カイ二乗検定
このクロス集計表から読み取れる関係が、統計的に意味があるのかどうかを調べるためには、\(\chi ^2\) (カイ二乗)検定を行います。 \(\chi^2\) 検定は次のステップで実行します。
帰無仮説として、カテゴリー変数間に関連性はない と仮定
その仮定のもとで、観測されたクロス集計表の度数が、理論的に予測される度数と大きく異なるかどうか を検定
予測される度数と観測された度数の差が大きいほど、帰無仮説が棄却される
\(\chi^2\) 検定で用いられる統計量は、\(\chi^2\) 統計量と呼ばれ、次の式で計算されます。
\[
\chi^2 = \sum_{i=1}^n \sum_{j=1}^m \frac{(O_{ij} - E_{ij})^2}{E_{ij}}
\] ここで、\(O_{ij}\) は観測された度数(観測度数)、\(E_{ij}\) は理論的に予測される度数(期待度数)です。\(n\) と\(m\) はカテゴリー変数のカテゴリー数です。 つまり、2つのカテゴリー変数の関連性を調べる場合、\(\chi^2\) 統計量は次のように計算されます。
\[
\begin{aligned}
\chi^2 &= \frac{(O_{11} - E_{11})^2}{E_{11}} + \frac{(O_{12} - E_{12})^2}{E_{12}} \\
&+ \frac{(O_{21} - E_{21})^2}{E_{21}} + \frac{(O_{22} - E_{22})^2}{E_{22}}
\end{aligned}
\]
ここで、期待度数\(E\) をどうやって求めるのか、が問題となります。 期待度数の「期待」の意味は、帰無仮説のもとで期待される度数です。
\[
E_{ij} = \frac{O_{i\cdot} \times O_{\cdot j}}{O_{\cdot \cdot}}
\] ここで、\(O_{i\cdot}\) は\(i\) 行目の合計(横の合計)、\(O_{\cdot j}\) は\(j\) 列目の合計(縦の合計)、\(O_{\cdot \cdot}\) は全体の合計です。
先のメガネの例で計算してみます。 観察度数\(O\) は次のようになります。
男
41
204
245
女
81
74
155
合計
122
278
400
