なぜRを使うのか?
Rを使う理由を、メリットとデメリットを比較しながら以下で説明します。
データ分析のツールとして大学で使うことが多いのはMS Excelですが,MS Excelは表計算ソフトウェアで,統計分析を行うこともできますが,その機能は限定的です。 データアナリストが利用しているプログラミング言語として最も有名なものはPython (パイソン),Julia (ジュリア),そしてR (アール)などでしょう。
ぜんぶ無料
学習しやすい・教材たくさん
作業履歴が残る
卒業後も使える
大規模データもさくさく扱える。
Git/GitHubでバージョン管理できる
なんかかっこいい
いろいろインストールしたり,設定が必要
命令文でデータを操作するのでぱっと見わかりにくい。
R言語の文法と単語を覚えなきゃいけない
キーボード入力が多いので,タッチタイピング必須
なぜQuartoを使うのか?
Rユーザーが使うことが多いRstudioを開発したPosit社が提供する、R Markdownをさらに進化させたQuartoを使うメリットは以下の通りです。
MS Wordのように、書いた文章がそのまま印刷されるようなWYSIWYG(What You See Is What You Get)なワープロソフトとは異なり、特定の記法にしたがって書かれた文章をコンピューターで処理することで印刷用の文書に変換するWYSIWYM(What You See Is What You Mean)な文書処理システムをマークアップ言語 といいます。Markdownが代表的なマークアップ言語で、そこにRを組み込んだR Markdownが広く利用されています。そのR Markdownをさらに進化させて、文書内でRやPython, Juliaなどのコードを実行できるようにしたのがQuartoです。
Markdown形式で記述できるので、簡単に論文・レポートの体裁を整えられる
文章作成とデータ分析を同じ場所で行える
文章中にRだけでなくPythonやJuliaを組み込める
レポートの再現性を高めることができる
グラフや表のデザインがきれい
なんかかっこいい 無料
Markdown記法を覚えないといけない
入力するものと出力されるものが違う。
ビジネスで利用される場面が少ない
Rでどんなことができる?
1. 楽にデータ操作ができる
Excelでは扱えないかなり大きなデータでも簡単にデータ操作ができます。 たとえば、データ分析の練習用データとして有名なirisデータをいろいろ操作してみましょう。 irisは「あやめ」という花の花びらとがく片の長さと幅の4項目と3種類のあやめの分類名の1項目の合計5項目が150件収録されているデータベースです。Rには練習用に最初から入っているので、head()関数を使ってirisの先頭の6行を読み込んでみます。
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
このように、Sepal.Length、Sepal.Width、Petal.Length、Petal.Width、Speciesという5つの項目が入っていることが分かります。Sepalは花びらで、Petalはがく片です。まず花びらの長さSepal.Lengthの平均を求めてみましょう。平均を返す関数はmean()です。
あやめの花びらの長さの平均は、5.8433333であることが分かりました。簡単ですね。 では次に,あやめの花びらの長さの標準偏差 を求めてみましょう。標準偏差を返す関数はsd()です。 下のボックスの緑の三角ボタンを押すと,Rコードが実行され,下に結果が表示されます。 sd()で標準偏差,max()で最大値,min()で最小値,median()で中央値を求めることができるので,sdのところを書き換えて実行し,結果を確認してみてください。
Please enable JavaScript to experience the dynamic code cell content on this page.
次に、あやめの種類を表すSpeciesにはどんな種類があるのか見てみましょう。 Speciesに入っている種類を確認するには、table()関数を使ってみます。
Please enable JavaScript to experience the dynamic code cell content on this page.
