# install.packages("keras") # install keras packages
pacman::p_load(keras, tidyverse, knitr, kableExtra)
# install_keras() # Run this only once. Installation takes time.外国書購読 Day4
Risk Assessment and Planning
Soichi Matsuura
2024-10-23
Machine Learning Methods
- Over the past decade, very useful extensions to twentieth century statistical models have been provided by advances in machine learning, and in particular deep-learning.
- Inference is a decision \delta (estimation, prediction) based on data x \in X that hopefully contains information about a particular set of constructs.
- Inference may be about:
- Classification — e.g., identifying faces, threats.
- Estimation — e.g., a vector \theta = \{\theta_1, \dots , \theta_n\}.
- Other decisions that may or may not be carried out in real time; e.g., driving a car.
Goals of Machine Learning
- The implicit goal of machine learning is construction of decision strategies that minimize risk.
- Risk is an informal concept inherited from gambling, and roughly implies the expected loss from using a given decision strategy \delta.
- Frequentist and Bayesian statisticians both base their decision strategies on real-world data, but sharply divided on the actual implementation and interpretation of decision risk.
Risk and AI
- In practice, risk presents deep learning (and AI in general) with its greatest challenges.
- For example, self-driving cars are trained on massive datasets extracted from many other cars; that knowledge of how to drive is encapsulated in weights in a network model that is firm-wired into a computer unit in a car.
- It matters whether that unit was trained to save pedestrians, or to save property, or to save the driver - each implies a different decision risk.
- Traditionally, statistics have used a squared-error loss function l(\theta, \delta (X)) = \mathrm{E}_{\delta} [\delta (X) - \theta )^2] where \delta(X) = \hat{\theta} in the case of estimation.
- But most real-world decisions are not optimally made with squared-error loss functions.
- Although squared-error loss is still widely used, machine learning practitioners will also use more complex, sometimes asymmetric loss functions that more closely fit the real-world problems.
- Business situations prefer asymmetric loss that penalizes costs and rewards revenues.
Search Algorithms
- Whereas traditional statistics relies heavily on first-order conditions from calculus, deep learning uses compute-intensive search algorithms that explore the response surface of the risk function.
- The following example presents the “Hello World” of machine learning: recognizing handwritten numbers on the National Institute of Standards dataset.
keras
Examples below assume that Tensorflow is installed. See https://www.tensorflow.org/install/。
[1] "list"List of 2
$ train:List of 2
..$ x: int [1:60000, 1:28, 1:28] 0 0 0 0 0 0 0 0 0 0 ...
..$ y: int [1:60000(1d)] 5 0 4 1 9 2 1 3 1 4 ...
$ test :List of 2
..$ x: int [1:10000, 1:28, 1:28] 0 0 0 0 0 0 0 0 0 0 ...
..$ y: int [1:10000(1d)] 7 2 1 0 4 1 4 9 5 9 ...The MNIST database was constructed from NIST’s Special Database 3 and Special Database 1 which contain binary images of handwritten digits.
Construct a neural network model. Keras Model composed of a linear stack of layers.
network <- keras_model_sequential() # null model
network |>
# 28*28 pixel images are flattened into 784 pixel vectors
layer_dense(units = 512, input_shape = c(28 * 28)) |>
# ReLU activation function converts negative values to zero
layer_activation('relu') |> # ReLU activation function
layer_dense(units = 10) |> # 10 output layers 1:10
# softmax activation function convert the output to a probability distribution
layer_activation("softmax") # softmax activation functionSpecify the algorithm and function series.
Training and Test Data
# Training data
train_images <- array_reshape( # 行列に変換
train_images, # 訓練用画像データ
c(60000, 28 * 28) # 画像の形状
)
# Test data
test_images <- array_reshape( # 行列に変換
test_images, # テスト用画像データ
c(10000, 28 * 28) # 画像の形状
)
# 0が黒,255が白のデータを0-1の範囲に正規化
train_images <- train_images / 255
test_images <- test_images / 255Label data is one hot encoded.
to_categolical()takes a vector or 1 column matrix of class labels and converts it into a matrix with p columns, one for each category.(補足) 0〜9の手書き文字の大小関係は今回関係ないため,10個のカテゴリーを意味する10列の行列に変換してます。
Training the Model
history <- network |>
fit( # training the model
train_images, # training image data
train_labels, # training label data
epochs = 10, # the number of times the model will be trained
batch_size = 128) # the number of samples per gradient updateEpoch 1/10
469/469 - 1s - loss: 0.2562 - accuracy: 0.9265 - 1s/epoch - 2ms/step
Epoch 2/10
469/469 - 1s - loss: 0.1040 - accuracy: 0.9697 - 799ms/epoch - 2ms/step
Epoch 3/10
469/469 - 1s - loss: 0.0683 - accuracy: 0.9794 - 795ms/epoch - 2ms/step
Epoch 4/10
469/469 - 1s - loss: 0.0496 - accuracy: 0.9854 - 789ms/epoch - 2ms/step
Epoch 5/10
469/469 - 1s - loss: 0.0375 - accuracy: 0.9890 - 792ms/epoch - 2ms/step
Epoch 6/10
469/469 - 1s - loss: 0.0283 - accuracy: 0.9915 - 795ms/epoch - 2ms/step
Epoch 7/10
469/469 - 1s - loss: 0.0210 - accuracy: 0.9938 - 787ms/epoch - 2ms/step
Epoch 8/10
469/469 - 1s - loss: 0.0168 - accuracy: 0.9952 - 785ms/epoch - 2ms/step
Epoch 9/10
469/469 - 1s - loss: 0.0127 - accuracy: 0.9963 - 783ms/epoch - 2ms/step
Epoch 10/10
469/469 - 1s - loss: 0.0098 - accuracy: 0.9970 - 784ms/epoch - 2ms/stepPlot
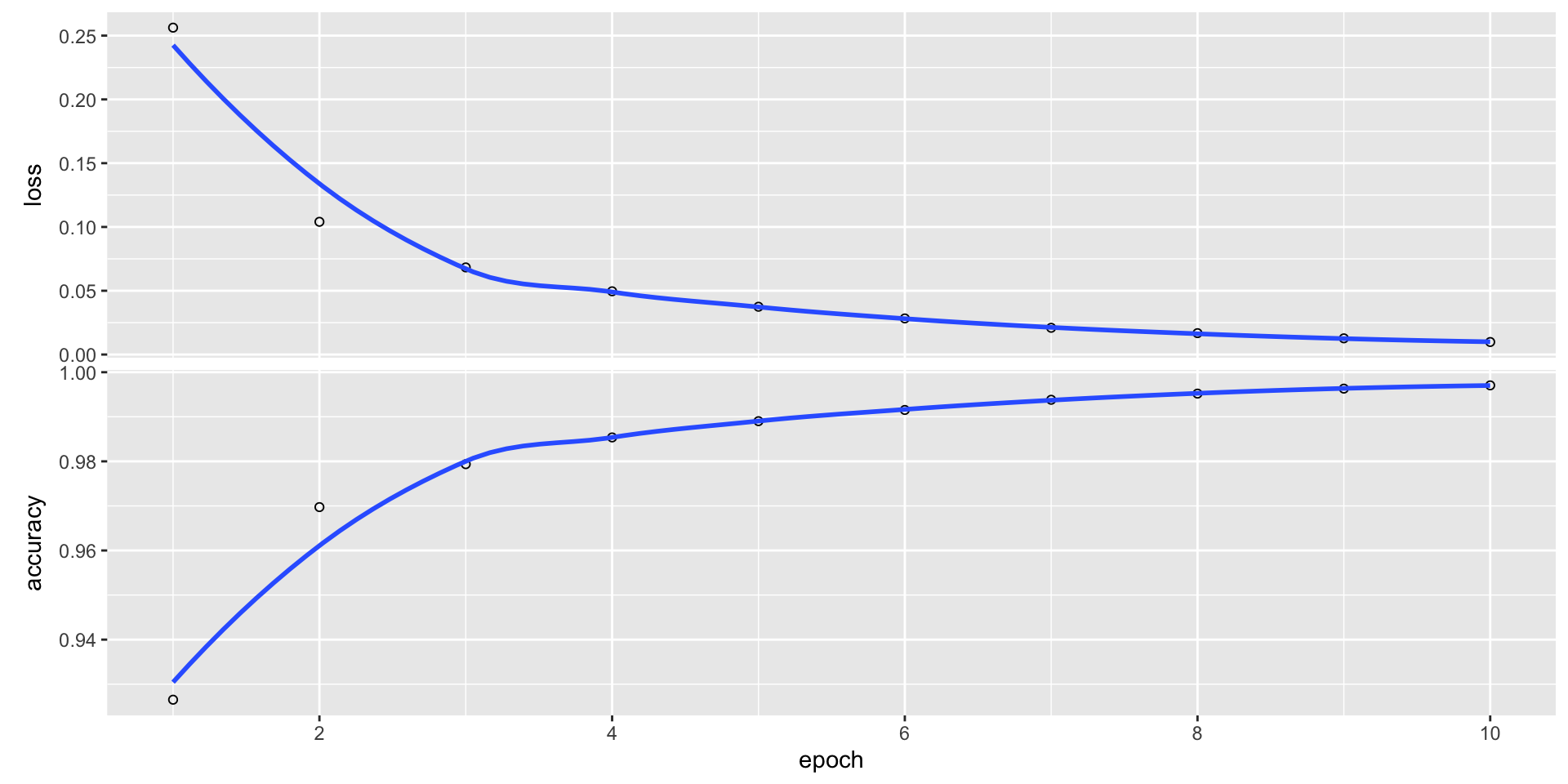
model evaluation
keras model
This particular Keras model overfits the MNIST data, with a final accuracy of 98% and loss of 7%.
