df <- readr::read_csv("data/kesho_2023.csv")4 Rによるデータ操作
第5回講義の到達目標は、
- 様々なデータをRで読み込むことができる。
- 読み込んだデータを確認できる。
- 基本的なデータ操作ができる。
- 整然データの構造を理解し、データを必要な形に成形できる。
- 複数のデータを結合できる。
- 作成したデータを保存できる。
第5回講義の到達度検証のための課題は、以下の通りです。
- CSVファイル、Excelファイルを読み込んで、中身を確認する。
- 必要なデータの抽出、変数の追加、変数の選択を行い、分析に適した形に持っていける。(
filter()、mutate(),select(),arrange(),pivot_longer(),pivot_wider()) - データ結合の種類を理解し、複数のデータを結合して、1つのデータフレームを作成する。(
bind_rows(),bind_cols(),left_join(),right_join(),inner_join(),full_join())
この章では、Rを用いたデータ操作の基本的な方法を学びます。 この章は何度も読み返し、繰り返し練習してください。 ここでは、なぜRを使うと便利なのかを分かってもらうために、Excelの操作と比較する形で、Rのデータ操作の基本を学びます。
4.1 データの読み込み
4.1.1 CSVファイルの読み込み
多くのプログラミング言語で、読み込むデータとして最も多いのが、CSV形式のファイルです。ファイルの拡張子は.csvです。 CSVとは、Comma Separated Valuesの略で、カンマで区切られたデータのことです。 次のような形をしています。
企業ID,決算年月,売上高
13,2020/03,1000
13,2021/03,1200
13,2022/03,1500
24,2020/03,2000
24,2021/03,2200
24,2022/03,2500
33,2020/03,3000
33,2021/03,3200
33,2022/03,3500このように、値とコンマ,のみで構成されたファイルのため、余計な情報が入っておらず、またファイルサイズも小さく、加工が簡単なので、データのやり取りによく使われます。
さっそくファイルを読み込んでみましょう。 ここでは、松浦のウェブサイトにあるデータkeshohin_2023.csvを読み込んでみます。 Rの場合は、read.csvという関数を使って、URLを直接指定して読み込むことができます。読み込んだデータをdfという変数に代入しています。
Excelの場合は、インターネット上のデータを直接取り込むことは難しいので、いったんパソコンの中に保存してから、ファイルを開くとします。
重要Rの場合
Rでcsvファイルを読み込む最もシンプルな方法は、readrパッケージのread_._csv()を用いて、ファイル名やファイルを参照するURLを直接指定することです。
ヒントMS Excelの場合
- URL
https://so-ichi.com/kesho_2023.csvをブラウザに入力してファイルをダウンロードし、任意の場所に保存 - 「ファイル」から「開く…」をクリックして、保存したCSVファイルを選択し「開く」をクリック
4.1.2 Excelファイルの読み込み
MS Excelのファイルは拡張子が.xlsx、古いMS Excelだと.xlsです。 RでExcelファイルを読み込むときは、read_excelという関数を使います。 Excelファイルを用意するのが面倒なので、ここではこうやれば読み込めるよ、というコードだけ説明します。ファイル名はhoge.xlsxとします。
重要Rの場合
RでMS Excelのファイルを読み込むには、readxlパッケージのread_excel()関数を用います。
dfx <- readxl::read_excel("hoge.xlsx")
ヒントMS Excelの場合
- 「ファイル」から「開く…」をクリックし、保存してあるExcelファイルを選択し「開く」をクリック
MS Excelの問題点は、目的のデータがどのExcelファイルに入っていて、それがどこに保存されているのかを覚えておかないと、いちいちファイルを開いて探さないといけないことです。
Rだとソースコードを残すことができますので、 どこにあるファイルを読み込んで、そこに何が入っているのかをコメントで残しておくことができます。
4.2 読み込んだデータの確認
MS Excelは読み込んだデータが画面上に表として表示されていますが、Rでは変数に代入しただけでは、画面には何も表示されません。 そこでデータの中身を確認する関数として、次のようなものがあります。
-
head(): 最初の数行を表示させる基本関数 -
str(): データの構造を表示させる基本関数 -
glimpse(): データの構造を表示させるdplyrパッケージの関数 -
names(): 変数名を表示させる基本関数
これらを使って、データの中身を確認し、データの形に適した処理方法を学ぶ必要があります。 以下では、head()関数を使って、データの最初の数行を表示させてから、str()関数でデータの中の変数とその型を確認します。
Excelは目視が中心ですが、見ただけでは、文字列なのか数なのかが分からないので、やはりデータの型は確認する必要があります。
重要Rの場合
head(df)| code | name | term | shubetsu | ren | sales | netincome | month |
|---|---|---|---|---|---|---|---|
| 0000641 | 資生堂 | 1985/11 | 10 | 1 | 371040 | 14526 | 12 |
| 0000641 | 資生堂 | 1986/11 | 10 | 1 | 375294 | 13632 | 12 |
| 0000641 | 資生堂 | 1987/11 | 10 | 1 | 378977 | 9014 | 12 |
| 0000641 | 資生堂 | 1988/11 | 10 | 1 | 401311 | 9515 | 12 |
| 0000641 | 資生堂 | 1989/03 | 10 | 1 | 130654 | 4265 | 4 |
| 0000641 | 資生堂 | 1990/03 | 10 | 1 | 456352 | 11362 | 12 |
str(df)spc_tbl_ [130 × 8] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
$ code : chr [1:130] "0000641" "0000641" "0000641" "0000641" ...