あやめの種類には、setosa、versicolor, virginicaがあり、それぞれ50個のデータがあることが分かります。
次に、このirisを使って、グラフを作ってみます。
2. キレイなグラフが書ける。
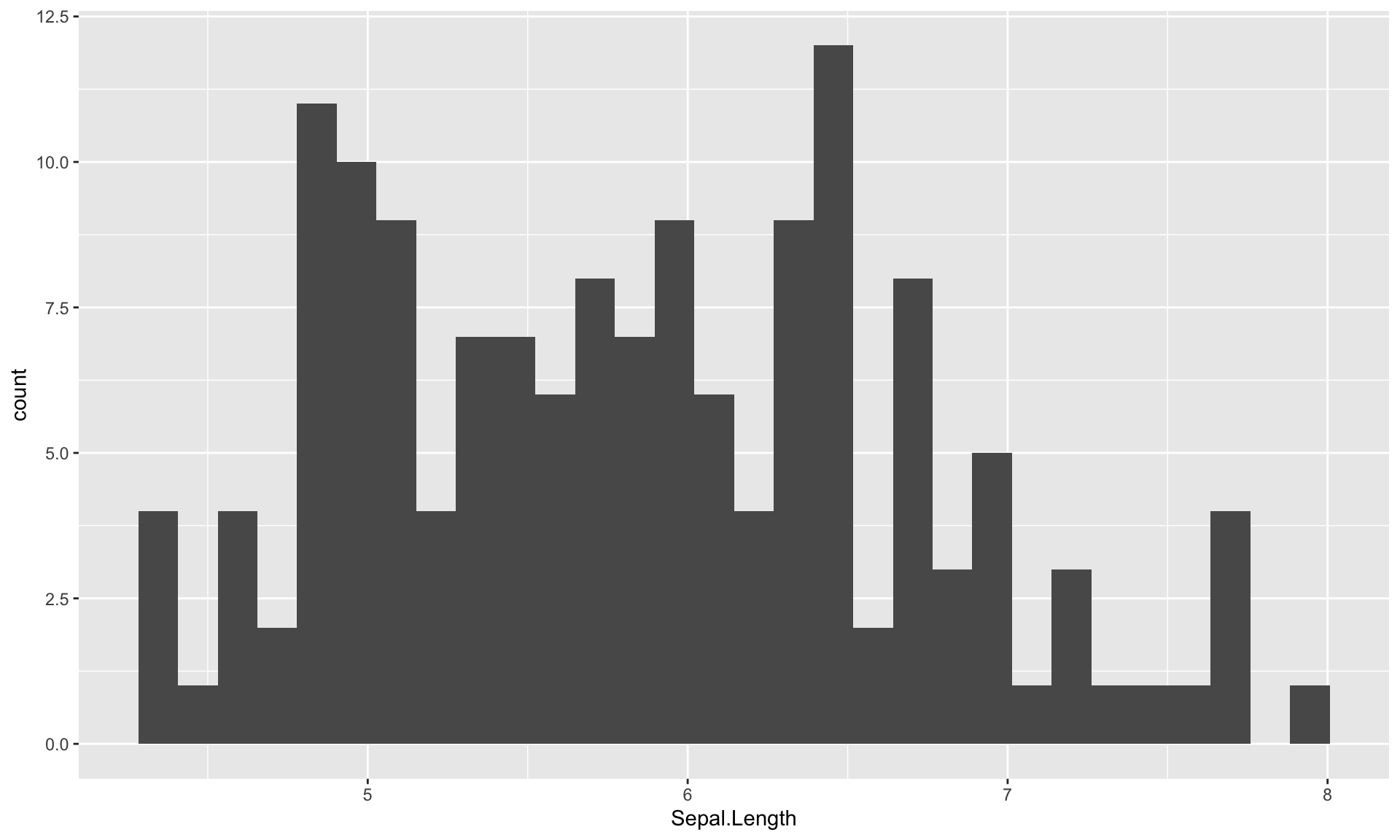
では次にグラフを作成してみます。 最初に、花びらの長さのヒストグラムを書いてみます。 さくっとヒストグラムを作るには,基本関数のhist()を使います。 ここでは,irisデータのSepal.Lengthを使ってヒストグラムを作成してみましょう。
Please enable JavaScript to experience the dynamic code cell content on this page.