Machine learning is a vast and rapidly evolving field.
It is increasingly for the analysis of social network and other text based intelligence required for the analytical review portion (and other parts) of the audit.
In the future, expect its role in auditing to expand, as suitable models are developed in the field.
Statistical Perspectives on Audit Evidence and its Information Content
補足
パラメータが\thetaである母集団の従う分布の確率密度関数をf(x \mid \theta)とする。 そのとき,尤度関数と対数尤度関数は、
L (\theta) = f(x \mid \theta), \quad l (\theta) = \log L(\theta)
となり,スコア関数は次式で定義される。
\frac{\partial}{\partial \theta} \log l (\theta)
Support and the Additivity of Evidence: The Log-Likelihood
- The log-likelihood has an intuitive interpretation, as suggested by the term “support.”
- Given independent events, the overall log-likelihood is the sum of the log-likelihoods of the individual events, just as the overall log-probability is the sum of the log-probability of the individual events.
- Viewing data as evidence, this is interpreted as “support from independent evidence adds,” and the log-likelihood is the “weight of evidence.”
The “Score”
- In statistics, the score (or informant) is the gradient of the log-likelihood function with respect to the parameter vector.
- Evaluated at a particular point, the score indicates the steepness of the log-likelihood function and thereby the sensitivity to infinitesimal changes to the parameter values.
- Since the score is a function of the observations that are subject to sampling error, it lends itself to a test statistic known as score test in which the parameter is held at a particular value.
Fisher Information
- In mathematical statistics, the Fisher information is a way of measuring the amount of information that an observable random variable X carries about an unknown parameter \theta of a distribution that models X.
- Formally, it is the variance of the score, or the expected value of the observed information.
- The Fisher information is a way of measuring the amount of information that an observable random variable X carries about an unknown parameter \theta upon which the probability of X depends.
Risk Assessment and Audit Planning
Auditing
Auditing
- Auditing of financial accounts is the process of verifying that economic events in the real world are accurately summarized in the financial statements of a legal entity.
- An audit opinion, the product of such auditing provides:
- Reasonable assurance.
- By an independent third party.
- Financial statements are presented fairly in all material respects.
- In accordance to some financial reporting framework, e.g., GAAP.
- Applied consistently so that year-to-year trends and comparisons are possible.
- In the USA, the auditing framework is dictated by generally accepted accounting principles (GAAP) and generally accepted auditing standards (GAAS).
- Internationally the International Standards on Auditing (ISA) issued by the International Auditing and Assurance Standards Board (IAASB) is considered as the benchmark for audit process.
- Under US generally accepted accounting principles (GAAP) auditors must release one of three types of opinions of the overall financial statements:
- An unqualified auditor’s opinion is the opinion that the financial statements are presented fairly.
- A qualified opinion is that the financial statements are presented fairly in all material respects in accordance with GAAP:
- Except for a material misstatement that does not pervasively affect the users ability to rely on the financial statements.
- Or with a scope limitation that is of limited significance.
- An adverse audit opinion is issued when the financial statements do not present fairly due to departure from US GAAP with an explanation of the nature and size of the misstatement.
- Additionally an auditor can issue a disclaimer which is considered a type of qualified opinion because there is insufficient and appropriate evidence to form an opinion or because of lack of independence.
- Unqualified (Clean) Opinion : We believe these financial statements are (1) fairly presented in (2) accordance with GAAP (3) consistently applied.
- Qualified Opinion : We believe these financial statements are (1) fairly presented in (2) accordance with GAAP (3) consistently applied; except for (4) A List of Exceptions.
- Adverse Opinion: We DO NOT believe these financial statements are (1) fairly presented in (2) accordance with GAAP (3) consistently applied; THE AUDITORS DISAGREE WITH A List of Exceptions.
Risk Assessment in Audit Planning
Risk Assessment
- Risk assessment in auditing is the determination of quantitative value of risk of a particular subset of accounting operations related to the rendering of the audit opinion - i.e., on whether the accounts have material error when GAAP has been consistently applied.
- Quantitative risk assessment requires calculations of two components of risk — the magnitude of the potential loss, and the probability that the loss will occur.
- An accounting cycle begins when accounting personnel create a transaction from a source document and ends with the completion of the financial reports and closing of temporary accounts in preparation for a new cycle.
5 Accounting Cycles
The five accounting cycles are: 1. Revenue cycle. 2. Expenditure cycle (this cycle focuses on two separate resources: inventory and human resources and often considers two separate cycles: purchasing and payroll/HR ). 3. Conversion cycle (Production cycle). 4. Financing (Capital Acquisition and repayment). 5. Fixed assets.
Problems in any transaction generated in these cycles are the sources of “loss” considered in the Risk Assessment Matrix (RAM).
Risk assessment consists of subjective and objective evaluations of risk in which assumptions and uncertainties are clearly considered and presented.
Part of the difficulty in risk management is that measurement of both potential loss and probability of occurrence is error prone and subjective.
Risk with a large potential loss and a low probability of occurring is often treated differently from one with a low potential loss and a high likelihood of occurring.
- In theory, both are of nearly equal priority, but in practice it can be very difficult to manage when faced with the scarcity of resources, especially time, in which to conduct the risk management process.
- This is one conundrum engendered by auditing’s inherently “wicked” character.
- A Risk Assessment Matrix (RAM) is a calculation spreadsheet that is used in risk assessment to define, estimate, argue, and support particular risks involved in decision-making.
- In auditing, the objective of the RAM is to construct a set of audit tasks that cost-effectively assures that the eventual audit decision will be correct with a particular level of confidence.
- Different statistical philosophies dictate the particular mathematical approach which is applied in the RAM.
- We will briefly review the alternatives here, with the goal of describing a simple, somewhat objective approach appropriate for the initial stages of auditing planning.