$ name : chr [1:130] "資生堂" "資生堂" "資生堂" "資生堂" ...
$ term : chr [1:130] "1985/11" "1986/11" "1987/11" "1988/11" ...
$ shubetsu : num [1:130] 10 10 10 10 10 10 10 10 10 10 ...
$ ren : num [1:130] 1 1 1 1 1 1 1 1 1 1 ...
$ sales : num [1:130] 371040 375294 378977 401311 130654 ...
$ netincome: num [1:130] 14526 13632 9014 9515 4265 ...
$ month : num [1:130] 12 12 12 12 4 12 12 12 12 12 ...
- attr(*, "spec")=
.. cols(
.. code = col_character(),
.. name = col_character(),
.. term = col_character(),
.. shubetsu = col_double(),
.. ren = col_double(),
.. sales = col_double(),
.. netincome = col_double(),
.. month = col_double()
.. )
- attr(*, "problems")=<externalptr>
ヒントMS Excelの場合
画面を見て確認する。
このデータには,
-
code: 企業コード (文字列) -
name: 企業名 (文字列) -
term: 決算年月 (文字列) -
shubetsu: 会計基準の種類 (数値) -
ren: 連結か単体 (数値) -
sales: 売上高 (数値) -
netincome: 当期純利益 (数値) -
month: 決算月数 (数値)
が入っています。
4.3 データの整形
4.3.1 データ操作の基礎
さあ面白くなってきました。 次はデータを操作していきます。 Rによるデータ操作では、tidyverseパッケージ群のdplyrパッケージが大活躍します。
dplyrパッケージの関数の中でもよく使うものに次のようなものがあります。
-
select(): 変数を選択する -
filter(): データを抽出する -
mutate(): 変数を追加する -
arrange(): データを並び替える -
summarise(): データを集計する -
group_by(): データをグループ化する
4.3.2 パイプ演算子
Rでソースコードを書く際に,理解しやすく,読みやすいコードにするために非常に便利なのが,パイプ演算子%>%です。 パイプ演算子%>%は,左側のオブジェクトを右側の関数の第一引数に渡すという処理を行います。 たとえば,
(1 + 2) %>% sqrt()[1] 1.732051と書くと,sqrt(1 + 2)と同じ意味になります。 たとえば,rnorm()関数を使って平均0,分散1の標準正規分から100個のデータを作りたいとします。 rnorm()関数は3つの引数を取ります。
- データの個数
- 平均
- 標準偏差
したがって,rnorm(100, 0, 1)と書くと,平均0,分散1の標準正規分布から100個のデータを取り出すことができます。 パイプ演算子を使うと,
100 %>% rnorm(mean = 0, sd = 1) [1] 1.04904678 0.07639883 -0.75697270 0.37655845 -0.08885599 2.67141694
[7] -0.95952837 0.12353454 0.48620291 0.81273495 0.70842692 0.12110941
[13] 0.57787373 -0.39564048 0.50562129 0.26236141 1.75072819 -0.62228147
[19] -0.36095618 -0.39263369 0.04026552 -1.00800921 0.17566362 0.65825530
[25] 0.60977697 1.08200763 -0.07157836 -0.48578883 0.79962235 -0.60266406
[31] -0.01295024 -0.40866917 -0.55278506 1.40104084 -3.38609492 0.07092376
[37] 1.04541323 -0.50569370 -1.88167818 0.05458494 0.29969144 1.30471105