Rはグラフ作成が得意なプログラミング言語です。 その機能を最大限活用するために,非常に簡単かつ分かりやすく美しいグラフを作成できるggplot2パッケージを導入します。
# install.packages("ggplot2") # 1回だけ実行 library (ggplot2)<- ggplot (iris) + aes (Sepal.Length) + geom_histogram ()print (g)
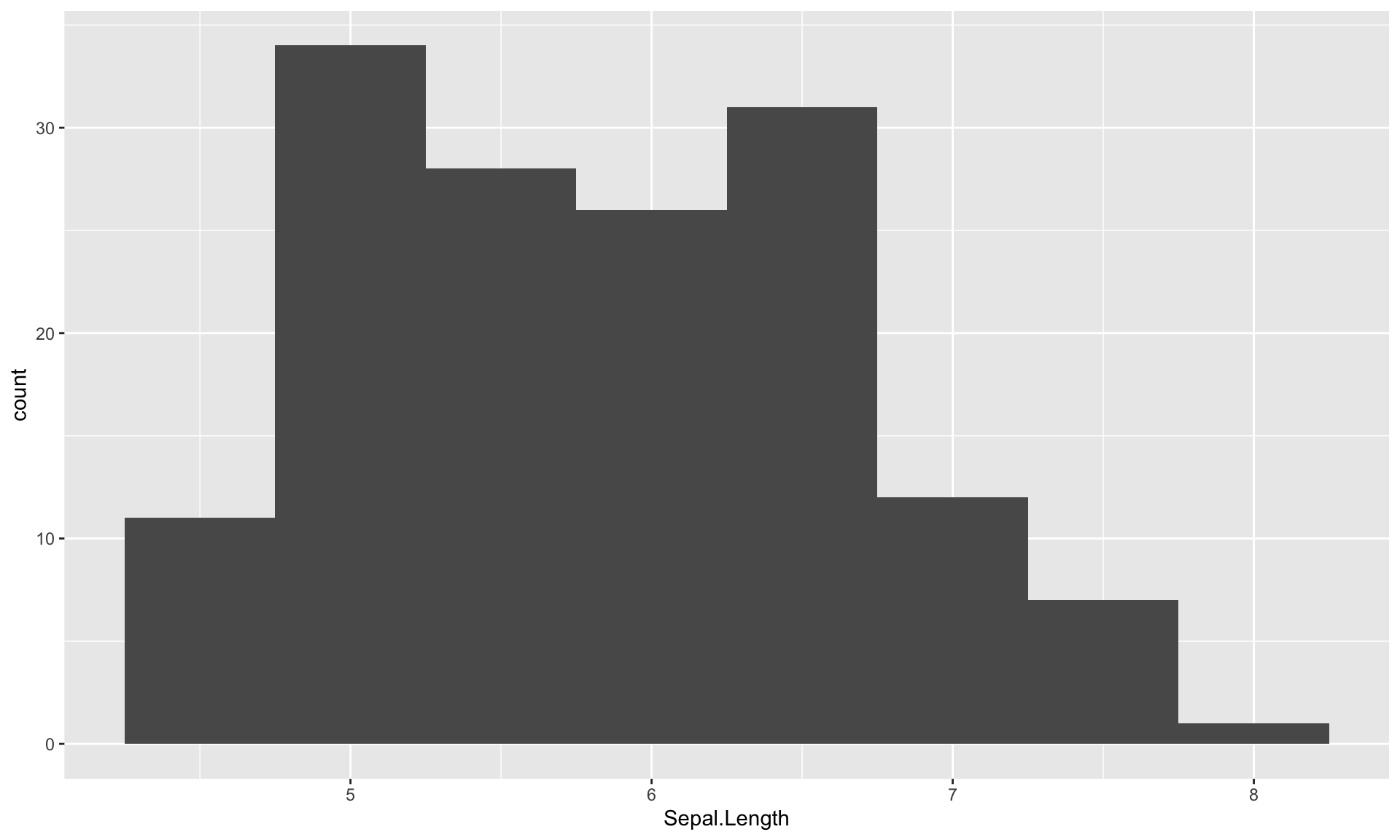
ヒストグラムの階級幅を変更したり、棒の数を変更するには、geom_histogram()の中で指定します。 例えば、階級幅を0.5 でヒストグラムを作る場合は、binwidth = 0.5のように指定します。
<- ggplot (iris) + aes (Sepal.Length) + geom_histogram (binwidth = 0.5 )print (g)
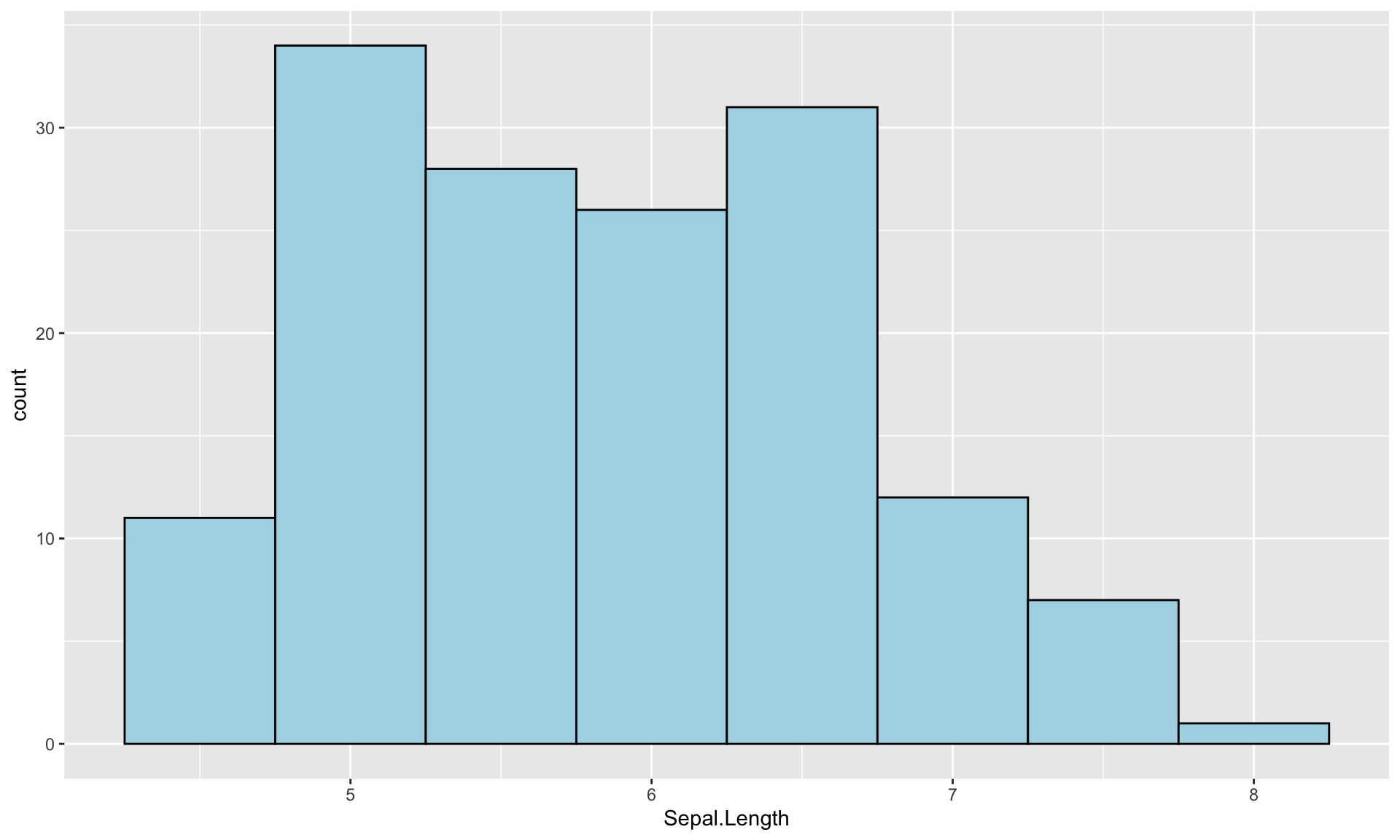
グラフが黒くて見づらいので、デザインをいじってみます。 geom_histogram()関数の中で、線を黒、中を薄青色に指定します。