男の行合計\(O_{男\cdot}\) は245、女の行合計\(O_{女\cdot}\) は155、メガネ有りの列合計\(O_{\cdot メガネ有}\) は122、メガネなしの列合計\(O_{\cdot メガネ無}\) は278、全体の合計\(O_{\cdot \cdot}\) は400となります。 ここから、期待度数は次のように計算されます。
\[
\begin{aligned}
E_{男, メガネ} &= \frac{245 \times 122}{400} = 74.725 \\
E_{男, メガネ無} &= \frac{245 \times 278}{400} = 170.275 \\
E_{女, メガネ} &= \frac{155 \times 122}{400} = 47.275 \\
E_{女, メガネ無} &= \frac{155 \times 278}{400} = 107.725
\end{aligned}
\]
よって期待度数\(E\) は次のようになります。
男
74.725
170.275
245
女
47.275
107.725
155
合計
122
278
400
ここから、定義通りに、\(\chi^2\) 統計量を計算します。
\[
\begin{aligned}
\chi^2 = \frac{(41 - 74.725)^2}{74.725} + \frac{(204 - 170.275)^2}{170.275} + \frac{(81 - 47.275)^2}{47.275} + \frac{(74 - 107.725)^2}{107.725} = 7.2
\end{aligned}
\]
ここで計算した\(\chi^2\) 統計量は、自由度1の\(\chi^2\) 分布に従うということが知られています。この自由度は、カテゴリー変数のカテゴリー数から1を引いたものです。 ここでは、2カテゴリー同士のクロス集計表なので、自由度は\((2-1) \times (2-1) = 1\) となります。
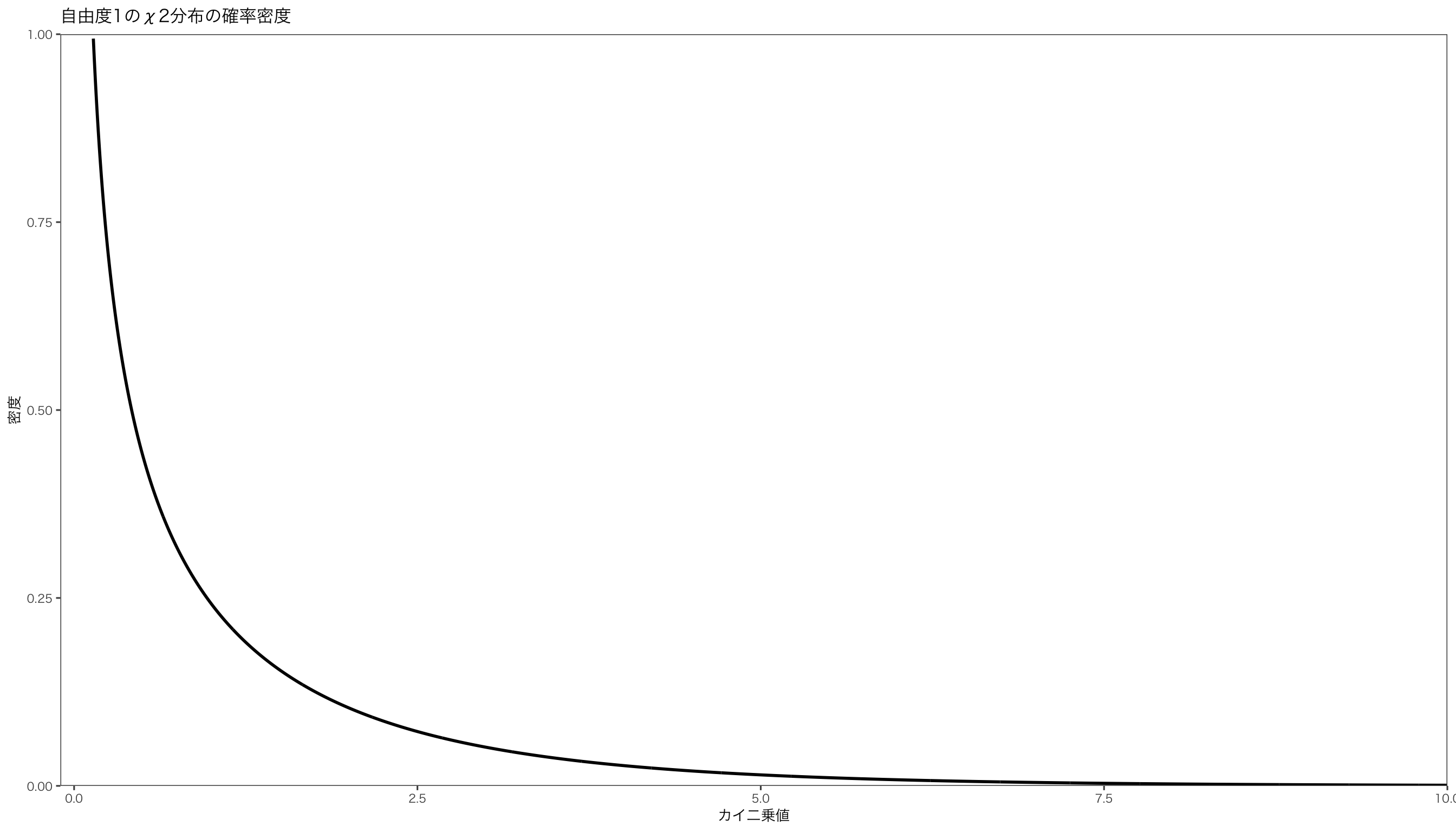
自由度1のカイ二乗分布の確率密度関数は次のようになります。
x = c ( 1 : 2500 ) / 250 # 数列を作成 y1 = dchisq ( x ,1 ) # カイ二乗分布の確率密度 df <- data.frame ( x , y1 ) # データフレームを作成 p <- ggplot ( df ) + aes ( x = x ,y = y1 ) # 作図 p <- p + geom_line ( size = 1 ) # 折れ線グラフ p <- p + ylim ( c ( 0 ,1 ) ) + ylab ( "密度" ) + xlab ( "カイ二乗値" ) + scale_y_continuous ( expand = c ( 0 ,0 ) , limits = c ( 0 ,1 ) ) +