[43] 0.68454360 0.90902019 0.98254585 -0.90148719 1.27671785 -1.24461219
[49] 0.29581441 -0.24992371 0.74756422 -0.23599981 0.08611600 -0.98372456
[55] -1.74214254 0.53213215 -0.84525439 -0.29081930 1.32587712 -0.23758186
[61] -2.01586639 0.28588506 -0.05826849 -2.39098974 -0.68360839 -0.42943348
[67] 1.25273383 0.08861651 0.21759030 0.83671978 1.62438529 -0.42458428
[73] -0.31567405 -0.06753097 -0.80315394 -1.38922686 1.02872034 0.97486146
[79] 0.84954363 -0.60095082 -0.50273932 -0.66087691 1.12083165 0.78963209
[85] 1.16800492 -0.64012492 2.16993817 0.07438599 -0.05551100 1.84063496
[91] -0.03423224 0.53663417 0.79133048 0.80305281 1.05954063 -0.45511910
[97] 0.81321593 -0.28000852 -0.24259990 0.26966435となります。 これはrnorm()関数の第1引数がデータの個数なので,そこに100を渡しています。 ここで平均に値を渡したい場合を考えます。 mean引数は第2引数なので,パイプ演算子では自動で渡してくれません。 そこで.を使って渡す場所を指定してあげます。
100 %>% rnorm(100, mean =. , sd = 1) [1] 99.48414 100.55043 101.49447 99.79477 98.74074 103.09391 100.33138
[8] 100.03975 100.74935 99.60760 99.40869 99.99641 101.36463 101.69035
[15] 100.15975 99.12414 101.46265 101.05177 100.40755 100.32189 99.80759
[22] 101.36477 102.25377 101.33084 99.05787 100.35000 101.04740 98.59898
[29] 99.85558 101.66646 98.92126 100.00681 101.10623 99.07853 100.27107
[36] 98.79647 98.47117 99.31924 99.58037 98.08712 99.56893 98.48145
[43] 99.35185 98.94954 100.13944 100.59549 99.35598 102.48570 99.43112
[50] 100.16990 100.82219 99.69611 99.65931 99.71616 100.34882 99.95558
[57] 98.14776 100.31550 100.56867 101.58925 100.75819 98.65112 99.69973
[64] 99.41396 100.83111 100.15921 99.24980 99.57647 100.92822 100.17583
[71] 100.20778 100.85627 99.66512 99.37383 99.25883 100.05133 101.01489
[78] 98.71267 101.41261 101.31742 99.98194 98.83220 101.53454 99.09145
[85] 100.08306 101.28939 99.51206 99.21923 99.07628 99.42316 99.85937
[92] 101.48726 99.93870 99.51818 100.12466 99.55353 99.02480 99.86421
[99] 99.02654 99.14768これで平均100,標準偏差1の正規分布から100個のデータを取り出せました。
これだけだとパイプ演算子%>%の便利さが伝わらないので,たとえば次のような処理を考えてみましょう。
- 2020年のデータを抜き出し,