- Mathematicians recognize three broad approaches to risk calculations for decision-making: (1) the Neyman–Pearson hypothesis testing framework; (2) the Minimax game theoretic framework; and (3) Bayes Risk.
- This chapter proposes a simplified Bayes Risk as most appropriate for early planning of audits.
- The Neyman–Pearson lemma allows performing a hypothesis test between two simple hypotheses using a likelihood-ratio test, and provides a method of statistical inference from evidence.
- In statistics, a result is called statistically significant if it has been predicted as unlikely to have occurred by chance alone, according to a pre-determined threshold probability, the significance level.
- The phrase “test of significance” was coined by statistician Ronald Fisher, and plays an important part in our substantive tests of account balances and material error.
- Statistical hypothesis testing is sometimes called confirmatory data analysis, in contrast to exploratory data analysis, which may not have pre-specified hypotheses.
- Statistical hypothesis tests define a procedure that controls (fixes) the probability of incorrectly deciding that a default position (null hypothesis) is incorrect based on how likely it would be for a set of observations to occur if the null hypothesis were true.
- Note that this probability of making an incorrect decision is not the probability that the null hypothesis is true, nor whether any specific alternative hypothesis is true.
- This contrasts with other possible techniques of decision theory in which the null and alternative hypothesis are treated on a more equal basis.
Minimax and Bayes Risk
- Minimax is a decision rule published in 1928 by John von Neumann and is used in decision theory, game theory, statistics, and philosophy for minimizing the possible loss for a worst case (maximum loss) scenario.
- Bayes risk is the expected value of a loss function.
- It is typically optimized when a Bayes estimator decision rule is designed to minimize the posterior expected loss.
- The most common risk function used for Bayesian estimation is the mean square error (MSE), or squared-error risk \mathrm{E}X[\theta (X) - \theta )] for parameter \theta.
- For audits performed by an outside audit firm, risk assessment is a very crucial stage before accepting an audit engagement.
- It is an integral part of determining the audit tasks that will be performed in the audit program.
- According to ISA315 “the auditor should perform risk assessment procedures to obtain an understanding of the entity and its environment, including its internal control.”
- The auditor obtains initial evidence regarding the classes of transactions at the client and the operating effectiveness of the client’s internal controls.
- In auditing standards, audit risk is stated to include inherent risk (IR) control risk (CR) and detection risk (DR)
Audit Risk Model
The audit risk model expresses the risk of an auditor providing an inappropriate opinion of a commercial entity’s financial statements and is calculated:
AR = IR \times CR \times DR
- AR is the Audit Risk.
- IR is the Inherent Risk.
- CR is the Control Risk.
- DR is the Detection Risk.
- In this formula, IR refers to the risk involved in the nature of business or transaction.
- CR refers to the risk that a misstatement could occur but may not be detected and corrected or prevented by entity’s internal control mechanism.
- DR is the probability that the audit procedures may fail to detect existence of a material error or fraud.
- While CR depends on the strength or weakness of the internal control procedures, DR is either due to sampling error or human factors.
- This formula is an extreme simplification of the occurrence of loss in the real world, and is only suitable for the early, exploratory stages of planning an audit. There are several problems with the simplified formula:
- Poor Resolution. Typical risk matrices can correctly and unambiguously compare only a small fraction of randomly selected pairs of hazards.
- Errors. Risk matrices can mistakenly assign higher qualitative ratings to quantitatively smaller risks.
- Suboptimal Resource Allocation. Effective allocation of resources to risk-reducing countermeasures cannot be based on the categories provided by risk matrices.
- Ambiguous Inputs and Outputs. Categorizations of severity cannot be made objectively for uncertain consequences. Inputs to risk matrices and resulting outputs require subjective interpretation, and different users may obtain opposite ratings of the same quantitative risks.
Accessing the SEC’s EDGAR Database of Financial Information
- One of the first steps in planning an analytical review is a review of current and prior year filings with the SEC.
- These will include annual and quarterly financial statements, restatements, proxy statements, lawsuits, and numerous other documents, where their acquisition and incorporation into workpapers is an essential prerequisite of audit planning.
- Fortunately, complete information is available on the SEC’s website at sec.gov.
- Many of the most relevant documents to an audit are maintained by the SEC in XBRL format (as .XML files) which can be downloaded into the working papers from the Internet.
XBRL
- XBRL is eXtensible Business Reporting Language, a freely available, global markup language for exchanging business information.
- XBRL allows the expression of semantic meaning, which lends to an unambiguous definition of accounts and other financial information.
- XBRL representations of financial reports are more reliable and less subject to misinterpretation than any disseminations in other formats.
- XBRL also allows for automated parsing of information, which can greatly improve the efficiency of audit ratio and statistical analysis.
- The following code chunk accesses the SEC’s XBRL databases to acquire current and prior year filings for any listed company, and read it as a dataset that can be manipulated by R.
- For this example, we extract General Motors’ 2016 and 2017 financials from the EDGAR database at sec.gov. I use the finstr package to access EDGAR files 1 .
finstr package
コード
pacman::p_load(finstr, XBRL, xbrlus, pander, knitr, kableExtra)
old_o <- options(stringsAsFactors = FALSE) # 文字列をファクターとして扱わない
xbrl_data_2016 <- xbrlDoAll("XBRL/gm-20161231.xml")
xbrl_data_2017 <- xbrlDoAll("XBRL/gm-20171231.xml")
options(old_o) # 文字列をファクターとして扱う
st2016 <- xbrl_get_statements(xbrl_data_2016)
st2017 <- xbrl_get_statements(xbrl_data_2017)
print(st2017) # 2017年度の財務諸表Financial statements repository
From To Rows Columns
ConsolidatedBalanceSheets 2016-12-31 2017-12-31 2 44
ConsolidatedIncomeStatements 2015-12-31 2017-12-31 3 29
ConsolidatedStatementsOfCashFlows 2015-12-31 2017-12-31 3 42
ConsolidatedStatementsOfComprehensiveIncome 2015-12-31 2017-12-31 3 11Get the financial statements
コード
# 連結貸借対照表を取得
balance_sheet2017 <- st2017$ConsolidatedBalanceSheets
balance_sheet2016 <- st2016$ConsolidatedBalanceSheets
# 連結損益計算書
income2017 <- st2017$ConsolidatedIncomeStatements
income2016 <- st2016$ConsolidatedIncomeStatements
## 貸借対照表を出力
capture.output(
bs_table <- print( # 出力
balance_sheet2017, # オブジェクト名
html = FALSE, # html出力しない
big.mark = ",", # 3桁区切りにカンマを使用
dateFormat = "%Y"), # 日付のフォーマット
file= "NUL") # 出力先をNULにする
bs_table |>
head(10) |> # 先頭10行を表示
kable(
longtable = T, # ページまたぎ
caption = "Balance Sheet", # タイトル
booktabs = T
) |>
kable_styling(
bootstrap_options = c("striped", "hover", "condensed"),
full_width = F,
font_siz = 18
)| Element | 2017-12-31 | 2016-12-31 |
|---|---|---|
| Assets = | 212482 | 221690 |
| + AssetsCurrent = | 68744 | 76203 |
| + CashAndCashEquivalentsAtCarryingValue | 15512 | 12574 |
| + MarketableSecuritiesCurrent | 8313 | 11841 |
| + AccountsNotesAndLoansReceivableNetCurrent | 8164 | 8700 |
| + InventoryNet | 10663 | 11040 |
| + gm_AssetsSubjecttoorAvailableforOperatingLeaseNetCurrent | 1106 | 1110 |
| + OtherAssetsCurrent | 4465 | 3633 |
| + AssetsOfDisposalGroupIncludingDiscontinuedOperationCurrent | 0 | 11178 |
| + NotesAndLoansReceivableNetCurrent | 0 | 0 |
- Planning review looks for changes from prior years, or trends that may be important in the current year’s audit.