scale_x_continuous ( expand = c ( 0 ,0 ) , limits = c ( - 0.1 ,10 ) )
p <- p + ggtitle ( "自由度1のχ2分布の確率密度" ) + mystyle print ( p )
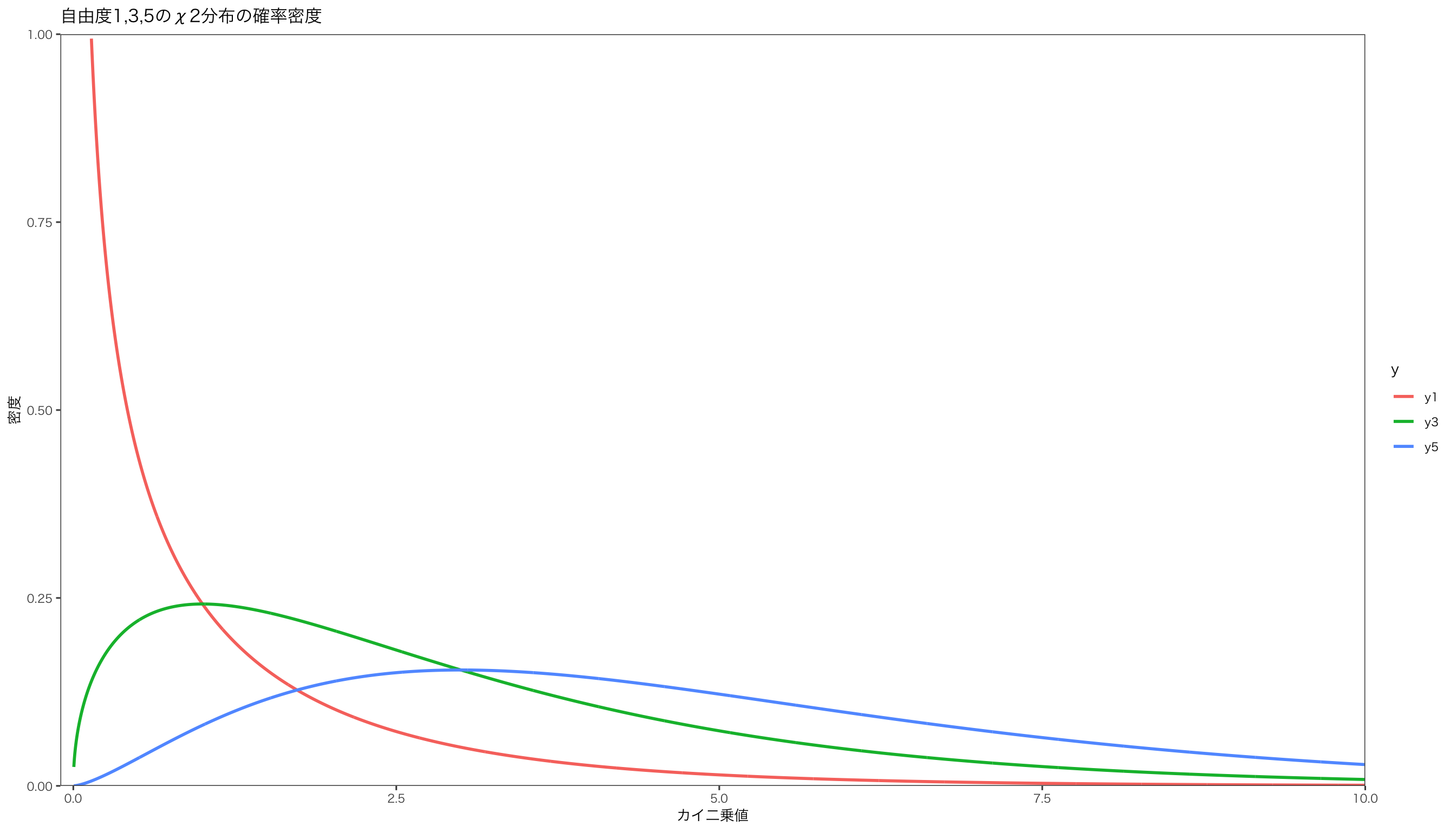
参考までに、自由度が変わると\(\chi^2\) 分布の形状は次のようなものになります。
x = c ( 1 : 2500 ) / 250 y1 = dchisq ( x ,1 ) # 自由度1のカイ二乗分布の確率密度 y3 = dchisq ( x ,3 ) # 自由度3のカイ二乗分布の確率密度 y5 = dchisq ( x ,5 ) # 自由度5のカイ二乗分布の確率密度 df <- data.frame ( x , y1 , y3 , y5 ) # データフレームを作成 df <- df %>% pivot_longer ( names_to = "y" ,values_to = "value" ,cols = - x ) # データを長く整形
p <- ggplot ( df ) + aes ( x = x ,y = value , group = y , color = y ) # 作図 p <- p + geom_line ( size = 1 ) # 折れ線グラフ p <- p + ylim ( c ( 0 ,1 ) ) + ylab ( "密度" ) + xlab ( "カイ二乗値" ) + scale_y_continuous ( expand = c ( 0 ,0 ) , limits = c ( 0 ,1 ) ) +
scale_x_continuous ( expand = c ( 0 ,0 ) , limits = c ( - 0.1 ,10 ) )
p <- p + ggtitle ( "自由度1,3,5のχ2分布の確率密度" ) + mystyle print ( p )