- 売上高当期純利益率を計算し,
- 産業グループごとに平均を計算する
- 利益率が高い順番に並び替える
をパイプ演算子を使って書くと,
のように,上から順番に処理を実行し,次に渡す,というプロセスが分かりやすく,読みやすいコードができました。 コメントも残しておけば,後から見返したときにも分かりやすいですし,他人によんでもらうときも親切ですね。 したがって,以下ではパイプ演算子を駆使して,データ操作を行っていきます。
新しい変数を作成する mutate
新しい変数を作成するには,dplyrパッケージのmutate()関数を使います。 先ほど読みこんだデータから,当期純利益を売上高で除して売上高当期純利益率を計算して,ratioという変数を作ってみましょう。
重要Rの場合
df <- df %>%
mutate( # 新しい変数を作成
ratio = netincome / sales # 売上高利益率
)
ヒントMS Excelの場合
I1のセルに変数名を表すratioと入力する。 F列のsaleとG列のnetincomeを使って,I2のセルに
= G2 / F2
とし,I2セルの右下の四角をダブルクリックすると,自動で下のセルにも同じ計算がコピーされる。
次に,ある変数の値に応じて異なる値をとる変数を作るには,mutate()関数とifelse()関数を同時に使います。ifelse()関数は次のような引数を取ります。
ifelse(条件, 条件が真のときの値, 条件が偽のときの値)先ほど計算した売上高当期純利益率が5%以上ならば「高い」,そうでなければ「低い」という変数highlowを作ってみましょう。
重要Rの場合
df <- df %>%
mutate( # 新しい変数を作成
highlow = ifelse(ratio >= 0.05, "高い", "低い") # 売上高利益率
)
ヒントMS Excelの場合
J1セルにhighlowと入力する。 J2セルに
= if(I2 >= 0.05, "高い", "低い")
と入力し,J2セルの右下の四角をダブルクリックすると,自動で下のセルにも同じ計算がコピーされる。
Excelだとセルの移動や変数名の入力,計算式の入力,セルのコピーといった作業で,キーボードとマウスを行ったり来たりする必要があり,若干面倒です。
ついでに,mutate()関数を使って,長すぎる企業名を短くしてみます。 ここでは「ポーラ・オルビスホールディングス」を「ポーラ」と略してみます。 mutate()とifelseを使って,name変数の値が「ポーラ・オルビスホールディング」ならば「ポーラ」という値をとる変数name上書きします。を作ってみましょう。
重要Rの場合
df <- df %>%
mutate( # 新しい変数を作成
name = ifelse(
name == "ポーラ・オルビスホールディング", "ポーラ", name) # 企業名
)データを抽出する filter
データを抽出するには,dplyrパッケージのfilter()関数を使います。 filter()関数は,次のような引数を取ります。
filter(データ, 条件)先ほど作成したratio2が「高い」企業だけを抽出してみましょう。 filter()関数の中の条件は,==を使って,"高い"という文字列と一致するかどうかを確認しています。 ここでは,highlow変数の値が"高い"と一致する企業だけを抽出し,df_highという変数に代入しています。
重要Rの場合
df_high <- df %>%
filter(highlow == "高い") # 条件
ヒントMS Excelの場合
highlow変数のあるJ列をクリックして枠を移動させ,上の「ホーム」メニューから「並び替えとフィルター」をクリックし,「フィルター」をクリックする。 すると,変数名highlowのヨコに漏斗のようなマークが出るので,それをクリックすると,記録されたデータの種類が出てくるので,「高い」だけにチェックが入った状態にする。
Excelのクリック回数が増えてきましたね。
filter()関数の中で指定する条件は,
-
==: 一致する -
!=: 一致しない -
>=や<=: 以上や以下 -
>や<: より大きいや小さい -
%in%: いずれかに一致する
などがあります。またこれらの条件を組み合わせることもできます。 その場合は,以下のように&や|を使います。
-
&: かつ -
|: または
たとえば,資生堂と花王を抽出したり,売上高当期純利益率が5%以上かつ売上高が1000億円以上の企業を抽出するには, 次のように書きます。
変数を選択する select
