100 |> rnorm(mean = 0, sd = 1)7 パイプ演算子
7.1 パイプ演算子の種類
関数の適用結果を次の関数の第一引数に渡す演算を行うパイプ演算子を紹介します。 パイプ演算子を使うことで,可読性が高く,メンテナンスしやすいコードを書くことが出来るので,ぜひ慣れておきましょう。
Rには
|>%>%
の2種類のパイプ演算子があります。 |>はR 4.1.0から導入されたいパイプ演算子です。 %>%はtidyverseパッケージ群magrittrパッケージに含まれるパイプ演算子です。 この|>と%>%はほぼ同じ機能をもっているので,ここでは基本関数の|>を使うことにします。
7.2 パイプ演算子
パイプ演算子を使うと、どのような処理になるのか、確認してみましょう。 パイプ演算子は、左辺の関数の結果を右辺の関数の第一引数に渡します。 例えば、3つの引数を必要とする関数だと、次のように書きます。

たとえば、正規分布にしたがう乱数を発生させるrnorm()関数は、引数に標本サイズ、分布の平均、分布の標準偏差をとり、rnorm(n = 100, mean = 0, sd = 1)のように書きます。
これをパイプ演算子を使うと,次のように書けます。
図で表すと次のようになります。

第1引数に代入される値を関数の外に出すことで、引数が複数ある関数の場合でも、関数のネストを避けることができ、可読性が高くなります。
もう一つの例として,データフレームの先頭の数行を表示するhead()を使ってみましょう。 head()は引数として
- データフレームやベクトル
- 表示する行数
の2つをとります。 省略せずにすべて書くと,次のようになります。

パイプ演算子を使うと,次のように書けます。
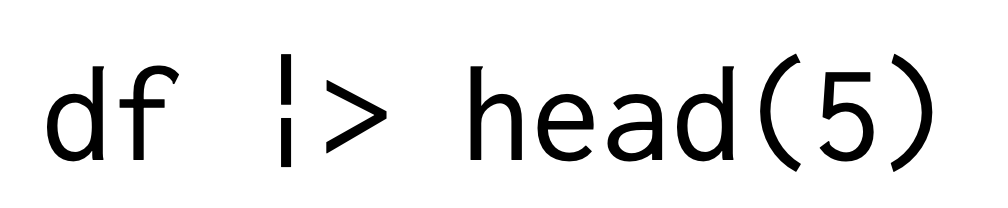
7.3 複数の処理をパイプでつなげる
複数の関数を組み合わせた処理を行う場合、複雑なコードになりがちなのを簡潔に書くことが出来ます。 たとえば,次のような処理を考えてみましょう。
- 平均ゼロ、標準偏差1の標準正規分布から100個の乱数を発生させる
- その乱数の平均を求める
- 小数点以下2桁で丸める
パイプ演算子を使わずに書くと、次のようになります。
関数が重なって(ネストして)いるので、読みにくいですね。 可読性の低いコードはエラーを見つけにくく、メンテナンスが困難になります。
-
set.seed():乱数の再現性を確保 -
rnorm():正規分布にしたがう乱数を発生 -
mean():算術平均を計算 -
round():小数点以下を丸める
このコードをパイプ演算子を使って書き直すと、次のように書けます。パイプ演算子の直後に改行し、インデントを揃えると、可読性が高くなります。
set.seed(123) # 乱数の再現性を確保
n <- 100
n |>
rnorm(mean = 0, sd = 1) |> # 正規分布から乱数
mean() |> # 平均を計算
round(2) # 小数点以下第2位で丸める[1] 0.09縦に長いコードになってしまいましたが、関数が重なっていないので可読性が高く、またコメントも書きやすくなります。
7.3.1 練習
7.4 パイプ演算子の相違点と注意点
基本Rの|>とmagrittrパッケージの%>%はほぼ同じ機能をもっていますが、いくつかの相違点があります。
-
x %>% meanはOKだけれど、x \> meanはエラーになる。x |> mean()と関数であることを明示する必要がある。 -
%>%はx %>% rnorm(100, mean = 0, sd =.)のように、.を使って左辺のxを右辺のどこに代入するかを指定できるが、|>は関数の第1引数のみに代入される。
