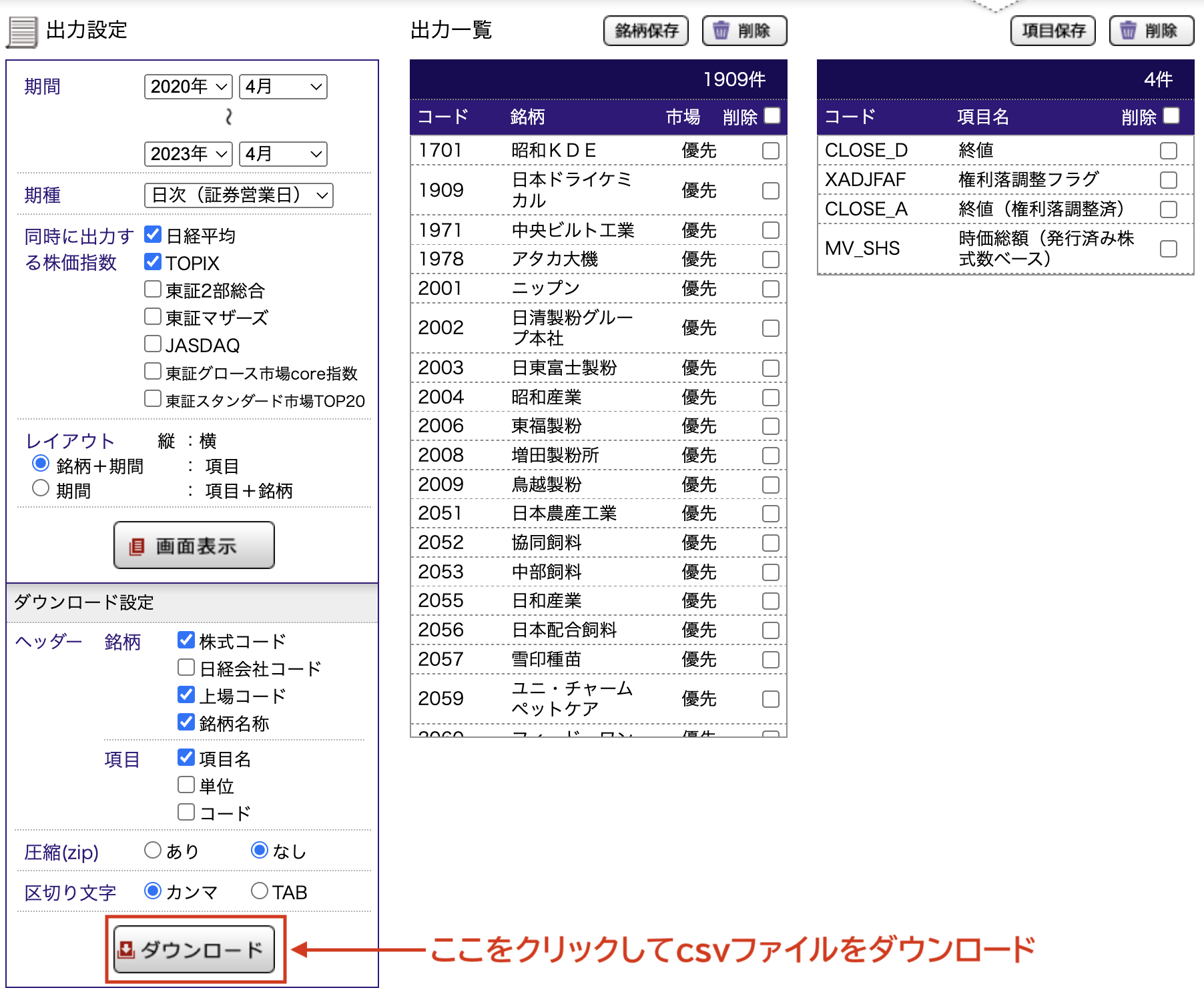
データの入手
今までの作業で、銘柄と項目の選択が終わり、データの入手期間や期種の選択が終わったら、あとはデータをcsvファイルとしてダウンロードするだけです。
最後に、大事なことなのでもう一度いいます。 ダウンロードしたcsvファイルをMS Excelで開かないようにしよう。
実践
では,以下の条件に合致する企業が発行している株式の終値と時価総額を取得してみましょう。
製造業に属する銘柄
東京証券取引所のプライム,スタンダード,グロースに上場している銘柄
その結果,1193銘柄が選択されました(2024年3月11日時点)。 「項目」として,
終値
終値(権利落ち調整済)
時価総額(発行済み株式数ベース)
の3項目を選びましょう。
出力設定では,
2022年4月から2023年3月
日経平均とTOPIX
を選択します。
準備ができたのでCSVファイルをダウンロードしてみましょう。 その結果,292,286件のデータとなりました。 では,このデータを確認してみましょう。
Warning: パッケージ 'stringr' はバージョン 4.2.3 の R の下で造られました
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.3 ✔ readr 2.1.4
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.4.4 ✔ tibble 3.2.1
✔ lubridate 1.9.2 ✔ tidyr 1.3.0
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Rows: 292285 Columns: 9
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (2): 上場コード, 銘柄名称
dbl (6): 日経平均, TOPIX, 株式コード, 終値, 終値(権利落調整済), 時価総額(発行済み株式数ベース)...