データの中から必要な変数だけを選択するには,dplyrパッケージのselect()関数を使います。 たとえば,先ほど作成したdfから,企業コード,企業名,売上高当期純利益率の3つの変数だけを選択してみましょう。
重要Rの場合
df3 <- df %>%
select(code, name, ratio) # 3つの変数だけ選択
ヒントMS Excelの場合
オリジナルのデータをコピーして,下のタブから別のシートを選択し,そこに貼り付ける。
貼り付けたデータからcodeとnameとratio以外の列を削除する。
MS Excelだと,不要なデータを削除するのが怖い作業で,必要になったときにまた元のデータを読み込まないといけないので,面倒ですし,ミスのもとです。
select()関数の中で使えるものには,以下のようなものがあります。 とても便利なので,覚えておくとよいでしょう。
-
-: 除外する (-ratioとかくとratio以外を選択) -
:: 連続する変数を選択 (code:renと書くとcodeからrenまでを選択) -
starts_with(): ある文字列で始まる変数を選択 -
ends_with(): ある文字列で終わる変数を選択
たとえば,mutate()で新しい変数を作る場合に,変数名に法則性をつけておけば,starts_with()を使って一気に変数を選択することができます。 たとえば,比率を表す変数はratioで始まるように統一しておく,基準化した変数には_Kを最後に付けておく,などです。
データを並び替える arrange
データを並び替えるには,dplyrパッケージのarrange()関数を使います。 たとえば,先ほど作成したdfから,売上高当期純利益率を並び替えてみましょう。
重要Rの場合
df %>%
select(name, ratio) %>% # 2つの変数だけ選択
arrange(ratio) %>%
head()| name | ratio |
|---|---|
| ポーラ | -0.4349581 |
| 資生堂 | -0.0757638 |
| 資生堂 | -0.0385906 |
| 資生堂 | -0.0216680 |
| 資生堂 | -0.0138412 |
| 資生堂 | -0.0126617 |
小さい順に並び替えられました。 大きい順にするには,desc()関数を使います。 ついでにknitrパッケージのkabble()関数で表を見やすく加工してみます。
重要Rの場合
これでどの企業のどの年度の売上高当期純利益率が大きいのかが一目瞭然になりました。
MS Excelだと,
ヒントMS Excelの場合
「ホーム」メニューから「並び替えとフィルター」をクリックし,「昇順」をクリックする。
必要なデータだけ選択してコピペすれば,表が完成します。
となります。 簡単ですが,MS Excelの並び替えは注意が必要で,並び替えた後にデータを追加すると,並び替えが解除されてしまい,元に戻せなくなったり,空列があると並び替えがうまくいかなかったりします。
4.3.3 long形式とwide形式
人間には読みやすいけれどパソコンは読みにくい,というデータの形式があります。 例えば下の表を見てみましょう。
| 地点 | 6時 | 12時 | 18時 |
|---|---|---|---|
| 札幌 | 12℃ | 15℃ | 13℃ |
| 大阪 | 20℃ | 24℃ | 22℃ |
| 福岡 | 23℃ | 25℃ | 25℃ |
このような形のデータをワイド形式(wide)といいます。 天気予報で見かけそうなこの表は,人間にとっては分かりやすいですが,実はコンピュータにとっては,分かりにくいものです。 コンピュータが理解しやすいデータとして表すなら,次のような表になります。
| 地点 | 時間 | 気温(℃) |
|---|---|---|
| 札幌 | 6時 | 12 |
| 札幌 | 12時 | 15 |
| 札幌 | 18時 | 13 |
| 大阪 | 6時 | 20 |
| 大阪 | 12時 | 24 |
| 大阪 | 18時 | 22 |
| 福岡 | 6時 | 23 |
| 福岡 | 12時 | 25 |
| 福岡 | 18時 | 25 |
このような形式のデータをロング型(long)といいます。 このロング型のうち,一定のルールに従って作成されたデータを整然データ(tidy data)といい,Rでは,この整然データを扱うことが多いです。
R神Hadley Wickham氏は,データの型を理解することを,データ分析の第一歩とし,その一貫として整然データという考え方を提唱しています。 整然データとは,次のような原則に従って構築されたデータのことです(Wickham, 2014) 参考https://id.fnshr.info/2017/01/09/tidy-data-intro/。
