library(tidyr)8 整然データ
8.1 整然データとは
整然データセットはみんな似ているが,汚いデータセットはみんな独特で散らかっている。 — Hadley Wickham
R神Hadley Wickham氏は,データの型を理解することを,データ分析の第一歩とし,その一貫として整然データ(tidy data)という考え方を提唱しています。 整然データとは,次のようなルールに従って構築されたデータのことです(Wickham, 2014), 参考https://id.fnshr.info/2017/01/09/tidy-data-intro/。
重要
- 各観測値(observation)は行(row)であり、各行は1つの観測値である。
- 各変数(variable)は列(column)であり、各列は1つの変数である。
- 各値(value)はセル(cell)であり、1セルは1つの値である。

整然データのルールを満たすデータは,データの整理や可視化が容易になります。 そして整然データを扱うために非常に強力なツールを提供してくれるのが,tidyverseパッケージ群です。 以下では,tidyverseパッケージ群の中でも,データの整理に特化したtidyrパッケージを使って,整然データを作成する方法を学びます。
8.1.1 long形式とwide形式
人間には読みやすいけれどパソコンは読みにくい,というデータの形式があります。例えば下の表を見てみましょう。
| 地点 | 2022 | 2023 |
|---|---|---|
| トヨタ自動車 | 31379507 | 37154298 |
| 日産自動車 | 8424585 | 10596695 |
| 本田技研工業 | 14552696 | 16907725 |
このような形のデータをワイド形式(wide)といいます。 この表は,人間にとっては分かりやすいですが,実はコンピュータにとっては,分かりにくいものです。 またこのデータは、列が変数になっていないので整然データではありません。
コンピュータが理解しやすいデータとして表すなら,次のような表になります。
| 企業名 | 年度 | 売上高 |
|---|---|---|
| トヨタ自動車 | 2022 | 31379507 |
| トヨタ自動車 | 2023 | 37154298 |
| 日産自動車 | 2022 | 8424585 |
| 日産自動車 | 2023 | 10596695 |
| 本田技研工業 | 2022 | 14552696 |
| 本田技研工業 | 2023 | 16907725 |
このような形式のデータをロング型(long)といいます。