date (1): 期間
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Rows: 292,285
Columns: 9
$ 期間 <date> 2022-04-01, 2022-04-04, 2022-04-05…
$ 日経平均 <dbl> 27665.98, 27736.47, 27787.98, 27350…
$ TOPIX <dbl> 1944.27, 1953.63, 1949.12, 1922.91,…
$ 株式コード <dbl> 1909, 1909, 1909, 1909, 1909, 1909,…
$ 上場コード <chr> "011", "012", "012", "012", "012", …
$ 銘柄名称 <chr> "日本ドライケミカル", "日本ドライケ…
$ 終値 <dbl> 1775, 1767, 1811, 1749, 1719, 1741,…
$ `終値(権利落調整済)` <dbl> 1775, 1767, 1811, 1749, 1719, 1741,…
$ `時価総額(発行済み株式数ベース)` <dbl> 12747716300, 12690261804, 130062615…
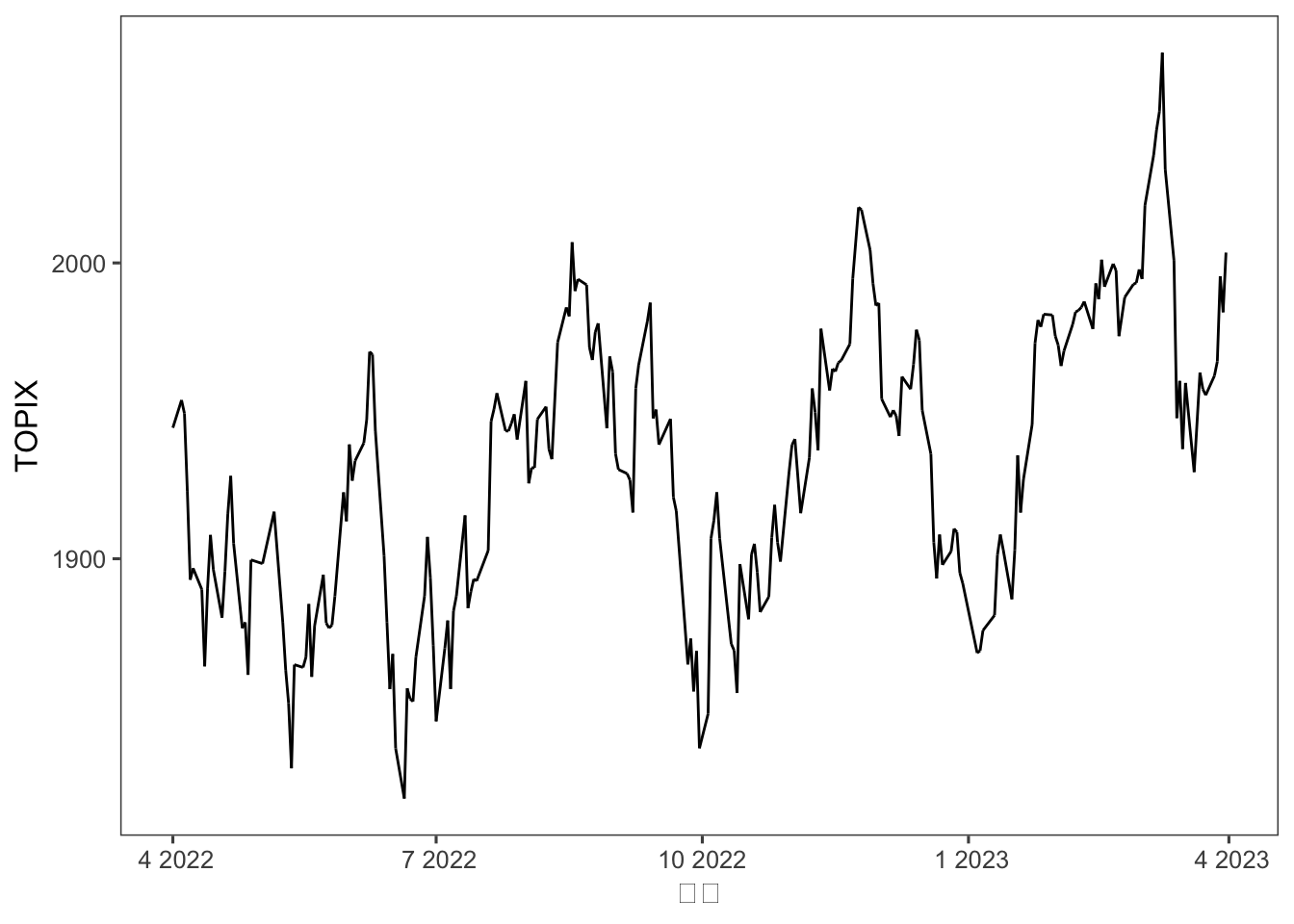
ではTOPIXを折れ線グラフで表してみましょう。
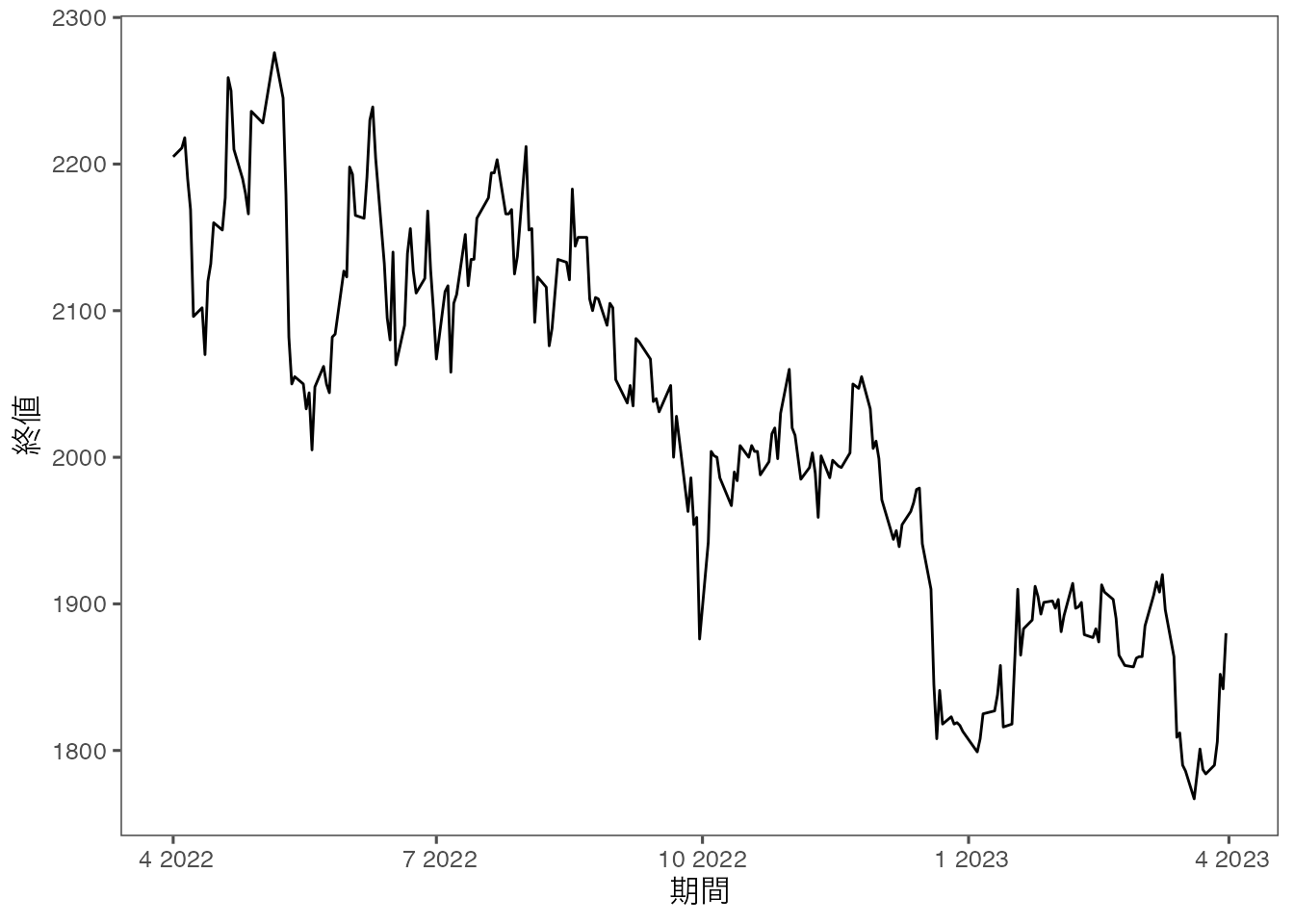
トヨタ自動車の株価を折れ線グラフで表してみましょう。
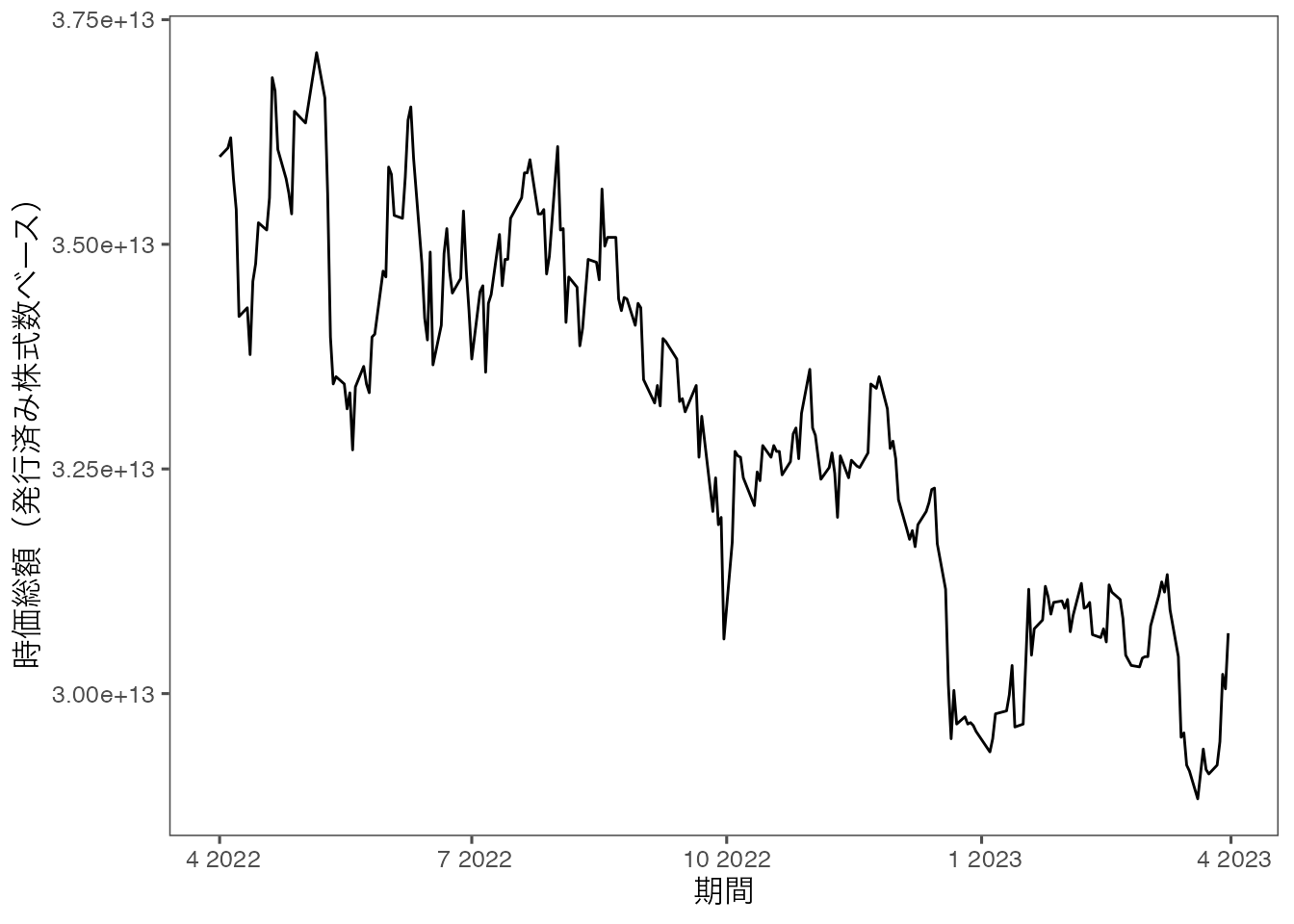
トヨタ自動車の時価総額を折れ線グラフで表してみましょう。