- The
merge()command consolidates the information from different .XML files into single files (Table 2).
コード
balance_sheet <- merge(balance_sheet2017, balance_sheet2016)
capture.output(
bs_table <- print(
balance_sheet,
html = FALSE,
big.mark = ",",
dateFormat = "%Y"
),
file = "NUL"
)
bs_table |>
head(10) |>
kable(
longtable = T,
caption="Merged Balance Sheet",
# "latex",
booktabs = T) |>
kable_styling(
bootstrap_options = c("striped", "hover", "condensed"),
full_width = F,
font_size = 18
)| Element | 2017-12-31 | 2016-12-31 | 2015-12-31 |
|---|---|---|---|
| Assets = | 212482 | 221690 | 194338 |
| + AssetsCurrent = | 68744 | 76203 | 69408 |
| + CashAndCashEquivalentsAtCarryingValue | 15512 | 12960 | 15238 |
| + MarketableSecuritiesCurrent | 8313 | 11841 | 8163 |
| + AccountsNotesAndLoansReceivableNetCurrent | 8164 | 9638 | 8337 |
| + InventoryNet | 10663 | 13788 | 13764 |
| + gm_AssetsSubjecttoorAvailableforOperatingLeaseNetCurrent | 1106 | 1896 | 2783 |
| + OtherAssetsCurrent | 4465 | 4015 | 3072 |
| + AssetsOfDisposalGroupIncludingDiscontinuedOperationCurrent | 0 | 0 | 0 |
| + NotesAndLoansReceivableNetCurrent | 0 | 0 | 0 |
The check_statement() command in finstr will automatically validate internal consistency of transaction lines and summary lines in the EDGAR filings.
Number of errors: 8
Number of elements in errors: 4
Element: AssetsCurrent = + CashAndCashEquivalentsAtCarryingValue + MarketableSecuritiesCurrent + AccountsNotesAndLoansReceivableNetCurrent + InventoryNet + gm_AssetsSubjecttoorAvailableforOperatingLeaseNetCurrent + OtherAssetsCurrent + AssetsOfDisposalGroupIncludingDiscontinuedOperationCurrent + NotesAndLoansReceivableNetCurrent
date original calculated error
3 2016-12-31 7.6203e+10 7.1116e+10 5.087e+09
4 2017-12-31 6.8744e+10 5.8886e+10 9.858e+09
Element: AssetsNoncurrent = + EquityMethodInvestments + PropertyPlantAndEquipmentNet + IntangibleAssetsNetIncludingGoodwill + DeferredIncomeTaxAssetsNet + OtherAssetsNoncurrent + DisposalGroupIncludingDiscontinuedOperationAssetsNoncurrent + NotesAndLoansReceivableNetNoncurrent + PropertySubjectToOrAvailableForOperatingLeaseNet
date original calculated error
5 2016-12-31 1.45487e+11 1.28486e+11 1.7001e+10
6 2017-12-31 1.43738e+11 1.22530e+11 2.1208e+10
Element: LiabilitiesCurrent = + AccountsPayableCurrent + AccruedLiabilitiesCurrent + LiabilitiesOfDisposalGroupIncludingDiscontinuedOperationCurrent + DebtCurrent
date original calculated error
11 2016-12-31 8.5181e+10 6.1384e+10 2.3797e+10
12 2017-12-31 7.6890e+10 4.9925e+10 2.6965e+10
Element: LiabilitiesNoncurrent = + OtherPostretirementDefinedBenefitPlanLiabilitiesNoncurrent + DefinedBenefitPensionPlanLiabilitiesNoncurrent + OtherLiabilitiesNoncurrent + LiabilitiesOfDisposalGroupIncludingDiscontinuedOperationNoncurrent + LongTermDebtAndCapitalLeaseObligations
date original calculated error
13 2016-12-31 9.2434e+10 4.1108e+10 5.1326e+10
14 2017-12-31 9.9392e+10 3.2138e+10 6.7254e+10Rearranging the Statement
Rearranging statements is often a useful step before actual calculations. Rearrangements can offer several advantages in ad hoc analyses such as analytical review:
- We can avoid errors in formulas with many variables,
- Accounting taxonomies do change and using many formulas on original statement is harder to support than using custom hierarchy for analysis starting point,
- When sharing analyses it is easier to print fewer values.
expose() function
To rearrange the statement to simple two-level hierarchy use the expose function.
expose(balance_sheet,
# Assets
"Current Assets" = "AssetsCurrent",
"Noncurrent Assets" = other("Assets"),
# Liabilites and equity
"Current Liabilities" = "LiabilitiesCurrent",
"Noncurrent Liabilities" = other(c("Liabilities", "CommitmentsAndContingencies")),
"Stockholders Equity" = "StockholdersEquity"
)expose() function
Financial statement: 3 observations from 2015-12-31 to 2017-12-31
Element 2017-12-31 2016-12-31 2015-12-31
Assets = 212482 221690 194338
+ Current.Assets 48223 54138 51357
+ Noncurrent.Assets 122530 90237 86258
LiabilitiesAndStockholdersEquity = 212482 221690 194338
+ Current.Liabilities 49925 56153 51655
+ Noncurrent.Liabilities 32138 36834 39249
+ Stockholders.Equity 35001 43836 39871
+ OtherLiabilitiesAndStockholdersEquity_ 1199 239 452 Here, the balance sheet stays divided by assets, liabilities, and equity. For the second level we are exposing current assets from noncurrent and similarly for the liabilities. We choose to separate equity.
Function
expose()expects a list of vectors with element names.Function
other()helps us identify elements without enumerating every single element.Using
other()reduces potential errors, as the function knows which elements are not specified and keeps the balance sheet complete.Sometimes it is easier to define a complement than a list of elements. In this case we can use the
%without%operator.Let us expose, for example, tangible and then intangible assets (Table 3):
expose( balance_sheet,
# Assets
"Tangible Assets" = "Assets" %without% c(
"AssetsOfDisposalGroupIncludingDiscontinuedOperationCurrent",
"NotesAndLoansReceivableNetCurrent",
"gm_AssetsSubjecttoorAvailableforOperatingLeaseNetCurrent"
),
"Intangible Assets" = other("Assets"),
# Liabilites and equity
"Liabilities" = c("Liabilities", "CommitmentsAndContingencies"),
"Stockholders Equity" = "StockholdersEquity"
)Financial statement: 3 observations from 2015-12-31 to 2017-12-31
Element 2017-12-31 2016-12-31 2015-12-31
Assets = 212482 221690 194338
+ Tangible.Assets 169647 142479 134832
+ Intangible.Assets 1106 1896 2783
LiabilitiesAndStockholdersEquity = 212482 221690 194338
+ Liabilities 82063 92987 90904
+ Stockholders.Equity 35001 43836 39871
+ OtherLiabilitiesAndStockholdersEquity_ 1199 239 452 diff_bs <- diff(balance_sheet)
capture.output(
bs_table <- print(
diff_bs,
html = FALSE,
big.mark = ",",
dateFormat = "%Y"
), file = "NUL")
bs_table |>
head(10) |>
kable(longtable = T,
caption = "Lagged Differences in Balance Sheets",
# "latex",
booktabs = T) |>
kable_styling(
bootstrap_options = c("striped", "hover", "condensed"),
full_width = F,
font_size = 18)| Element | 2017-12-31 | 2016-12-31 |
|---|---|---|
| Assets = | -9208 | 27352 |
| + AssetsCurrent = | -7459 | 6795 |
| + CashAndCashEquivalentsAtCarryingValue | 2552 | -2278 |
| + MarketableSecuritiesCurrent | -3528 | 3678 |
| + AccountsNotesAndLoansReceivableNetCurrent | -1474 | 1301 |
| + InventoryNet | -3125 | 24 |
| + gm_AssetsSubjecttoorAvailableforOperatingLeaseNetCurrent | -790 | -887 |
| + OtherAssetsCurrent | 450 | 943 |
| + AssetsOfDisposalGroupIncludingDiscontinuedOperationCurrent | 0 | 0 |
| + NotesAndLoansReceivableNetCurrent | 0 | 0 |
- These are the basic tools that you need to access the information on
sec.gov. - Note that there are numerous reports on EDGAR; finstr will be able to access and format any financial statements in XBRL format on the EDGAR database.