- 個々の変数 (variable) が1つの列 (column) をなす。
- 個々の観測 (observation) が1つの行 (row) をなす。
- 個々の観測の構成単位の類型 (type of observational unit) が1つの表 (table) をなす。
- 個々の値 (value) が1つのセル (cell) をなす
上の表は,地点,時間,天気,気温の4つの変数があり1つの列をつくっています(ルール1)。 大阪12時の天気は雨,気温は12℃といったように1つの行が1つの観測を表しています(ルール2)。 このデータには種類の異なる観測はない(ルール3)。 また,各セルには1つの値が入っています(ルール4)。 よって,これが整然データとなります。
上のロング型の天気データを使って,ロングからワイド,ワイドからロングの操作を学びましょう。
まずデータを作ります。
place time temp
1 札幌 6時 12
2 札幌 12時 15
3 札幌 18時 13
4 大阪 6時 20
5 大阪 12時 24
6 大阪 18時 22
7 福岡 6時 23
8 福岡 12時 25
9 福岡 18時 25これはロング型の整然データとなります。
ロングからワイド pivot_wider
Rで使うならこのままでよいのですが,あえてこれをワイド型に変えてみましょう。
教科書で使用されているspread()は「根本的に設計ミスってた」と公式で発表されているので,R神が作ったpivot_wider()を使います。widerという名前の通り,ワイド型に変換する関数です。
pivot_wider()の引数は,names_fromとvalues_fromです。names_fromは,ワイド型に変換するときに,どの変数を列にするかを指定します。values_fromは,ワイド型に変換するときに,どの変数の値を使うかを指定します。
以下のコードでは,time変数の値を列に,temp変数の値を値にして,df_wideという変数に代入しています。
df_wide <- df_weather %>%
pivot_wider(names_from = time, values_from = temp)
print(df_wide)# A tibble: 3 × 4
place `6時` `12時` `18時`
<chr> <dbl> <dbl> <dbl>
1 札幌 12 15 13
2 大阪 20 24 22
3 福岡 23 25 25これでワイド型に変換できました。
ワイドからロング pivot_longer
次に,このワイド型のデータをロング型に変換してみます。 教科書では,tidyrのgather()を使っていますが,これもwider()と同じ問題を持っているので,R神によるpivot_longer()を使います。
pivot_longer()の引数は,colsとnames_toとvalues_toです。
-
colsは,ロング型に変換するときに,どの変数を行にするかを指定 -
names_toは,ロング型に変換するときに,どの変数の値を使うかを指定 -
values_toは,ロング型に変換するときに,どの変数の値を使うかを指定
以下のコードでは,6時,12時,18時の3つの変数を行に,timeという変数の値を列に,tempという変数の値を値にして,df_longという変数に代入しています。
# A tibble: 9 × 3
place time temp
<chr> <chr> <dbl>
1 札幌 6時 12
2 札幌 12時 15
3 札幌 18時 13
4 大阪 6時 20
5 大阪 12時 24
6 大阪 18時 22
7 福岡 6時 23
8 福岡 12時 25
9 福岡 18時 25元のロング型に戻りました。
4.3.4 データの結合
別々のデータを結合させて使いたいことはよくあります。 例えば,次のようなデータを結合させる場合を考えてみましょう。
表A
| name | term | sale |
|---|---|---|
| トヨタ | 2020 | 1000 |
| トヨタ | 2021 | 900 |
| トヨタ | 2022 | 1400 |
| ホンダ | 2020 | 800 |
| ホンダ | 2021 | 700 |
| ホンダ | 2022 | 900 |
df_A <- data.frame(
name = c("トヨタ", "トヨタ", "トヨタ", "ホンダ", "ホンダ", "ホンダ"),
term = c(2020, 2021, 2022, 2020, 2021, 2022),