<- ggplot (iris) + aes (Sepal.Length) + geom_histogram (color= "black" , fill= "lightblue" ,binwidth = .5 )print (g)
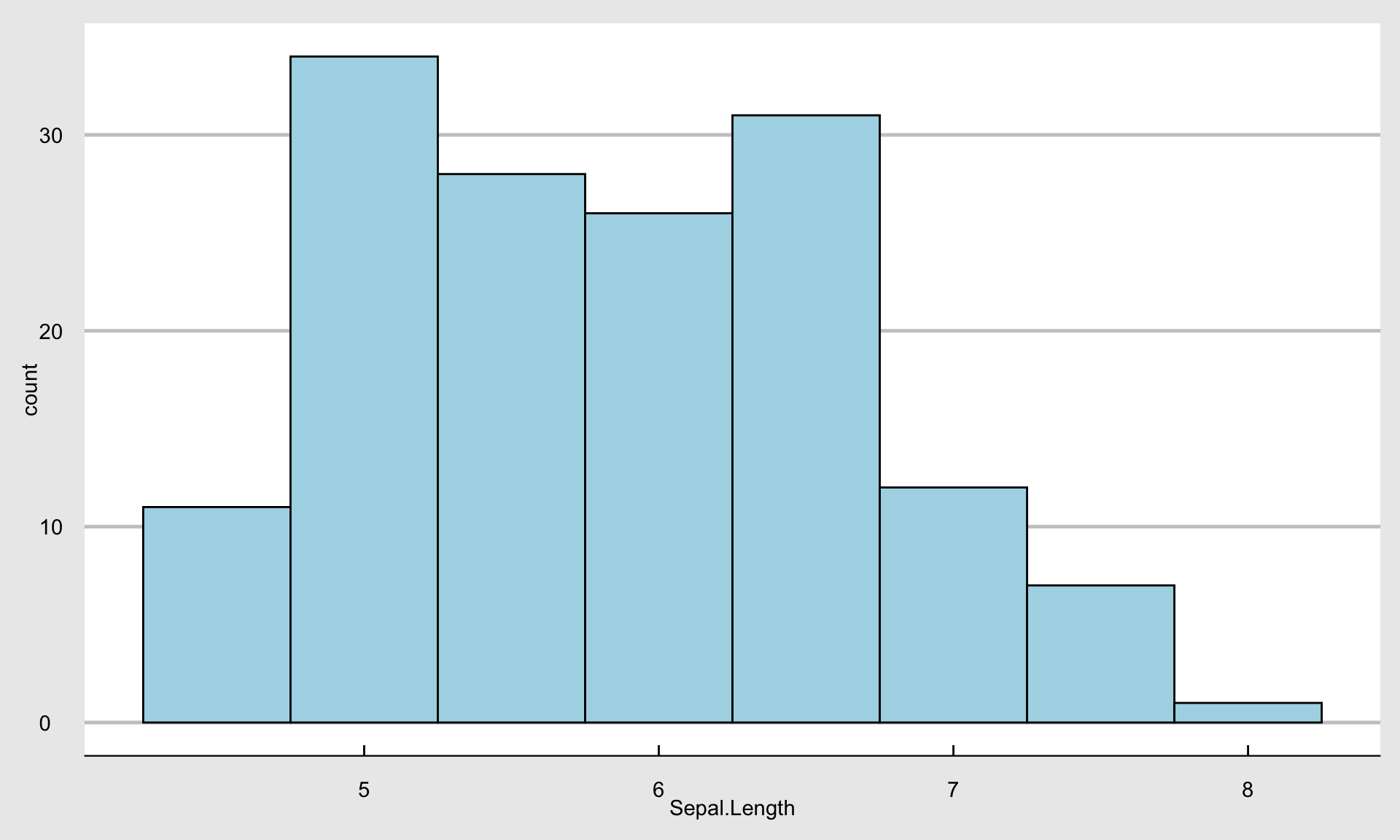
背景が地味なので、グラフを雑誌Economist風にしてみます。
+ theme_economist_white () + scale_colour_economist ()
次は花びらの長さと幅の散布図を書いてみます。 ggplot2で散布図を書くためには、aes()でx 軸とy 軸を指定し、geom_point()で散布図を指定する。
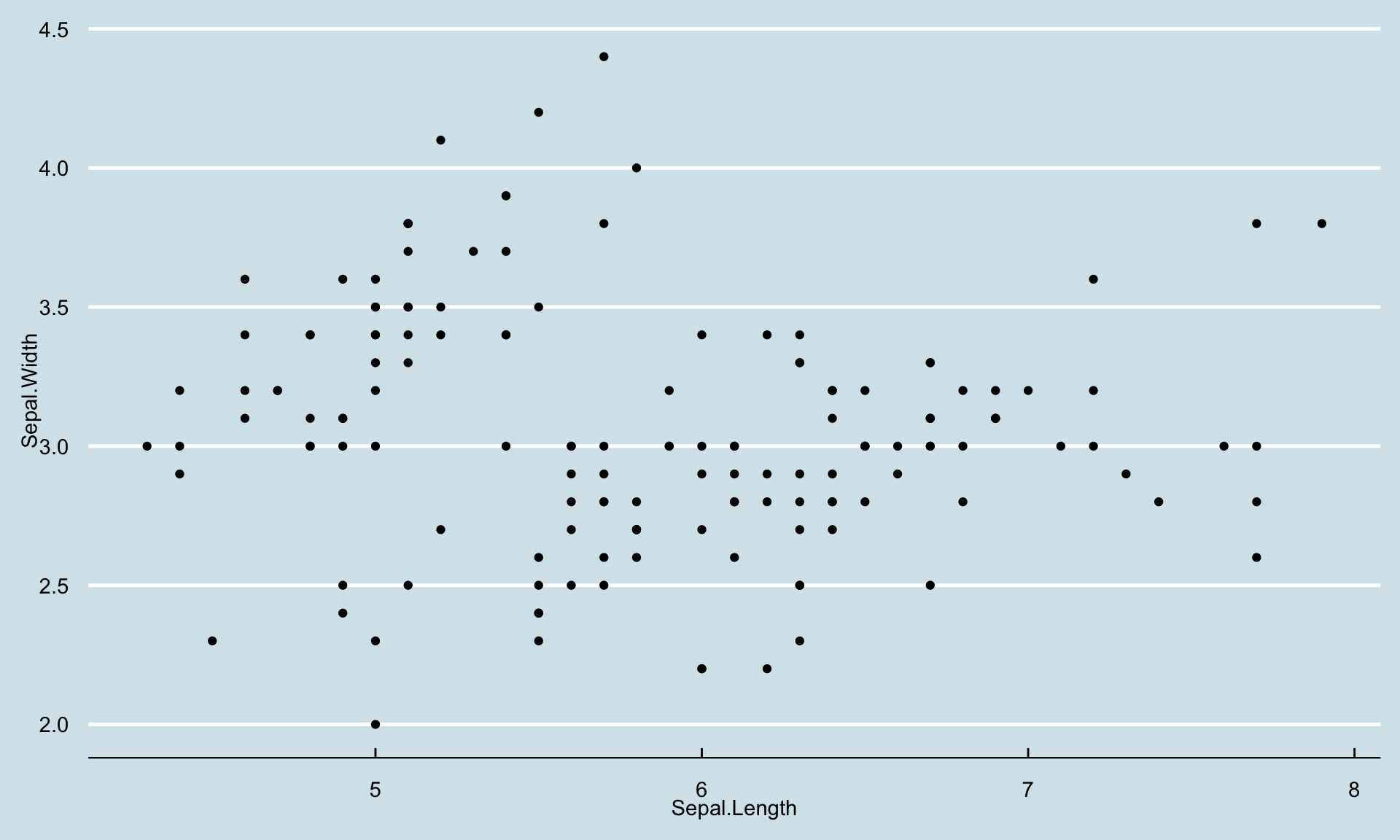
ggplot (iris) + aes (x = Sepal.Length, y = Sepal.Width) + geom_point () + theme_economist ()
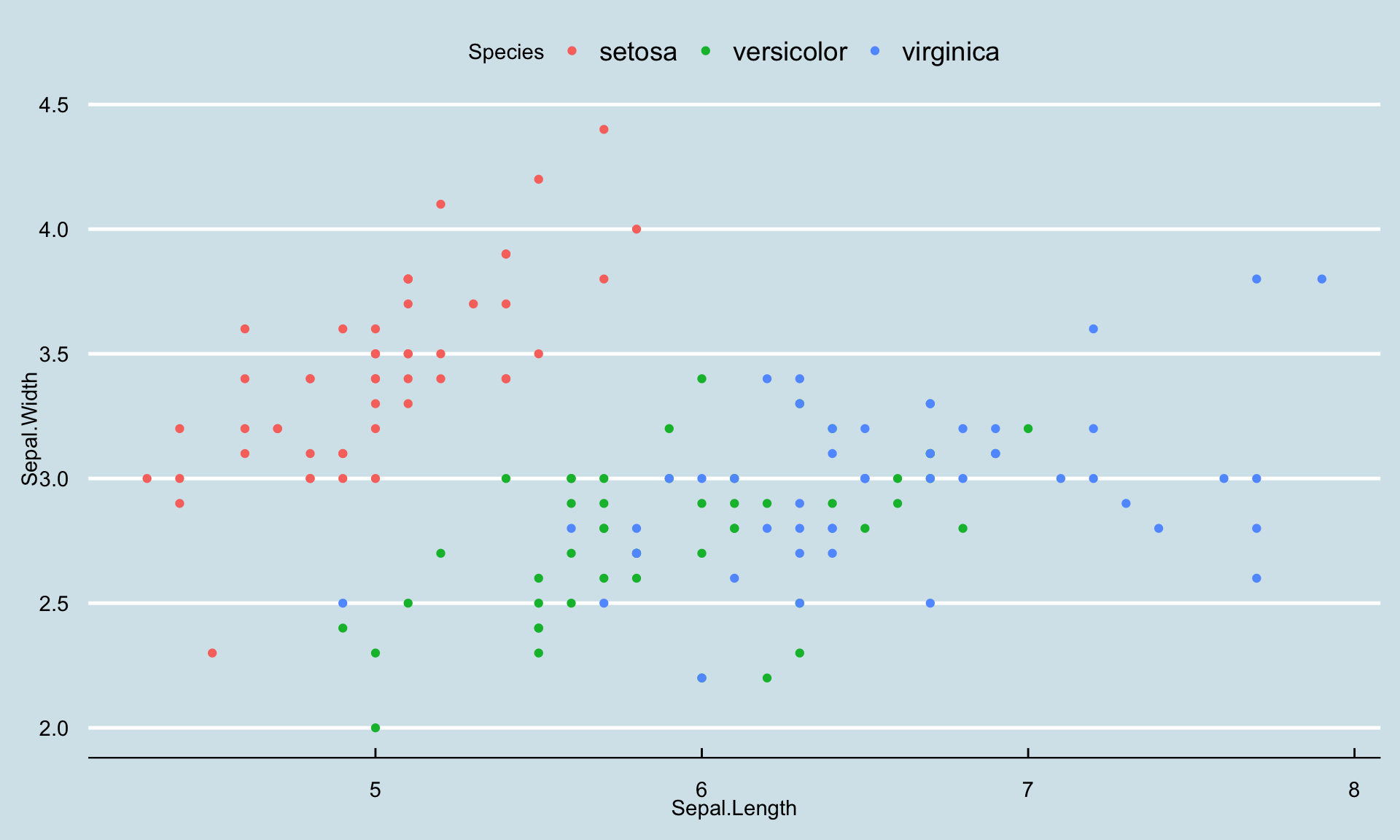
カテゴリーを表す変数をgroupとcolourで指定すると、カテゴリーごとにグループ化して、色分けもしてくれます。ここでは花の種類を表す変数であるSpeciesごとに色分けしてみます。