- Almost all of the EDGAR information is maintained in HTML format, and I will provide code later in this chapter to access and parse HTML files in EDGAR.
Caveats on accessing EDGAR with R
- One of the most useful functions that R and its packages offer auditors and accountants is the ability to quickly and directly access SEC filings with very simple R code.
- This comes with caveats, as EDGAR’s database formatting and naming conventions are not always stable, and can change without warning.
- Additionally, the R packages which support access to SEC databases are not always reliably maintained, and changes at the SEC may not be reflected in the code.
- When you run into problems using the EDGAR related code chunks in this chapter, it is advisable to visit https://www.sec.gov/edgar/ to look at the files in the SEC’s repositories, and see whether they conform to the expectations of R’s packages.
- The following are some problems and workarounds I have found in my own use of these packages.
- For example, an auditor might run into problems accessing Tesla’s data in XML format, during a time that the SEC seems to have changed naming conventions.
- Access of Tesla data up to 2018 works properly, as shown in the following code chunk.
# install.packages("finreportr")
library(finreportr)
# The following commands will directly load
# EDGAR information into the R workspace for analysis tesla_co <- CompanyInfo("TSLA")
tesla_ann <- AnnualReports("TSLA")
tesla_ann
tesla_inc <- GetIncome("TSLA", 2018)
tesla_bs <- GetBalanceSheet("TSLA", 2018)
tesla_cf <- GetCashFlow("TSLA", 2018)
head(tesla_inc)But this code will not be able to access Tesla’s 2019 reports, because it throws an error:
What has happened: rather than asking for
tsla-20191231.xmlthe package should have asked fortsla-10k_20191231_htm.xml.EDGAR either made a mistake in their index files, or changed naming conventions.
You can explore this further by going to their website.
You can also use the
xml2package to read what is in the correct file, bypassingfinreportraltogether (or just wait for the repositories to be updated with corrected code).Consider this workaround to access 2019 data.
edgar package
- If you would rather avoid the challenge of working with XML altogether, there is another workaround.
- The EDGAR package allows you to download the 10-K in text or HTML in computer readable form on your computer.
NULLになりました。
Additionally, you may wish to look at stock prices, and this is easy to do with the tseries package.
Audit Staffing and Budgets
- The audit program lays out in advance of mid-year and year-end tests, the procedures that will be used to collect evidence and to analyze it with the objective of reporting the “correct” audit opinion, while keeping costs within the contracted audit budget.
- This section provides an example of an audit program that might be created after the risk assessment. In addition to auditing steps on samples drawn from specific computer files, the example demonstrates the sort of results that the audit would produce, and describes the corrective steps or reporting that would accompany the audit results.
- Audit budgeting, which primarily is determined by the allocation of audit staff, is too often made in an ad hoc manner.
- Prior years’ budgets and assignments influence staffing; so does availability of knowledgeable staff. Human resource problems, especially in specialized, knowledge intensive industries such as auditing, will never be an exact science.
- Nonetheless, management should attempt to instill a reasonable level of cost–benefit discipline in staffing decisions.
- At the planning stage, audit managers will determine the scope of each audit test. From a statistical perspective, this can be estimated as a cost proportional to the sample sizes that are decided on for the tests.
- From a staffing perspective, this is proportional to the number of auditors assigned to the audit tasks.
- Similarly, the benefit derived from that expenditure can be perceived in terms of the monetary error that could be detected; typically a percentage of the value of the account or years transaction stream.
- Audit programs are collections of audit tests that test different critical transaction and systems processing features in the client’s accounting systems.
- I assume that audit planning required for each of the individual audit tests is set to a scope which overall maximizes the audit risk reduction for a given cost of conducting the audit with this program.
- Staffing is “lumpy” in the sense that you typically get whole auditors assigned to an audit.
- The number of auditors assigned to an audit will be commensurate with their potential for detecting monetary error—the benefit received from an audit test.
Audit Staffing and Budgets
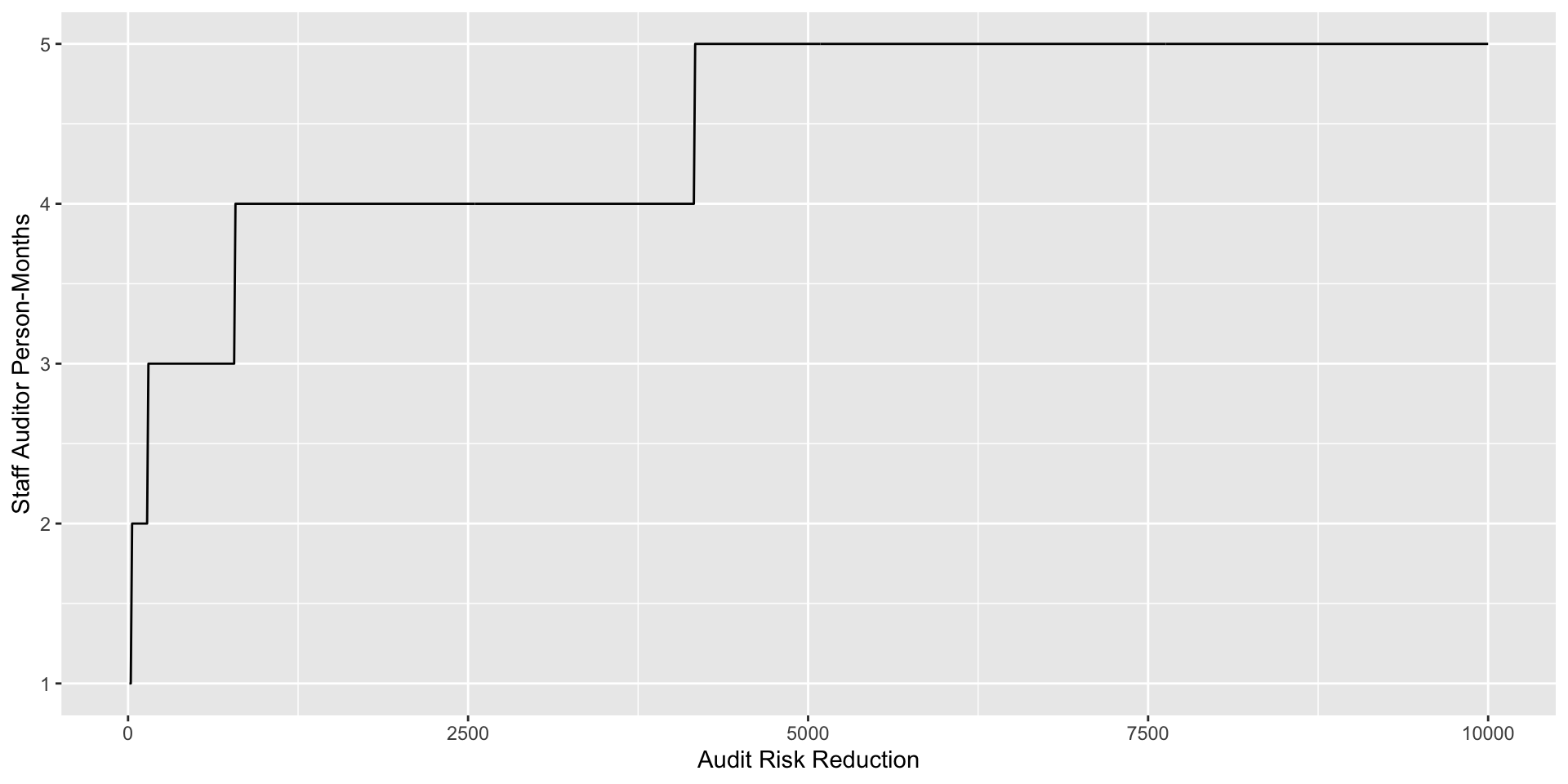
The Risk Assessment Matrix
- A Risk Assessment Matrix is constructed prior to and during the analytical review phase of the audit (see Fig. 2 for an example of a RAM dashboard).