sale = c(1000, 900, 1400, 800, 700, 900)
)表B
| name | term | sale |
|---|---|---|
| 日産 | 2020 | 400 |
| 日産 | 2021 | 500 |
| 日産 | 2022 | 900 |
| マツダ | 2020 | 300 |
| マツダ | 2021 | 400 |
| マツダ | 2022 | 200 |
df_B <- data.frame(
name = c("日産", "日産", "日産", "マツダ", "マツダ", "マツダ"),
term = c(2020, 2021, 2022, 2020, 2021, 2022),
sale = c(400, 500, 900, 300, 400, 200)
)表C
| name | term | netincome |
|---|---|---|
| トヨタ | 2020 | 100 |
| トヨタ | 2021 | 90 |
| トヨタ | 2022 | 150 |
| ホンダ | 2020 | 140 |
| ホンダ | 2021 | 100 |
| ホンダ | 2022 | 90 |
| スバル | 2020 | 30 |
| スバル | 2021 | 35 |
| スバル | 2022 | 50 |
df_C <- data.frame(
name = c("トヨタ", "トヨタ", "トヨタ", "ホンダ", "ホンダ", "ホンダ", "スバル", "スバル", "スバル"),
term = c(2020, 2021, 2022, 2020, 2021, 2022, 2020, 2021, 2022),
netincome = c(100, 90, 150, 140, 100, 90, 30, 35, 50)
)この3つのデータを結合させる場合を考えます。 まず表Aと表Bは同じ変数をもつデータなので,これらを結合させるには,縦につなげる必要があります。 このような結合を縦結合とか連結といいます。 縦結合は,dplyrパッケージのbind_rows()関数を使います。
df_AB <- bind_rows(df_A, df_B)
print(df_AB) name term sale
1 トヨタ 2020 1000
2 トヨタ 2021 900
3 トヨタ 2022 1400
4 ホンダ 2020 800
5 ホンダ 2021 700
6 ホンダ 2022 900
7 日産 2020 400
8 日産 2021 500
9 日産 2022 900
10 マツダ 2020 300
11 マツダ 2021 400
12 マツダ 2022 200縦に結合できたので,トヨタ,ホンダ,日産,マツダのデータが入ったデータベースdf_ABができました。
次に,このdf_ABとdf_Cを結合させます。 df_Cはnetincomeというdf_ABにはない変数があり,異なる変数をもつデータ同士の結合となります。 これらを結合させるには,横につなげる必要があります。 このような結合を結合といいます。
結合には,
- 内部結合(inner join)
- 外部結合(outer join)
があり,外部結合には,
- 完全結合(full join)
- 左結合(left join)
- 右結合(right join)
があります。
内部結合は両方のデータベースに存在する観測値のみを保持するため,多くのデータが欠落することになりますが,外部結合は、少なくとも1つのテーブルに存在する観測値を保持するので,大部分のデータが欠落することにはなりません。
3つの外部結合の特徴は次の通りです。
- 完全結合は、xとyのすべての観測値を保持します。
- 左結合は、xのすべての観測値を保持します。
- 右結合は、yのすべての観測値を保持します。
R神の神書籍R for Data Science (2e)の図がわかりやすいので,ここで紹介します。
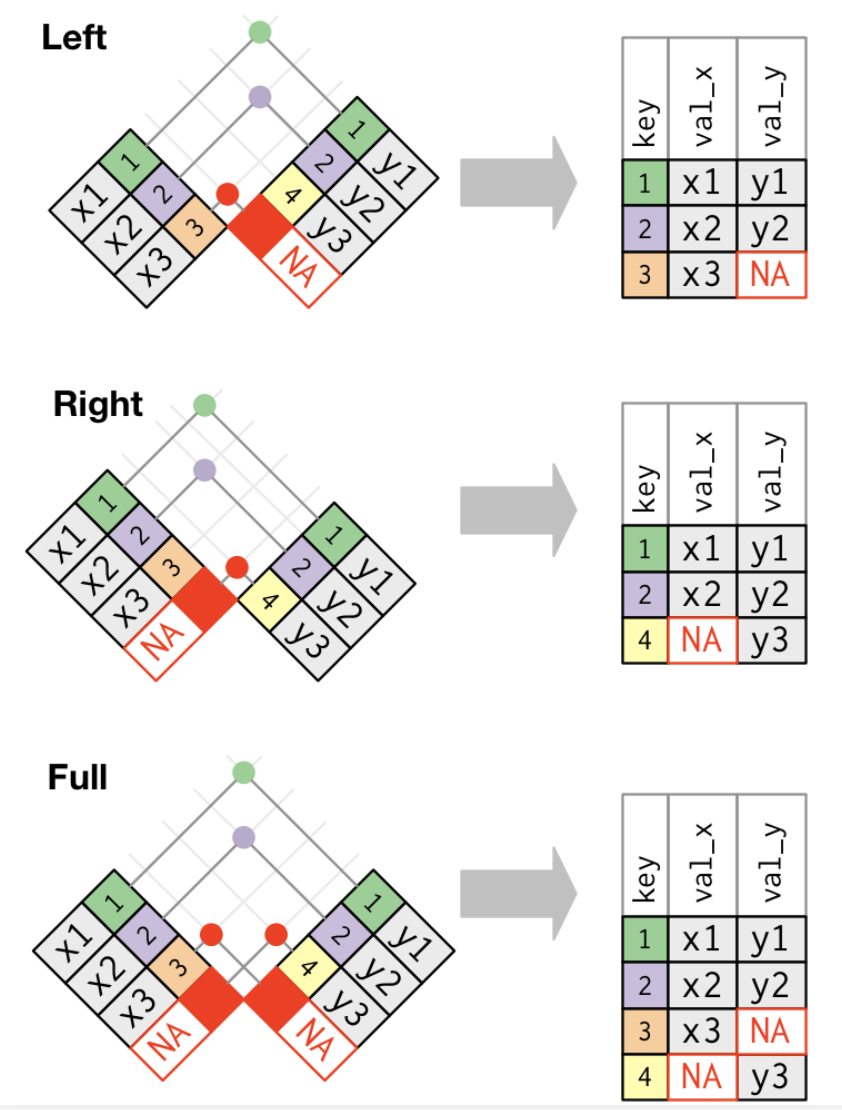
内部結合と3つの外部結合をベン図で表すとこうなります。
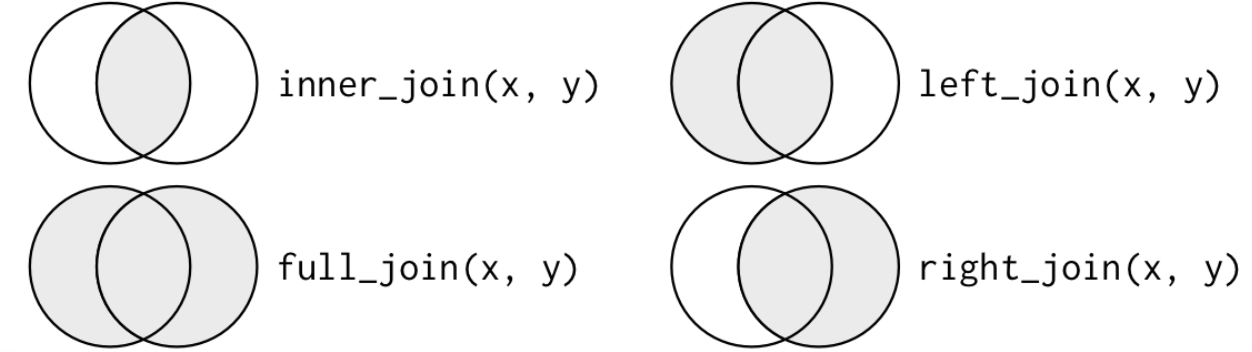
最もよく使われる結合は左結合です。 元データに他のデータを結合する場合,元データに含まれるデータのみ保持したい場合が多いので,追加データを調べるときはいつもこれを使います。 左結合はデフォルトの結合であるべきで、他の結合を選択する強い理由がない限り、これを使用します。