<- ggplot (iris) + # データセットirisを指定 aes (x = Sepal.Length, # x軸 花びらの幅 y = Sepal.Width, # y軸 花びらの幅 color = Species # あやめの種類ごとに色分け + geom_point () + # 散布図を指定 theme_economist () # テーマをEconomistに print (g)
操作できるグラフも作れます。 plotlyパッケージを使えば簡単です。
library (plotly)ggplotly (g)
3. レポート・論文が作れる。
データを分析した結果を表や図としてレポートや論文に載せる場合、MS Excelで作成した図や表を、MS Wordにコピペしてませんか? その場合、Wordで書いてたレポートの図表に少し修正を加えることになると、またExcelを開いて修正し、またコピペしたりしてませんか? これはミスの元ですし、レポートを2週間後に読んだとして、その図表を作成したExcelがどこにあるのか、またどうやって作ったのか思い出せますか? Rなら心配いりません。
Quarto やRmarkdown を使ってMarkdownでレポートを書けば、文章作成と図表を同じ場所で作成できます。 ちなみに、このウェブサイトもQuarto を使って作成し、GitHubでウェブサイト公開してます。 さらにプレゼン資料
例えば、先ほどから使っているirisデータで、
「あやめ」の種類ごとに、
花びらの長さと幅の平均、中央値、標準偏差を計算し、
それを表にする,
という処理を行いたいとしましょう。 簡単です。Rならね。
%>% :: group_by (Species) %>% # あやめの種類ごとに :: summarise ( # 以下の統計量を計算 = mean (Sepal.Length),= mean (Sepal.Width),= sd (Sepal.Width)%>% :: kable (booktabs = TRUE )
setosa
5.006
3.428
0.3790644
versicolor
5.936
2.770
0.3137983
virginica
6.588
2.974
0.3224966
たとえば、あやめのがく片の長さが長いほど、花びらが長くなるかどうかを分析しようと回帰分析を行いたいとします。 つまり以下のような回帰モデルを考えます(数式もこんなにキレイに書けます)。