自由度1の\(\chi^2\) 分布における有意水準5%の値を調べるにはqchisq() pに確率、dfに自由度を指定します。
alpha <- 0.05 # 有意水準(ここでは5%) df <- 1 # 自由度 qchisq ( 1 - alpha , df )
自由度1のカイ二乗分布における有意水準5%の値は3.84であることが分かりました。 この値を超えると、有意水準5%で帰無仮説を棄却することになります。
では先程計算した\(\chi^2\) 統計量は、有意水準5%で帰無仮説を棄却するかどうかを調べてみましょう。
chi2 <- 7.2 qchisq ( 1 - alpha , df ) < chi2
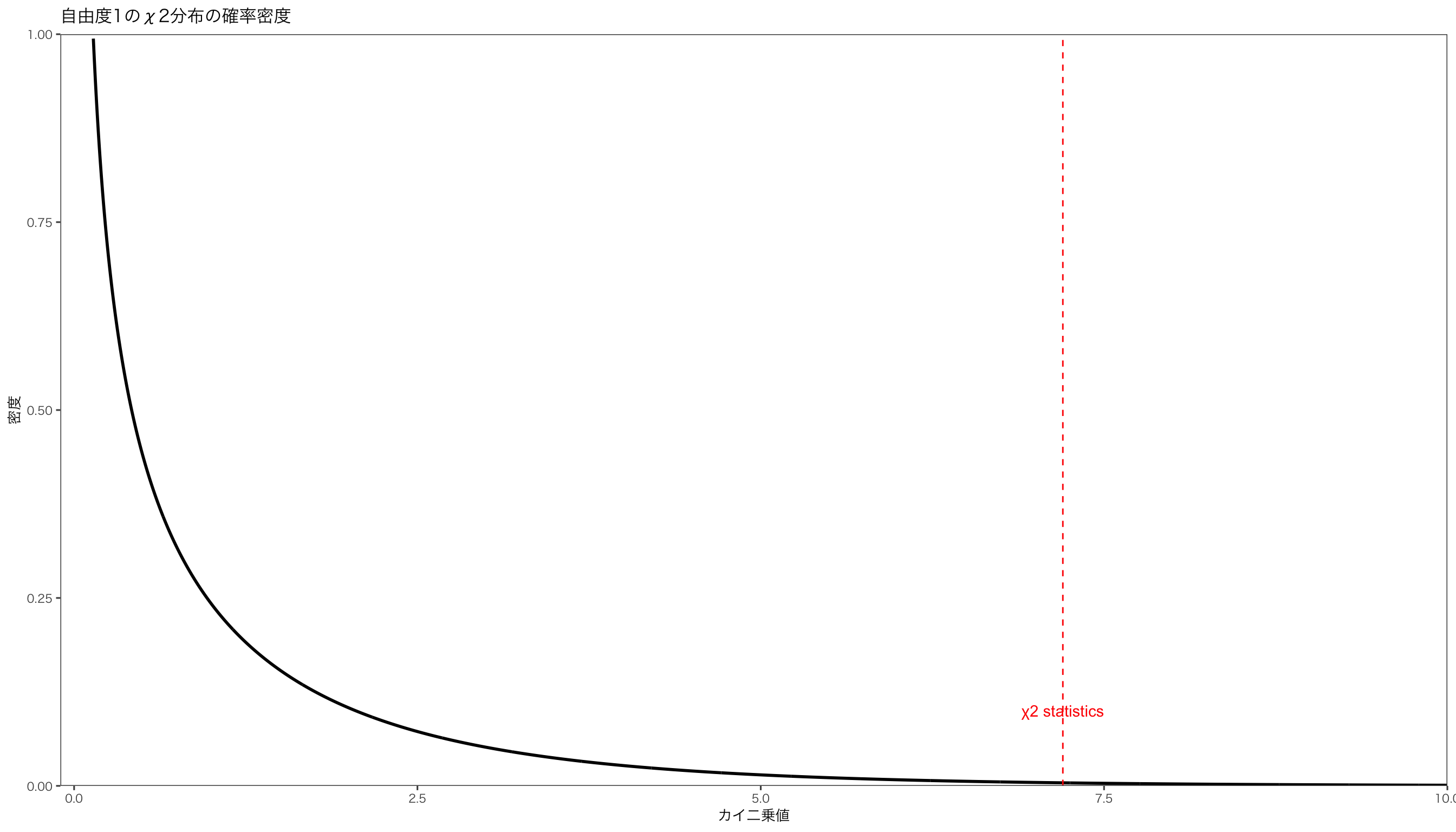
より、\(\chi^2\) 統計量は有意水準5%で帰無仮説を棄却することが分かりました。 ちなみに、自由度1のカイ二乗分布の確率密度関数と\(\chi^2\) 統計量の位置を重ねてみると次のようになります。
df <- data.frame ( x ,y1 ) p <- ggplot ( df ) + aes ( x = x ,y = y1 ) p <- p + geom_line ( size = 1 ) p <- p + ylim ( c ( 0 ,1 ) ) + ylab ( "密度" ) + xlab ( "カイ二乗値" ) + scale_y_continuous ( expand = c ( 0 ,0 ) , limits = c ( 0 ,1 ) ) +
scale_x_continuous ( expand = c ( 0 ,0 ) , limits = c ( - 0.1 ,10 ) )
p <- p + ggtitle ( "自由度1のχ2分布の確率密度" ) + mystyle p <- p + geom_vline ( xintercept = chi2 , linetype = "dashed" , color = "red" ) p <- p + annotate ( "text" , x = chi2 , y = 0.1 , label = "χ2 statistics" , color = "red" ) print ( p )
このように、\(\chi^2\) 統計量は、自由度1のカイ二乗分布のもとで生じる確率は、