- During this phase, the auditor will scan any business intelligence from media and Internet sources that would be relevant to potential risks to be encountered in the audit of the client. Prior years’ working papers will also be perused for ascertain experiences, client specific risks, and application of the “rule of 3’s” to adjust any anticipated risks and expectations during the current year audit.
- Audit firms tend to enforce firm specific procedures in auditing.
- Each of the “Big 4” audit firms displayed unique biases in rendering adverse attestations:
- Ernst and Young focused on accounts receivables, revenue recognition, taxes, and fixed assets;
- PricewaterhouseCoopers focused on accounts receivables, revenue recognition, taxes, and payables;
- KPMG focused on accounts receivables, revenue recognition, taxes, and inventory; and
- Deloitte and Touche focused on revenue recognition, taxes, liabilities, inventory, and executive compensation (Cheffers 2012).
- These biases are likely to reflect signature audit methods, internal forms and checklists, and audit histories that are unique to individual firms.
- These firms will consequently allocate larger portions of the audit budget to certain accounts at the expense of others.
- Additionally, auditors tend to allocate more time to auditing debit balance accounts, assuming double-entry will assure the accuracy of the credit accounts.
- The specific accounts selected for audit depend on firm policy, procedures, and managing partners.
- In this section, I will show how to construct a Risk Assessment Matrix on a client–server dashboard.
- Dashboards are well suited to auditing—they accommodate the information needs of auditors (and their laptops) in the field, while assuring the security, integrity, completeness, and privacy of client and audit records behind firewalls.
- The Risk Assessment Matrix will assume we are planning the audit of the simulated system presented in chapter “Simulated Transactions for Auditing Service Organizations” (Fig. 2).
Using Shiny to create a Risk Assessment Matrix Dashboard
RAM
- Auditors face a particular problem in the field, in that much of the information they need may be in prior years’ workpapers, in proprietary client files, in central locations in the audit firm and on powerful servers or cloud platforms.
- The standard solution to such problems is found in client–server systems that place secure systems on a centralized server, and provide the field auditor with light, client software that runs on a laptop, communicating with the server over the Internet.
Shinyis the client–server extension of the R, and as with the rest of the R, is uniquely suited to handling the ad hoc nature of audits, where each audit often represents an entirely new set of analyses.
Shiny App
Shinyis a tool for fast prototyping of digital dashboards, giving you a large number of HTML Widgets at your disposal which lend themselves really well to building general-purpose web applications.Shinyis particularly suited for fast prototyping and is fairly easy to use for someone who is not a programmer. Dashboards locally display some data (such as in a database or a file) providing a variety of metrics in an interactive way.
Create a RAM Dashboard
- Reactive programming starts with reactive values that change in response to user input and builds on top of them with reactive expressions that access reactive values and execute other reactive expressions.
- Reactivity based code for the Risk Assessment Matrix dashboard appears below.
- This has two parts:
- the user interface “ui” which conceivably would operate on the field auditor’s laptop, and
- the server-side “server” operations that would take place at the audit firms headquarters and with access to firm and client files.
Shiny App
# Define UI for application
library(shiny) # Load the shiny package
ui <- fluidPage(
titlePanel("Risk Assessment Matrix"),
sidebarLayout(
sidebarPanel(
# Input: 監査テストの統計的信頼水準
sliderInput("confidence", "Confidence:",
min = .7,
max = .999,
value = .95),
# Input: サンプル取引ごとの監査コスト
sliderInput("cost", "Audit $ / transaction:",
min = 0,
max = 500,
value = 100),
# Input: Text for providing a caption for the RAM
textInput(
inputId = "caption",
label = "クライアント:",
value = "XYZ Corp.")
),
# Main panel for displaying outputs
mainPanel(
# Output: slider values entered
tableOutput("values"),
# Output: Formatted text for caption
h3(textOutput("caption", container = span)),
# Output: total cost of the audit
textOutput("view"),
# Output: RAM summary with sample sizes (scope) and cost
verbatimTextOutput("summary"),
h6("リスク選択: 1 = 低, 2 = 中, 3 = 高"),
h6("リスク知能 = ビジネス・インテリジェンス・スキャンニングで示されるリスク水準"),
h6("前年度リスク = 前期に監査人が示したリスク水準"),
h6("Scope = estimated discovery sample size that will be needed in the audit of this account"),
h6("Audit cost = audit labor dollars per sampled transaction"),
h6("Confidence = statistical confidence"),
h6("Account Amount and the Ave. Transaction size are in $ without decimals or 000 dividers")
)
)
)- The mathematics of scope assessment takes place on the server.
- I used a very simple “discovery sampling” inspired model (see chapter “Design of Audit Programs”) to compute audit scope which I interpret as sample sizes for various transaction flows, computed as:
n \approx \frac{log(1-confidence)}{log(1-\frac{10-risk_{intelligence} \times risk_{prior}}{100})}
- These are dynamically (reactively in the Shiny vernacular) updated for changes in confidence level and transaction auditing costs established by the auditor.
- A total audit cost of field tests is computed, to be incorporated into the overall budget of the audit.
確率の補足
- この式は、二項分布に基づく発見サンプルサイズ (discovery sample size)」を計算するための公式で,二項分布とはあるイベントが n 回の試行の中で何回発生するかを表す確率分布
- 成功確率をpとしたとき、試行回数 n の中で少なくとも1回そのイベントが発生する確率を求める。
- サンプリングにおいて問題となるのは、「ある許容誤差率」以上のエラーが存在するかどうかを確認するために、どれだけのサンプルサイズを用意すればよいか、という点
- この場合、誤り率 p = 0.05 であり、これを発見するために必要なサンプルサイズ n を求めています。
少なくとも1つの誤りを見つける確率
あるサンプルサイズ n を持ち、誤り率が p = 0.05 であると仮定
誤りが1つも見つからない確率: 各サンプルで誤りが発生しない確率は1 - pで,nの全てにおいて誤りが1つも発生しない確率は(1 - p)^n
少なくとも1つの誤りが見つかる確率:
- 少なくとも1つの誤りが発生する確率は、1から「誤りが1つも見つからない確率」を引いたもの。1 - (1 - p)^n
信頼水準\text{confidence}: 「少なくとも1つの誤りを検出できる確率」が信頼水準\text{confidence}以上であるために必要なサンプルサイズnを計算 1 - (1 - p)^n = \text{confidence}
サンプルサイズnを求める
サンプルサイズnを解く。両辺から1を引いて整理して,対数をとる。 \begin{aligned} (1 - p)^n &= 1 - \text{confidence}\\ \log((1 - p)^n) &= \log(1 - \text{confidence})\\ n \log(1 - p) &= \log(1 - \text{confidence}) \end{aligned}
n を求めるために、両辺を \log(1 - p) で割ると, n = \frac{\log(1 - \text{confidence})}{\log(1 - p)}
許容誤差率p = 0.05と信頼水準\text{confidence} = 0.95を使うと次のようになる。 n = \frac{\log(1 - 0.95)}{\log(1 - 0.05)}
この計算結果は、発見サンプルサイズnを示しており、監査などにおいて設定された許容誤差率(5%)を 95% の確信で検出するために必要なサンプル数を表している。 この式は、二項分布に基づき「少なくとも1つの誤りを検出する確率が信頼水準\text{confidence}に達するために必要なサンプルサイズn」を計算するためのものです。
Shiny App (Server)
コード
server <- function(input, output) {
ram <- read.csv(system.file("extdata",
"risk_asst_matrix.csv",
package = "auditanalytics",
mustWork = TRUE)
)
sliderValues <- reactive({
data.frame(
Audit_Parameter = c("confidence", "cost"),
Value = as.character(c(input$confidence, input$cost)),
stringsAsFactors = FALSE)
})
output$values <- renderTable({
sliderValues()
})
output$caption <- renderText({
input$caption
})
output$summary <- renderPrint({
ram <- ram
conf <- input$confidence
cost <- input$cost
risk <- (10 - (as.numeric(ram[,2]) * as.numeric(ram[,3])) )/100
Scope <- ceiling( log(1-conf) / log( 1- risk))
ram <- cbind(ram[,1:5], Scope)
Min_cost <- Scope * cost
ram <- cbind(ram[,1:6], Min_cost)
ram
})
output$view <- renderText({ # 監査費用を表示
ram <- ram # リスク評価行列を読み込む
conf <- input$confidence # 監査の信頼度
cost <- input$cost # 監査費用
risk <- (10 - (as.numeric(ram[,2]) * as.numeric(ram[,3])) )/100 # リスク
Scope <- ceiling( log(1-conf) / log( 1- risk)) # 範囲
ram <- cbind(ram[,1:5], Scope) # リスク評価行列に範囲を追加
Min_cost <- Scope * cost # 最小監査費用を計算
minimum_audit_cost <- sum(Min_cost) # 最小監査費用を合計
c("Minimum estimated audit cost = ",minimum_audit_cost) # 最小監査費用を表示
})
}R Studio gives you various options for assembling Shiny apps, including apps with server side code resident on either an RStudio or a bespoke server, and stand-alone client side apps which can be constructed with the following code.