では,df_ABとdf_Cを左結合してみましょう。 結合する際にキーとなる変数を指定する必要があります。 ここではnameとtermの2つの変数をキーとして指定します。 こうすることで,nameとtermが一致する観測値を結合します。
name term sale netincome
1 トヨタ 2020 1000 100
2 トヨタ 2021 900 90
3 トヨタ 2022 1400 150
4 ホンダ 2020 800 140
5 ホンダ 2021 700 100
6 ホンダ 2022 900 90
7 日産 2020 400 NA
8 日産 2021 500 NA
9 日産 2022 900 NA
10 マツダ 2020 300 NA
11 マツダ 2021 400 NA
12 マツダ 2022 200 NAdf_ABにはトヨタ,ホンダ,日産,マツダのデータがありますが,df_Cには日産とマツダのデータがなく,スバルのデータがあります。 そのため左結合すると,日産とマツダのnetincomeにはNAが入り,スバルは欠落します。
df_ABとdf_Cを右結合してみましょう。
name term sale netincome
1 トヨタ 2020 1000 100
2 トヨタ 2021 900 90
3 トヨタ 2022 1400 150
4 ホンダ 2020 800 140
5 ホンダ 2021 700 100
6 ホンダ 2022 900 90
7 スバル 2020 NA 30
8 スバル 2021 NA 35
9 スバル 2022 NA 50df_Cには日産とマツダのデータがなく,トヨタとホンダとスバルのデータがあります。 そのため右結合すると日産とマツダのデータが欠落し,df_Cに含まれていたトヨタ,ホンダ,スバルのデータが残ります。 しかしスバルのsaleにはNAが入ります。
最後に,df_ABとdf_Cを完全結合してみましょう。
name term sale netincome
1 トヨタ 2020 1000 100
2 トヨタ 2021 900 90
3 トヨタ 2022 1400 150
4 ホンダ 2020 800 140
5 ホンダ 2021 700 100
6 ホンダ 2022 900 90
7 日産 2020 400 NA
8 日産 2021 500 NA
9 日産 2022 900 NA
10 マツダ 2020 300 NA
11 マツダ 2021 400 NA
12 マツダ 2022 200 NA
13 スバル 2020 NA 30
14 スバル 2021 NA 35
15 スバル 2022 NA 50df_ABにはトヨタ,ホンダ,日産,マツダのデータがありますが,df_Cにはトヨタ,ホンダ,スバルのデータがあるため, 完全結合したdf_fullにはすべての企業のデータが入ります。 しかし,日産とマツダのnetincomeにはNAが入り,スバルのsaleにもNAが入ります。
このように,結合するデータによって,結合したデータに含まれるデータが変わるので,自分が望む結合後のデータの形を考えて,どの結合を使うかを選ぶ必要があります。
ついでに内部結合もやってみましょう。
name term sale netincome
1 トヨタ 2020 1000 100
2 トヨタ 2021 900 90
3 トヨタ 2022 1400 150
4 ホンダ 2020 800 140
5 ホンダ 2021 700 100
6 ホンダ 2022 900 90予想どおり,両方のデータに含まれているトヨタとホンダだけが残り,片方のデータにしか含まれていない日産,マツダ,スバルのデータは欠落してしまいました。 このように内部結合は,両方のデータに存在する観測値のみを保持するため,多くのデータが欠落することになり,利用する機会があまりないです。
4.4 データの保存
前処理が終わったデータは,ファイルとして保存しておくとよいでしょう。 たとえば,df_leftをdf_left.csvというファイル名で保存するには,readrパッケージのwrite_csv()関数を使います。
write_csv()関数の第1引数は保存したいオブジェクト(ここではdf_left)で,あとの主要な引数は,
filena = "NA"append = FALSE
となります。 fileは保存するファイル名を指定します。 naは欠損値をどうするかを指定します。デフォルトではNAとなっています。 appendは,既存のファイルに追記するかどうかを指定します。基本は上書きなので,FALSEにしておきます。
write_csv(df_left, file = "df_left.csv")これで,作業ディレクトリにdf_left.csvが保存されました。 分析を進める際は,このようにして保存したデータを読み込んで使います。