となり、非常に小さな値であることが分かりました。 つまり、2つのカテゴリー変数の間に関係がない、という帰無仮説の下で、観測された度数が発生することはほぼありえない、ということが言えるので、帰無仮説は棄却され、2つのカテゴリー変数には関係があると結論付けられます。
Rでχ2検定
Rではchisq.test() xに度数表、correctに補正を行うかどうか、pに期待度数を指定します。
先ほどの男女とメガネの例をここでも使ってみます。 まずmatrix()
O <- matrix ( c ( 41 , 81 , 204 , 74 ) , nrow = 2 , ncol = 2 ) row.names ( O ) <- c ( "男性" , "女性" ) colnames ( O ) <- c ( "メガネ" , "メガネなし" ) E <- matrix ( c ( sum ( O [ ,1 ] ) * sum ( O [ 1 ,] ) / sum ( O ) , #男眼鏡
sum ( O [ ,1 ] ) * sum ( O [ 2 ,] ) / sum ( O ) , #男眼鏡無
sum ( O [ ,2 ] ) * sum ( O [ 1 ,] ) / sum ( O ) , #女眼鏡
sum ( O [ ,2 ] ) * sum ( O [ 2 ,] ) / sum ( O ) #女眼鏡無
) , nrow = 2 , ncol = 2 ) print ( O )
メガネ メガネなし
男性 41 204
女性 81 74
[,1] [,2]
[1,] 74.725 170.275
[2,] 47.275 107.725
この観察度数と期待度数から、定義通りに\(\chi^2\) 統計量を計算してみます。
chi <- ( O [ 1 ,1 ] - E [ 1 ,1 ] ) ^ 2 / E [ 1 ,1 ] + #男眼鏡 ( O [ 1 ,2 ] - E [ 1 ,2 ] ) ^ 2 / E [ 1 ,2 ] + #男眼鏡無
( O [ 2 ,1 ] - E [ 2 ,1 ] ) ^ 2 / E [ 2 ,1 ] + #女眼鏡
( O [ 2 ,2 ] - E [ 2 ,2 ] ) ^ 2 / E [ 2 ,2 ] #女眼鏡無
print ( chi )
\(\chi^2\) 統計量がとなりました。 この\(\chi^2\) 統計量が自由度1の\(\chi^2\) 分布にしたがう場合,この統計量が得られる確率は次のようになります。