Sepal.Length = \alpha + \beta \times Petal.Length + \varepsilon
この回帰モデルを最小二乗法(Ordinary Least Square Methos)で推定した結果を表にするときも次のように書けばできます。
library (gtsummary)<- lm (Sepal.Length ~ Petal.Length, data = iris)# tbl_regression(lm_fit, # type = "html", # title = "回帰分析の結果", # exponentiate = FALSE, # digits = list(all_continuous() ~ 2), # add_estimate_to_reference_rows = TRUE, # bold_p = TRUE)
他にもこんな感じにできます。
library (kableExtra)library (broom)%>% tidy () %>% kable (caption = "Regression Results" ,booktabs = TRUE ,digits = c (2 , 2 , 2 , 2 )) %>% kable_styling (full_width = FALSE ) %>% column_spec (1 , bold = TRUE ) %>% row_spec (0 , bold = TRUE , color = "white" , background = "#0073C2" )
Regression Results
(Intercept)
4.31
0.08
54.94
0
Petal.Length
0.41
0.02
21.65
0
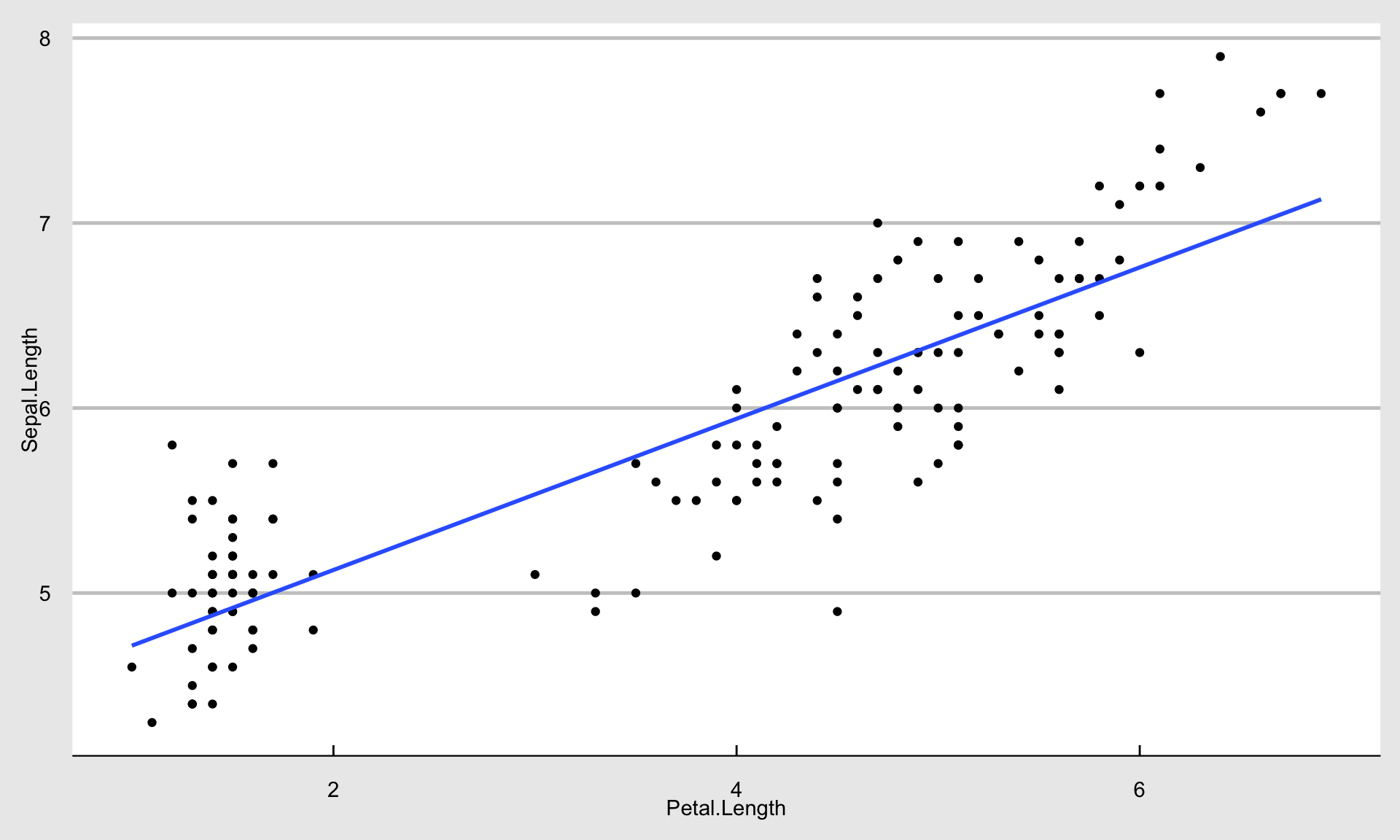
あやめのがく片の長さと花びらが長さをグラフにし,そこに上で求めた回帰直線を引いてみます。
ggplot (iris, aes (x = Petal.Length, y = Sepal.Length)) + geom_point () + geom_smooth (method = "lm" , se = FALSE ) + theme_economist_white ()
上記の結果から,がく片が1センチ長くなると,花びらの長さが約4.1ミリ長くなることがわかります。 このように、Rを使えば、データの操作から分析、結果の表や図の作成まで、一連の作業を一カ所で行うことができます。