上の表は,行が、トヨタの2022年度の売上高、といったように1つの行が1つの観測を表しています(ルール1)。 企業名、年度、売上高の3列から構成されていて、1列が1つの変数を意味している(ルール2)。 各セルには1つの値が入っています(ルール3)。 よって,これが整然データとなります。
上のロング型のデータを使って,ロングからワイド,ワイドからロングの操作を学びましょう。 data.frame()関数を使って,3つの変数name,year,saleをもつデータフレームを作ります。
library(knitr)
library(kableExtra)
df_car <- data.frame(
# rep("札幌",3)は"札幌"を3回繰り返すという意味
name = c(rep("トヨタ",2),rep("日産",2),rep("ホンダ",2)),
year = rep(c("2022", "2023"),3), # 時点
sale = c(31379507,37154298,8424585,10596695,14552696,16907725) # 気温
)
df_car |> kable() |> kable_styling(font_size = 20)| name | year | sale |
|---|---|---|
| トヨタ | 2022 | 31379507 |
| トヨタ | 2023 | 37154298 |
| 日産 | 2022 | 8424585 |
| 日産 | 2023 | 10596695 |
| ホンダ | 2022 | 14552696 |
| ホンダ | 2023 | 16907725 |
これはロング型の整然データとなります。
ロングからワイド pivot_wider
Rで使うならこのままでよいのですが,あえてこれをワイド型に変えてみましょう。
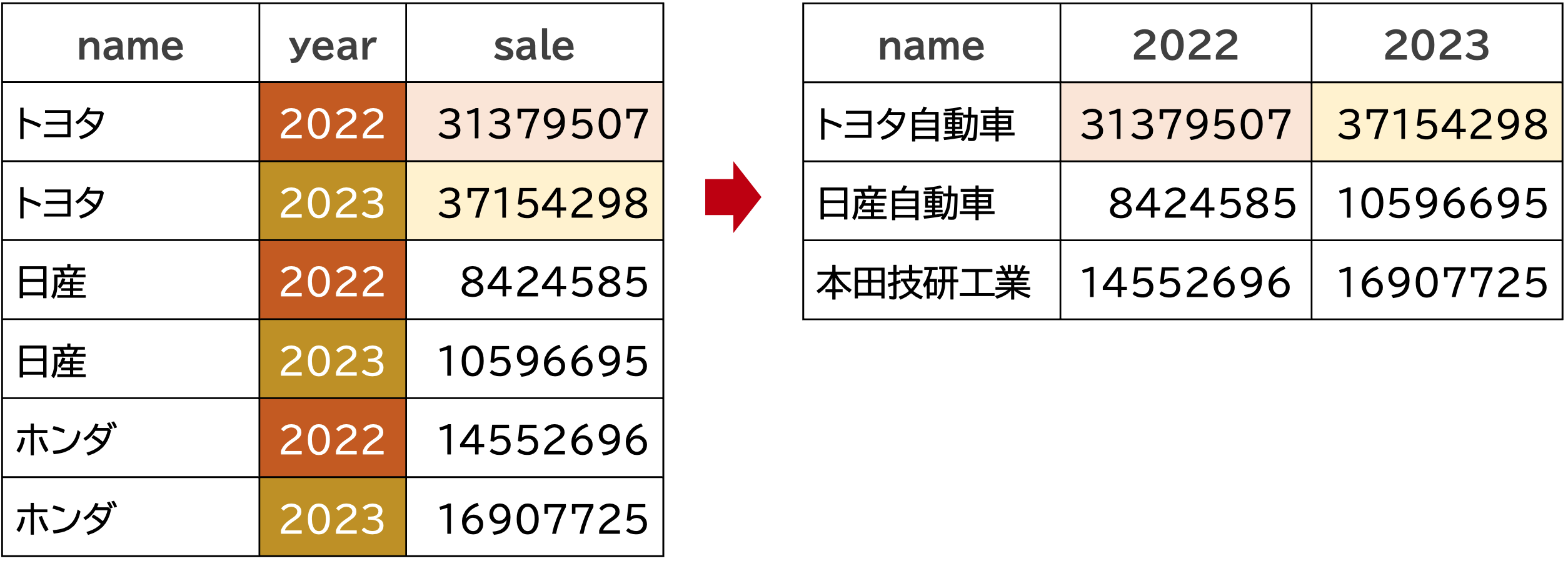
データフレームをロング型からワイド型に変換するには、tidyrパッケージのpivot_wider()関数を使います。
以前は、reshap2パッケージのdcast()関数や、その改良版のtidyrパッケージのspread()関数が使われていました。しかし、これらは根本的に設計ミスがあるとして、新たに設計しなおされたtidyrのpivot_wider()が現在のベストプラクティスです。
pivot_wider()の主な引数は,
names_fromvalues_from
です。 names_fromは,ワイド型に変換するときに,どの変数の値を列にするかを指定します。 values_fromは、names_fromで指定した変数の値が列になったとき、どの値をもつ変数にするのかを指定します。
以下のコードでは,year変数の値(つまり2022と2023)を列に,その変数がsale変数の値をもつように指定し,df_wideという変数に代入しています。