この確率は0.0000000000000055733となり,ほぼゼロであることが分かりました。 よって、2つのカテゴリー変数は無関係である,という帰無仮説は棄却され、2つのカテゴリー変数には関係があると結論付けられます。
ちなみに,上記のようなめんどくさい処理をしなくても,Rにはchisq.test() chisq.test() xに度数表、correctに補正を行うかどうか、pに期待度数を指定します。 補正は行わないので,correctはFALSEとします。 pはデフォルトで等確率となっているので,今回は省略します。
Pearson's Chi-squared test
data: O
X-squared = 56.517, df = 1, p-value = 5.571e-14
となり,先ほどの結果と一致しました。
各マスに入る度数が少ない場合には、フィッシャーの直接確率検定を使います。
Fisher's Exact Test for Count Data
data: O
p-value = 1.204e-13
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
0.1127341 0.2982245
sample estimates:
odds ratio
0.1845096
カイ二乗分布(補足)
カイ二乗分布は、確率変数\(Z_1, Z_2,\dots, Z_k\) が互いに独立であり、それぞれが標準正規分布\(N(0,1)\) に従うとき、その二乗和が従う分布を自由度\(k\) のカイ二乗分布といいます。
\[
\chi^2 = Z_1^2 + Z_2^2 + \dots + Z_k^2
\]
導出は省きますが、自由度\(k\) のカイ二乗分布の密度関数は、
\[
\begin{aligned}
f(x) =
\begin{cases}
\frac{1}{2^{k/2} \Gamma(k/2)} x^{k/2 - 1} \mathrm{e}^{-x/2} & (x \geq 0)\\
0 & (x < 0)
\end{cases}
\end{aligned}
\]
ここで、\(\Gamma\) はガンマ関数であり、
\[
\Gamma \left (\frac n2 \right) = \int_0^{\infty} t^{k/2 - 1} \mathrm{e}^{-t} \mathrm{d}t
\] となります。
導出は省きますが、カイ二乗分布の期待値は\(k\) となり、分散は\(2k\) となります。