Generating the Audit Budget from the Risk Assessment Matrix
Audit Budgets
- The Risk Assessment Matrix (RAM) will generate qualitative measures of risk along with initial estimates of minimum (discovery) sample sizes.
- This will generally not be sufficient to accurately budget the audit, since higher risk accounts will require audit scope beyond mere “discovery” of errors.
In addition, planning will need to estimate costs associated with:
- Estimating the rates of errors from control weaknesses of all specific types (in interim tests),
- Assessing the existence and amount of errors in trial balance accounts (in substantive tests), and
- Generally assessing structural and qualitative problems in financial information consolidation and presentation.
- The third item is beyond the scope of simple technical metrics, and will require the experience and judgment of audit managers.
- It can probably best be estimated by reviewing prior years’ budgets and assuming similar costs for the current year audit.
- The first two items, though, can be budgeted through a relatively simple linear model with assumptions which reflects the cost structure of a particular audit firm.
- Though each RAM will be auditor and client specific, the prior interactive RAM software can easily be programmed to incorporate such a linear model.
Technical Sampling Structure of the Audit Program
- The technical tests of internal control (interim testing) and account balances (substantive testing) consist of audit work investigating the items in transaction samples.
- The unit of audit work is a sampled transaction, and each type of transaction will be subject to misaccounting through a variety of control weaknesses.
Example : salse transaciton
- A sale could be recorded at the wrong amount, or the wrong item sold could have been recorded, or the sale could have been shipped to the wrong customer, or be recorded in the wrong period.
- Each of these problems reflect a specific audit risk, control weakness, and audit procedure.
- Auditors’ concern with such errors differs in the interim and substantive tests.
- Where this rate suggests a control weakness is significant, the auditor needs to expand the scope of substantive auditing of account balances that are affected by the control weakness.
- Placing these considerations in a more formal mathematical setting, let T_{i,j} represent a particular control weakness j in transaction type i.
- Let S_{i,j} be the interim testing sample size suggested by the RAM to test for control weakness j in transaction type i.
- Let C_{i,j} be the audit cost to test for control weakness j in a single transaction of type i.
Then a simple linear cost model would be:
\text{total cost of technical interim test} = \sum _{i,j} S_{i,j} \times C_{i,j}
The matrix form is typically more useful in writing R language code, because the transaction, cost, and sample values are matrices that can directly use the fast BLAS/LAPACK implementations in R for linear algebra, rather than coding slow, messy, nested for statements. The matrix form is:
\text{total cost of technical interim test} = 1_{(i)}^{\top} \times \left (T \times S^{\top} \times C \right ) \times 1_{(j)}
where 1_{(i)}^{\top} is the row i-vector whose entries are all 1’s, 1_(j) is the column j-vector whose entries are all 1’s, T = \{T_{i,j} \}, S = \{ S_{i,j} \}, and C = \{ C_{i,j} \}.
Sample Sizes for Budgeting
There are two types of sampling in interim tests:
- Discovery sampling for discovery of out-of-control transaction streams
- Attribute sampling for estimating transaction error rate
Discovery sampling sets a sample size that is likely to discover at least one error in the sample if the actual transaction error rate exceeds the minimum acceptable error-rate (alternatively called the out-of-control* rate of error). Discovery tests helps the auditor decide whether the systems processing a particular transaction stream are in or out of control.
- Budgeted sample sizes in interim testing will depend on whether the RAM suggests that control risk is low or high.
- If it is low, then the discovery sample size plus a ‘security’ factor for cases where error is discovered will estimated the scope of auditing.
So for a 5% intolerable error rate at 95% confidence we have:
confidence <- 0.95
n <- (log(1 - confidence)) / log(1 - 0.05)
cat("\n Discovery sample size = ", ceiling(n))
Discovery sample size = 59Where the RAM assesses control risk to be anything higher, the auditor can assume that scope will be expanded to include attribute sampling.
- Attribute sampling estimates the error rate in the entire transaction population with some confidence (e.g., 95%) that the estimate is within the out-of-control error-rate cutoff for that transaction stream.
- If it is found that a particular transaction stream is out of control, then attribute estimation will help us decide on the actual error rate of the systems that process this transaction stream.
- If discovery sampling suggests that a particular transaction stream is out of control, then attribute estimation will help us decide on the actual error rate of the systems that process this transaction stream.
- Errors estimates from attribute samples may either be rates or amounts or both.
Attribute sampling size is determined using Cohen’s power analysis (Cohen 1992) which is implemented in R’s pwr package, We compute both in the following code chunk
コード
# install.packages("pwr") # first time only
library(pwr) # Cohen本のpower analysis
size <- 1000 # トランザクションの総数
Delta <- 0.05 * size # 5%の許容エラー率を検出する
sigma <- 0.3 * size # 変動(おそらく1/3)を推測する
effect <- Delta/sigma # 許容度÷変動
sample <- pwr.t.test( # pwr.t.test関数を使用
d = effect, sig.level = 0.05, power = 0.8,
type = "one.sample",
alternative = "greater" ## look for overstatement of earnings
)
cat("\n Attribute sample size for occurrence of error = ", ceiling(sample$n))
Attribute sample size for occurrence of error = 224Attribute sampling determines sample size to estimate the error amount in a transaction stream.
size <- 100000 ## total amount of transactions
mu <- 50 ## average value of transaction
Delta <- 0.05 * mu ## detect 5% amount intolerrable error
sigma <- 30 ## variability
effect <- Delta/sigma
sample <- pwr.t.test(
d = effect, sig.level = 0.05, power = 0.8,
type = "one.sample", alternative = "greater")
cat("\n Attribute sample size for amount of error = ", ceiling(sample$n))
Attribute sample size for amount of error = 892- The auditor faces different decisions in substantive testing.
- The particular type of account determines the impact of control weaknesses found in interim testing.
- For example, a 5% error rate in a $1 million sales account discovered in interim testing implies a $50,000 error in annual sales on the trial balance.