df_wide <- df_car |>
pivot_wider(
names_from = year, # 列にする変数
values_from = sale # 変数がもつ値
)
df_wide |> kable() |> kable_styling(font_size = 20)| name | 2022 | 2023 |
|---|---|---|
| トヨタ | 31379507 | 37154298 |
| 日産 | 8424585 | 10596695 |
| ホンダ | 14552696 | 16907725 |
これでワイド型に変換できました。
ワイドからロング pivot_longer
次に,このワイド型のデータをロング型に変換してみます。
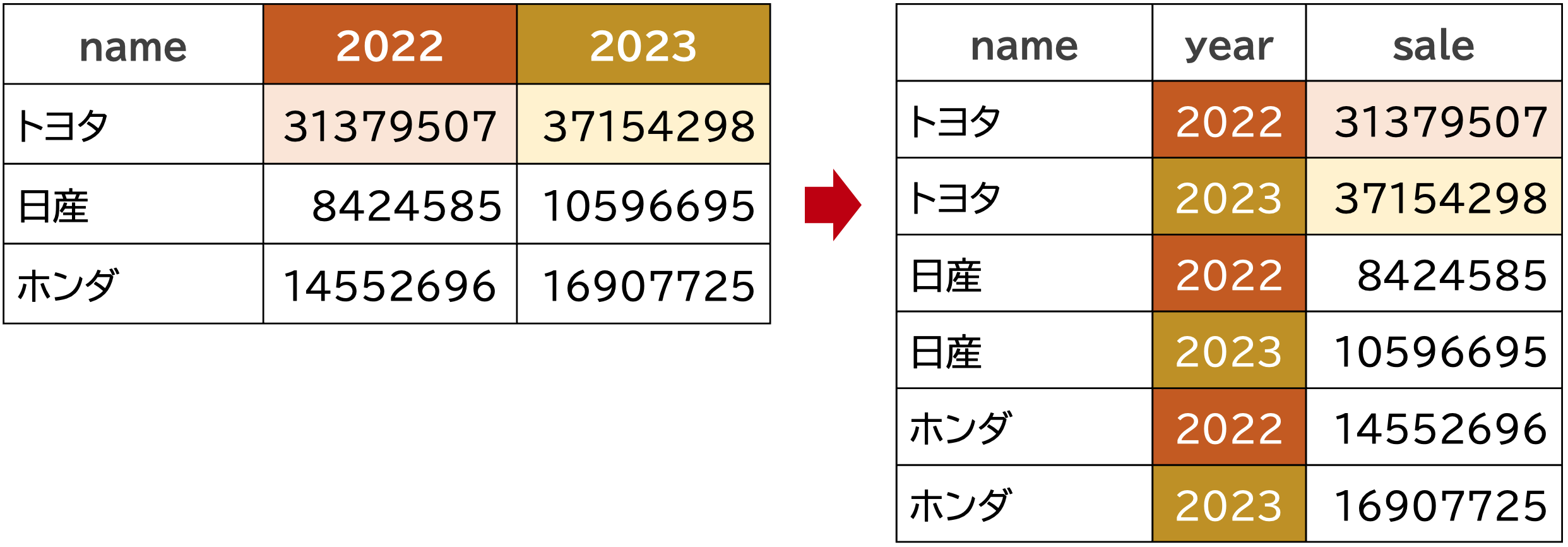
データフレームをワイド型からロング型に変換するには、tidyrパッケージのpivot_longer()関数を使います。
以前は、reshap2パッケージのmelt()関数や、その改良版のtidyrパッケージのgahter()関数が使われていました。しかし、これらは根本的に設計ミスがあるとして、新たに設計しなおされたtidyrのpivot_longer()が現在のベストプラクティスです。
ば
pivot_longer()の引数は,colsとnames_toとvalues_toです。
colsは,ロング型に変換するときに,どの変数を行にするかを指定names_toは,ロング型に変換するときに,どの変数の値を使うかを指定values_toは,ロング型に変換するときに,どの変数の値を使うかを指定
以下のコードでは,2022,2023の2つの変数を行に,yearという変数の値を列に,saleという変数の値を値にして,df_longという変数に代入しています。
df_long <- df_wide |>
pivot_longer(
cols = c("2022","2023"), # 縦にする変数
names_to = "year", # 縦にした変数名
values_to = "sale") # 値
df_long |> kable() |> kable_styling(font_size = 20)| name | year | sale |
|---|---|---|
| トヨタ | 2022 | 31379507 |
| トヨタ | 2023 | 37154298 |
| 日産 | 2022 | 8424585 |
| 日産 | 2023 | 10596695 |
| ホンダ | 2022 | 14552696 |
| ホンダ | 2023 | 16907725 |
元のロング型に戻りました。
8.2 練習してみよう。
まず、