- Assume that accounts receivable turn over 10 times annually, then that 5% error rate implies only a $5000 misstatement in accounts receivable.
- Whether sales or accounts receivable are ‘fairly stated’ depends on the immateriality level set by the auditor – a $10,000 materiality level would imply that sales is not fairly presented, while accounts receivable is fairly stated.
- At year-end where there will be a complete set of transactions available for the year, and substantive samples are typically focused on acceptance sampling to determine of the account balance is ‘fairly stated’ (does not contain intolerable or material error).
- The approach is the same as attribute sampling of amounts, and is inherently more straightforward than interim control tests.
- Substantive tests estimate the error rate in an account balance with some confidence (e.g., 95%) that the estimate is within the ‘materiality’ or ‘intolerable error’ cutoff for that account balance
- For example, consider sampling sales invoices from the accounts receivable aging report and comparing them to supporting documentation to see if they were billed in the correct amounts, to the correct customers, and on the correct dates.
- Additionally, auditors might trace invoices to shipping log, and match invoice dates to the shipment dates for those items in the shipping log, to see if sales are being recorded in the correct accounting period.
- This can include an examination of invoices issued after the period being audited, to see if they should have been included in a prior period.
- Acceptance sampling size is determined using Cohen’s power analysis which is implemented in R’s pwr package, If discovery sampling suggests that a particular transaction stream is out of control, then attribute estimation will help us decide on the actual error rate of the systems that process this transaction stream.
- Errors estimates from attribute samples may either be rates of erroneous transactions or from a monetary unit sampling perspective, can be rates of monetary error in the transaction stream.
We compute both in the following code chunk
コード
size <- 100000 # 取引の総額
mu <- 50 # 取引の平均値
Delta <- 0.05 * mu # 5%の金額の許容誤差を検出
sigma <- 30 # 変動
effect <- Delta / sigma # 許容度÷変動
sample <- pwr.t.test( # Cohenのpower analysis
d = effect, # Cohenのd
sig.level = 0.05, # 有意水準
power = 0.8, # 効果量
type = "one.sample", # 一標本検定
alternative = "greater" # 偽陽性
)
cat("\n Attribute sample size for amount of error = ", ceiling(sample$n))
Attribute sample size for amount of error = 892Notable Audit Failures and Why They Occurred
- Audit and accounting practice have been strongly influenced by a string of scandals that have occurred nearly every 7 years since the Reagan reforms of the early 1980s.
- The medical, legal and accounting professions were opened up to free-market forces when all three professions were allowed direct-to-consumer marketing and brand-building.
- Rules regarding pricing and competition for talent were also relaxed.
- In auditing the repeal of AICPA Ethics Rules Section 501 on advertising, recruiting from other firms and other free-market innovations moved the industry from its cossetted clubby culture to a profit-oriented business. − By the late 1990s audit firms were averaging $7 of IT revenue for every $1 of audit revenue.
- The year 2001 witnessed a series of financial frauds involving Enron Corporation auditing firm Arthur Andersen, the telecommunications company WorldCom, Qwest, and Sunbeam among other well-known corporations.
- These problems highlighted the need to review the effectiveness of accounting standards, auditing regulations and corporate governance principles.
- In some cases, management manipulated the figures shown in financial reports to indicate a better economic performance.
- In others, tax and regulatory incentives encouraged over-leveraging of companies and decisions to bear extraordinary and unjustified risk.
- The Enron scandal deeply influenced the development of new regulations to improve the reliability of financial reporting and increased public awareness about the importance of having accounting standards that show the financial reality of companies and the objectivity and independence of auditing firms.
- In addition to being the largest bankruptcy reorganization in American history, the Enron scandal undoubtedly is the biggest audit failure. The scandal caused the dissolution of Arthur Andersen which at the time was one of the five largest accounting firms in the world.
- One consequence of these events was the passage of the Sarbanes–Oxley Act in 2002.
Auditing: A Wicked Problem
Wicked Problem
- In theory, independent audits increase the value and credibility of the financial statements, reduce investor risk, and reduce the cost of capital of audited firms.
- They are often required under securities law and by investors and creditors.
- But such assertions have grown increasingly contentious over time as the definitions and usage of financial statements have evolved and changed.
- Scholars are increasingly aware that many of auditing’s difficulties reflect its status as a wicked problem.
- Wicked problems are difficult or impossible to solve because of incomplete, contradictory and changing requirements that are often difficult to recognize.
- The term wicked is used not in the sense of evil but rather its resistance to resolution.
- Moreover because of complex interdependencies, the effort to solve one aspect of a wicked problem may reveal or create other problems.
- Contrast this with relatively tame soluble problems in mathematics, chess or puzzle solving (Coyne 2005; Ludwig 2001; Rittel and Webber 1973).
Wicked Problems
- Audits are classic wicked problems sharing the following characteristics (Rittel and Webber 1973):
- There is no definitive formulation of auditing.
- Audits have no stopping rule.
- Audit products are not true-or-false rather are opinions.
- There is no immediate and no ultimate test of an audit conclusion.
- Each audit is a one-shot operation.
- Audits do not have an enumerable or an exhaustively describable set of potential solutions nor is there a well-described set of permissible operations that may be incorporated into the audit program.
- Every audit is essentially unique.
- Every audit procedure can be considered to be a response to some other finding.
- The existence of an audit discrepancy can be explained in numerous ways. The choice of explanation determines the nature of the problems resolution and the audit opinion.
- The auditor has no right to be wrong and is ultimately liable for the consequences of audit opinions.
- The solution depends on how the problem is framed and vice versa, i.e., the problem definition depends on the solution.
- Stakeholders have radically different world views and different frames for understanding the problem.
- The constraints that the problem is subject to and the resources needed to solve it change over time.
Competitive Strategies
- Roberts (2002) and Roberts (2000) identified three strategies to address wicked problems: competitive, authoritative and collaborative.
- Competitive strategies attempt to solve wicked problems by pitting opposing points of view against each other requiring parties that hold these views to come up with their preferred solutions.
- The advantage of this approach is that different solutions can be weighed up against each other and the best one chosen.
- The disadvantage is that this adversarial approach creates a confrontational environment in which knowledge sharing is discouraged.
Collaborative Strategies
- Collaborative strategies try to engage all stakeholders in order to find the best possible solution for all stakeholders.
- Typically these approaches involve meetings in which issues and ideas are discussed and a common agreed approach is formulated.
- Such approaches share many of the disadvantages of competitive approaches and can be even more time consuming.
Authoritative Strategies
- Authoritative strategies concentrate responsibility for solving the problems in the hands of a few people, for example Certified Public Accountants.
- The reduction in the number of stakeholders reduces problem complexity as many competing points of view are eliminated at the start.
- The disadvantage is that authorities and experts charged with solving the problem lack all of the information needed to efficiently and completely solve the problem.
Auditing as a Wicked Problem
Auditing for better or worse has chosen to couch the industrial organization of the audit business in an authoritarian structure.
Authority for rendering audit opinions is vested in a small number of firms; the Fortune 500 firms must typically be audited by one of the Big Four audit firms;
Audits authoritative strategy for solving its wicked problem offers the advantage of substantially reduced cost and greater efficiency of audits.
Its disadvantage is that no matter how well educated the auditors are they will not have as much information about IT storage and processing platforms.
Final Thoughts on Planning and Budgets
- Planning and budgeting of audits is not an exact science, rather it is contextual, with uncertain outcomes, incomplete and asymmetric information, and ongoing negotiations with the client and between audit offices.
- The judgment and experience of auditors, managers, and the profession are essential to a complete and effective planning process.
- Since audit planning will often be highly collaborative, involving professionals in different offices around the world, computational tools to aid in standardizing and objectifying procedures across languages and cultures can be expected to improve efficiency and effectiveness of auditing.
![]()
Kobe University, Business Administration